深度学习(二)BERT模型及其一系列衍生模型
文章目录
- 声明
-
- 一、BERT 概述
-
- 1. BERT 是什么?
- 2. 传统方法 VS 预训练方法
- 3. BERT 的输入
-
- ① 5 种特殊的 token
- 4. 核心结构
-
- 1. Multi-Head
- 2. Encoder
- 4. 预训练方式
-
- 1.MLM(Masked Language Model) 任务
- 2.Next Sentence Predict :句与句的关系
- 3.Multi-Task Learning
- 5.BERT 的输出?
- 6. Fine-Tuning
-
- ① case 1 Classification
- ② case 2 Slot filling
- ③ case 3 Infer
- ④ case 5 QA
- 7. Fine tune BERT 来解决新的下游任务有 5 个简单步骤
- 8. BERT 有什么局限性?
- 9. BERT 优点
- 10. BERT 与 Transformer 的区别
- 二、BERT 改进版本
-
- 1. ELMo
- 2. GPT
- 3. Ernie-baidu
- 4. Ernie - Tsingha
- 5. GPT2
- 6. UNILM
- 7. Transformer-XL & XLNet
-
- 1.循环机制来解决
- 2.将Transformer 中的绝对位置编码改为相对位置编码
- 3. 训练方式的改进
-
- AR 语言模型 auto regressive language model
- AE 语言模型 auto encoding language model
- AR 语言模型与 AE 语言模型融合
- 8. Roberta
- 9. SpanBert
-
- SBO 任务
- Mask 片段长度采样分布
- 10. ALBERT
- 11. T5(Text-to-Text Transfer Transformer)
- 12. GPT3
- 三、浅谈预训练的发展方向
- Reference
声明
本文仅供本人形成系统的知识体系,不供商用!!!
内容来自各大平台大佬讲解,已将其在最后 reference 部分引入,如有侵权,可删!
温馨提示:想要读懂本章内容,需提前了解 Transformer 哦:Transformer 详解
一、BERT 概述
1. BERT 是什么?
~~~~ Bert 是 2018 年由 Google 推出了,整体是一个自编码语言模型(Autoencoder LM),即一个预训练的语言表征模型。它强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的 masked language model(MLM),以致能生成深度的双向语言表征。BERT 论文发表时提及在 11 个NLP(Natural Language Processing,自然语言处理)任务中获得了新的 state-of-the-art 的结果

基本原理: 设计了两个任务来预训练该模型:MLM 任务以及 Next Sentence Predict 任务,得到一个对语言有一定理解的通用模型,再将该模型利用 fine-tune 处理下游任务。下面这个示意图最重要的概念是预训练步骤跟 fine-tuning 步骤所用的 BERT 是一模一样的

2. 传统方法 VS 预训练方法
传统方法: 1.收集数据集 2.模型搭建 3.模型训练 4.预测评估
预训练:
1.如 CNN 中部分模型被别人训练后,具备很强的图片特征提取能力,当我们数据集很少时,只需要改动后层输出以适用于自己的网络即可。
2.在自然语言处理中适用被人的模型,当输入我们自己的语言是,自动输出句子的表征,如 Google 的BERT,在输入一句话,输出矩阵表示这句话,其中融合了多方面信息。
Bert 的两大主要作用:Pre-train、Fine-tune
3. BERT 的输入

- Token Embedding:WordPiece tokenization subword 词向量。单词字典是采用WordPiece 算法来进行构建的,将本来的 words 拆成更小粒度的 wordpieces。
~~~~~~~~~~~ 以词 fragment 来说,其可以被拆成 frag 与 ##ment 两个 pieces。
- Segment Embedding:表明这个词属于哪个句子(NSP需要两个句子)用 [0,1] 来表示。
~~~~~~~~~~~ [CLS] 我的狗很可爱 [SEP] 企鹅不擅长飞行 [SEP]
~~~~~~~~~~~~~~ 0 ~~~~~ 0 0 0 ~ 0 0 0 ~~~ 0 ~~~~ 1 ~ 1 1 ~ 1 1 ~ 1 1 ~~ 1
-
Position Embedding:学习出来的 embedding 向量。这与Transformer不同,Transformer中是预先设定好的值。
-
注:输入的每一个序列开头都插入特定的分类 token([CLS]),该分类 token 对应的最后一个 Transformer 层输出被用来起到聚集整个序列表征信息的作用。上述三种词嵌入加和后会做 Layer Normalization
① 5 种特殊的 token
[CLS]:在做分类任务时其最后一层的 repr. 会被视为整个输入序列的 repr.
[SEP]:有两个句子的文本会被串接成一个输入序列,并在两句之间插入这个 token 以做区隔
[UNK]:没出现在 BERT 字典里头的字会被这个 token 取代
[PAD]:zero padding 遮罩,将长度不一的输入序列补齐方便做 batch 运算
[MASK]:未知遮罩,仅在预训练阶段会用到
4. 核心结构
1. Multi-Head

2. Encoder

4. 预训练方式
Bert 主要的两个任务:

1.MLM(Masked Language Model) 任务
这是能让前面的Transformer模型能进行双向训练的一个重要支撑任务。可以看成是LM的另一种训练方式。
思路: 随机mask掉一句话中的某个词,然后让模型同时结合左边和右边的上下文,来预测这个词,其实有点儿像是完形填空。之后做 Loss 的时候也只计算被遮盖部分的
Label : 遮挡位置的真实词
my dog is hairy → my dog is [MASK ]
~~~~ 此处将 hairy 进行了mask处理,然后采用非监督学习的方法预测mask位置的词是什么,但是该方法有一个问题,因为是mask15%的词,其数量已经很高了,这样就会导致某些词在fine-tuning阶段从未见过,为了解决这个问题,作者做了如下的处理:
- 80%的时间是采用[mask],my dog is hairy → my dog is [MASK]
- 10%的时间是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple
- 10%的时间保持不变,my dog is hairy -> my dog is hairy
为啥要以一定的概率使用随机词呢?
~~~~ 因为 transformer 要保持对每个输入 token 分布式的表征,否则Transformer很可能会记住这个[MASK]就是"hairy"。至于使用随机词带来的负面影响,文章中解释说,所有其他的token(即非"hairy"的token)共享15%*10% = 1.5%的概率,其影响是可以忽略不计的。
2.Next Sentence Predict :句与句的关系
这是为了下游需要输入句子对,并分辨句子对之间联系的任务而设计的,比如 QA、NLI 等。作者认为 LM 里面学不到这样的知识,所以又单独设计了NSP预训练任务。
思路: 预测两个句子中,后面一句是不是前面一句的下一句,是一个二分类问题。在构造输入的时候,以50%的概率选择真实是下一句的句子,以50%的概率选择不是真实下一句的句子。我们首先拿到属于上下文的一对句子,也就是两个句子,之后我们要在这两个句子中加一些特殊的 token:[CLS]上一句话[SEP]下一句话[SEP]。 也就是在句子开头加一个[CLS],在两句话之间和句末加[SEP],具体地如下图所示:

3.Multi-Task Learning
BERT 预训练阶段实际上是将上述两个任务结合起来,同时进行,然后将所有的 Loss 相加:
Input:
[CLS] calculus is a branch of math [SEP] panda is native to [MASK] central china [SEP]
Targets: false, south
----------------------------------
Input:
[CLS] calculus is a [MASK] of math [SEP] it [MASK] developed by newton and leibniz [SEP]
Targets: true, branch, was
5.BERT 的输出?
BERT 模型的主要输入是文本中各个字/词(或者称为 token)的原始词向量,该向量既可以随机初始化,也可以利用 Word2Vector 等算法进行预训练以作为初始值;输出是文本中各个字/词融合了全文语义信息后的向量表示,如下图所示(为方便描述且与 BERT 模型的当前中文版本保持一致,统一以「字向量」作为输入):
模型输出则是输入各字对应的融合全文语义信息后的向量表示
实际上,在做 Next Sentence Prediction 任务时,在第一个句子的首部会加上一个 [CLS] token,在两个句子中间以及最后一个句子的尾部会加上一个 [SEP] token。

C 为分类 token([CLS])对应最后一个 Transformer 的输出, 则代表其他 token 对应最后一个 Transformer 的输出。对于一些 token 级别的任务(如,序列标注和问答任务),就把输入到额外的输出层中进行预测。对于一些句子级别的任务(如,自然语言推断和情感分类任务),就把 C 输入到额外的输出层中,这里也就解释了为什么要在每一个token序列前都要插入特定的分类 token。
6. Fine-Tuning
Fine-Tuning 共分为 4 中类型
① case 1 Classification
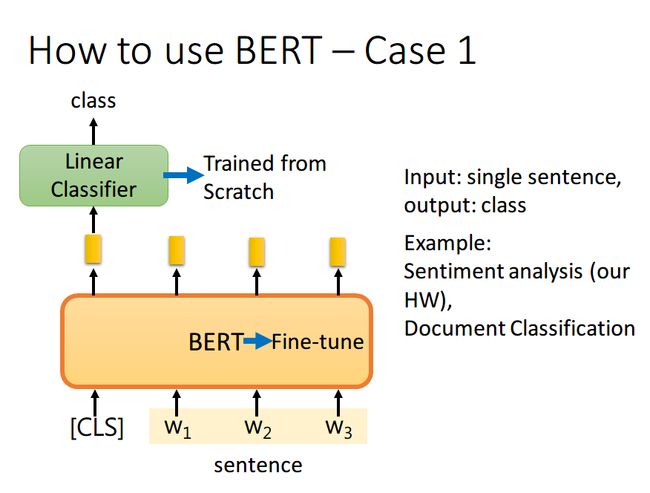
如果现在的任务是 Classification,首先在输入句子的开头加一个代表分类的符号 [CLS] ,然后将该位置的 output,丢给 Linear Classifier,让其predict 一个 Class 即可。整个过程中 Linear Classifier 的参数是需要从头开始学习的,而 BERT 中的参数微调就可以了
为什么要用第一个位置?
即 [CLS] 位置的 output。因为 BERT 内部是 Transformer,而 Transformer 内部又是 Self-Attention,所以 [CLS] 的 output 里面肯定含有整句话的完整信息,这是毋庸置疑的。但是Self-Attention向量中,自己和自己的值其实是占大头的,现在假设使用 w 1 w_1 w1 的 output 做分类,那么这个 output 中实际上会更加看重 w 1 w_1 w1,而 w 1 w_1 w1 又是一个有实际意义的字或词,这样难免会影响到最终的结果。但是 [CLS] 是没有任何实际意义的,只是一个占位符而已,所以就算 [CLS] 的 output 中自己的值占大头也无所谓。当然你也可以将所有词的 output 进行 concat,作为最终的 output
② case 2 Slot filling

如果现在的任务是 Slot Filling (将每个词分类别) ,将句子中各个字对应位置的 output 分别送入不同的 Linear,预测出该字的标签。其实这本质上还是个分类问题,只不过是对每个字都要预测一个类别。
③ case 3 Infer
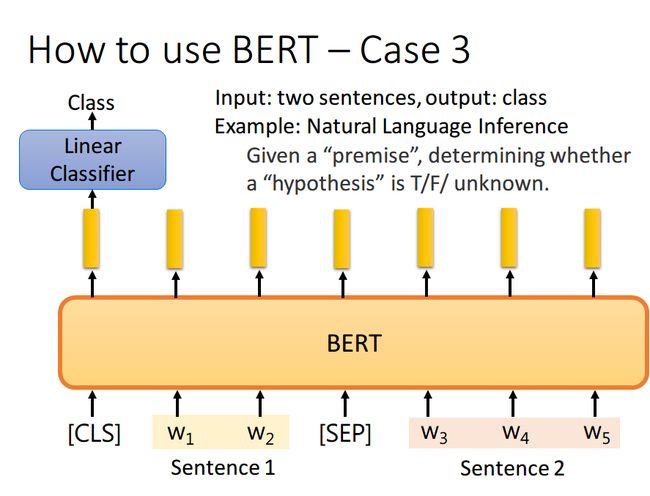
如果现在的任务是 NLI(自然语言推理)。即给定一个前提,然后给出一个假设,模型要判断出这个假设是 正确、错误还是不知道。这本质上是一个三分类的问题,和Case 1差不多,对[CLS]的output进行预测即可
④ case 5 QA

如果现在的任务是 QA(问答),举例来说,如上图,将一篇文章,和一个问题(这里的例子比较简单,答案一定会出现在文章中)送入模型中,模型会输出两个数 s,e,这两个数表示,这个问题的答案,落在文章的第 s 个词到第 e 个词。具体流程我们可以看下面这幅图

首先将问题和文章通过 [SEP] 分隔,送入 BERT 之后,得到上图中黄色的输出。此时我们还要训练两个 vector,即上图中橙色和黄色的向量。首先将橙色和所有的黄色向量进行dot product,然后通过 softmax,看哪一个输出的值最大,例如上图中 d 2 d_2 d2 对应的输出概率最大,那我们就认为 s=2

同样地,我们用蓝色的向量和所有黄色向量进行dot product,最终预测得 d 3 d_3 d3的概率最大,因此e=3。最终,答案就是s=2,e=3
你可能会觉得这里面有个问题,假设最终的输出s>e怎么办,那不就矛盾了吗?其实在某些训练集里,有的问题就是没有答案的,因此此时的预测搞不好是对的,就是没有答案
7. Fine tune BERT 来解决新的下游任务有 5 个简单步骤
- 准备原始文本数据
- 将原始文本转换成 BERT 相容的输入格式
- 在 BERT 之上加入新 layer 成下游任务模型
- 训练该下游任务模型
- 对新样本做推论
8. BERT 有什么局限性?
① BERT 在第一个预训练阶段,假设句子中多个单词被 Mask 掉,这些被 Mask 掉的单词之间没有任何关系,是条件独立的,然而有时候这些单词之间是有关系的,但是需要注意的是,这个问题并不是什么大问题,甚至可以说对最后的结果并没有多大的影响,因为本身 BERT 预训练的语料就是海量的(动辄几十个 G),所以如果训练数据足够大,其实不靠当前这个例子,靠其它例子,也能弥补被 Mask 单词直接的相互关系问题,因为总有其它例子能够学会这些单词的相互依赖关系。
② BERT 的在预训练时会出现特殊的 [MASK],但是它在下游的 fine-tune 中不会出现,这就出现了预训练阶段和 fine-tune 阶段不一致的问题。其实这个问题对最后结果产生多大的影响也是不够明确的,因为后续有许多 BERT 相关的预训练模型仍然保持了 [MASK]标记,也取得了很大的结果,而且很多数据集上的结果也比 BERT 要好。但是确确实实引入 [MASK] 标记,也是为了构造自编码语言模型而采用的一种折中方式。
③ 另外还有一个缺点,是 BERT 在分词后做 [MASK] 会产生的一个问题,为了解决 OOV 的问题,我们通常会把一个词切分成更细粒度的 WordPiece。BERT 在 Pretraining 的时候是随机 Mask 这些 WordPiece 的,这就可能出现只 Mask 一个词的一部分的情况,例如:
④ [MASK]标记在实际预测中不会出现,训练时用过多[MASK]影响模型表现;
⑤ BERT对硬件资源的消耗巨大(大模型需要16个tpu,历时四天;更大的模型需要64个tpu,历时四天。
~~~~~~~~ probability 这个词被切分成”pro”、”#babi” 和 ”#lity”3 个 WordPiece。有可能出现的一种随机 Mask 是把 ”#babi” Mask 住,但 是”pro” 和 ”#lity” 没有被 Mask。这样的预测任务就变得容易了,因为在 ”pro” 和 ”#lity” 之间基本上只能是 ”#babi” 了。这样它只需要记住一些词 (WordPiece 的序列) 就可以完成这个任务,而不是根据上下文的语义关系来预测出来的。类似的中文的词 ”模型” 也可能被 Mask 部分(其实用”琵琶”的例子可能更好,因为这两个字只能一起出现而不能单独出现),这也会让预测变得容易。
~~~~~~~~ 为了解决这个问题,很自然的想法就是词作为一个整体要么都 Mask 要么都不 Mask,这就是所谓的 Whole Word Masking。这是一个很简单的想法,对于 BERT 的代码修改也非常少,只是修改一些 Mask 的那段代码。
9. BERT 优点
-
Transformer Encoder 因为有 Self-attention 机制,因此 BERT 自带双向功能
-
为了获取比词更高级别的句子级别的语义表征,BERT 加入了Next Sentence Prediction 来和 Masked-LM 一起做联合训练
-
为了适配多任务下的迁移学习,BERT设计了更通用的输入层和输出层
-
微调成本小
-
证明了MLM预训练强于单向(LTR left to right)
-
相比词向量,BERT的文本表示结合了语境
-
Transformer模型结构有很强的拟合能力,词与词之间的距离不会造成关系计算上的损失
-
通过预训练利用了海量无标注文本数据
10. BERT 与 Transformer 的区别
Bert 中的 Transform 和 传统的 Transform 激活函数不一样,前馈用的一维卷积代替线性层,Transformer 输出是一个新的序列, Bert 只是输出一种表示,一个矩阵
二、BERT 改进版本
1. ELMo
早于BERT,强调了context embedding 的重要性,使用 LSTM 作为核心编码器

意识到了双向信息的重要性,同时使用前向和后向的语言模型,将隐含层拼接起来,优化目标是计算前向和后向的损失和,本质上仍然是单向
2. GPT
早于BERT,启用了 Transformer 作为核心编码器,开始使用特有 token 连接不同句子,用传统语言模型的方式训练,即前 n 个字预测第 n + 1 个子字,不像 Bert 的完型填空,但在此基础上增加了有监督任务训练,预训练上基本没用 LSTM 了,但是在下游任务中还是在用。
贡献: 基本上实锤了 Transformer 优于LSTM
3. Ernie-baidu
将 Bert 中Mask 随机 token, 改为了 Mask 随机实体或词组
比如 我要去哈尔滨, BERT mask 掉 哈 , 而 Erinie Mask 掉 哈尔滨
贡献: 中文上强于BERT,但是未知语言,如西班牙语等,可能无法使用该策略

4. Ernie - Tsingha
1.引入知识图谱,将实体信息融合到预训练任务中,使用了自己训练的知识图谱实体 Embedding (清华拥有自己的实体标注数据集,有这个资本)
2.下游 fine-tune 修改
对于不同实体分类和关系分类引入了两种token来加强模型对实体信息的认知

贡献:强调了额外知识的重要性,但是Ernie本身其实缩小了encoder主体模型,还缩短了训练句长,最终并没有很惊艳的效果,只在图谱挖掘相关的任务上有提升。而且这种方法对额外知识的依赖很难满足。可以看做他们对自己图谱工作的一种延伸
5. GPT2
继 GPT 后,继续使用单向语言模型,对 transformer 进行了小改动,强调 zero-shot ,任何一个任务,可以看做输入条件下的输出。
下图中翻译任务为例:

6. UNILM
使用 BERT 的模型结构,同时进行 Mask LM,单向 LM,和 seq2seq 训练 (作者认为只是用 Mask LM 太受限,引入传统单向方式 + seq2seq 训练)
贡献: 使得预训练后模型可以更好的应用在生成式任务上,如机器翻译和机器摘要等,解决了原生BERT在生成式任务上的短板
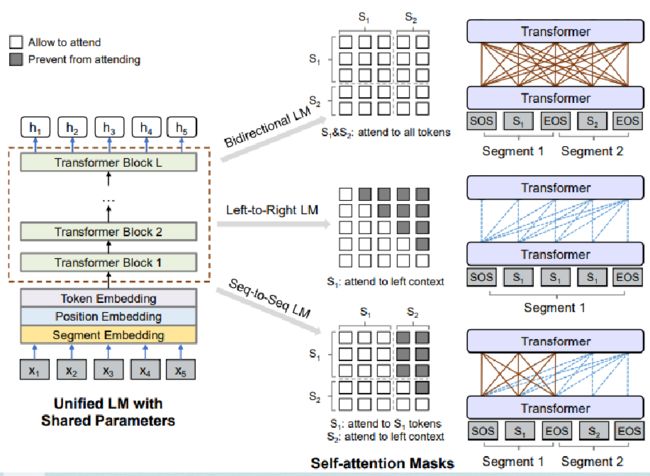
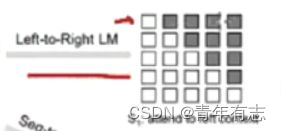
这样的结构会导致比如第一个字只能看到自己,第二个字只能看到自己与前一个字,以此类推,传统的单向语言模型,
序列序列中, S1 看做输入,S2,看做输出,输入的时候S1可以看到所有,输出的部分,s2中前面看不到后面,后面能看到前面,S1双写,S2单向,整体输入,一个一个输出

具体做法就是在注意力机制中的 QK 那部分 + MASK 矩阵遮掉一部分。

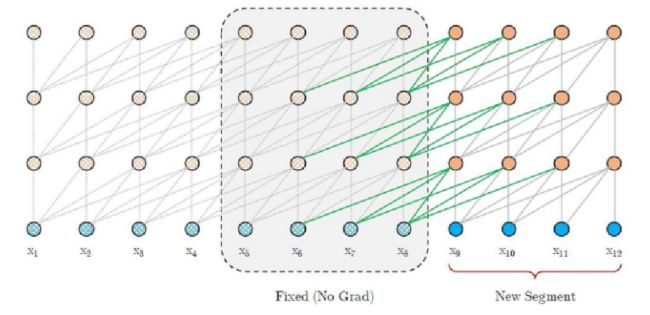
7. Transformer-XL & XLNet
原 BERT 中的问题:Bert 中有一个交互矩阵,就是那个 Mask, 和输入长度相关,如果输入长度很长,这个矩阵就会很大,所以 Bert 对长度有限制 512。
此模型希望解决 Transforme r的长度限制问题
1.循环机制来解决
其实就是将前 512 个输出传到下一层,和 RNN 的机制很像,将隐单元向量不断向后传递,将前一段文本的隐向量与后一段文本印象里拼接之后计算 attention
2.将Transformer 中的绝对位置编码改为相对位置编码
公式中其实就是将位置编码与常规词嵌入那部分叠加的写出来,然后做一个分配率,
改用相对位置编码

3. 训练方式的改进
AR 语言模型 auto regressive language model
单向预测下一个字
缺点: 缺少双向信息

AE 语言模型 auto encoding language model
双向信息输入,预测中间某个mask的字
缺点:引入了[mask],但实际任务中不不存在

AR 语言模型与 AE 语言模型融合
调整句子顺序,之后进行单向预测,它调整为了将句子顺序打乱,做单向预测实际上 embedding 的时候还是引入了位置信息,只是看起来位置变了,还是通过 mask 的操作。词向量本身是没有变的

贡献: 修改训练目标,同时修改模型结构,带来效果提升
8. Roberta
相较于 BERT 模型结构不变,训练方式调整:
- 更多的数据,更大的batch size,更久的训练
- 去掉next sentence prediction
- 使用更长的样本
- 动态改变mask位置
反思: 挖掘旧的方法的潜力,有时比创新还要有效
9. SpanBert
与BERT的主要区别有三个:
- 去掉了 NSP 任务
- 随机mask几个连续的 token
- 新的预训练任务 SBO(Span Boundary Objective)
完型填空任务的一种延伸,Mask 字采样

SBO 任务

Mask 片段长度采样分布

贡献: 1. Mask指定实体或名词短语,效果不如mask随机片段。 2. NSP作用不大,不如不加,不如SBO。 3. 大模型+更多的数据不是唯一出路,改变训练目标也有很大影响
10. ALBERT
① 试图解决Bert模型过大的问题,想办法减少参数量:
- Embedding层的因式分解
- 跨层参数共享:① 只共享 attention 部分 ② 只共享 feed-forward 部分 ③ 全部共享
② 论文认为NSP任务过于简单,用 SOP(Sentence order prediction)任务替代 NSP 任务,预测两句话的前后关系,同样是二分类任务,如:
~~~~~~~~~~~ [CLS] 你好啊 BERT [SEP] 好久不见 [SEP] -> Positive
~~~~~~~~~~~ [CLS] 好久不见 [SEP]你好啊 BERT [SEP] -> Negative
③ 局限性
- 虽然目的在于缩减参数,但依然是越大越好
- 虽然缩减了参数,但是前向计算速度没有提升(训练速度有提升)前向计算没减少是因为参数少了,但是层数没少,该多少矩阵运行还是多少。
贡献: 工程角度讲价值不大,但是证明了参数量并非模型能力的绝对衡量标准
11. T5(Text-to-Text Transfer Transformer)
① Seq2seq 理论上可以解决一切 NLP 问题:
- 分类问题:文本 -> 标签
- 命名实体识别:文本 -> 实体
- 摘要、翻译:文本 -> 文本
- 回归问题:文本 -> 0.1(字符串)
② 预训练任务设计 text corruption

Google 利用强大的资本,把任何一种 NLP 任务都在 T5 上训练了一遍,下图看不清是我的本意,知道就行。

贡献: 迈向 NLP 的大一统
12. GPT3
1750 亿参数量,是GPT-2的116倍、模型结构与GPT-2相同、继续使用单向语言模型预训练
不用 Pre-training + fine-tune 而是直接预测,理由:
- fine-tune需要的数据,经常是缺失的
- fine-tune会涉及对模型进行改造,使其变复杂,并失去泛化性
- 人类学习做新任务并不需要很多样本
人工智能的目标:像人一样的学习能力
三、浅谈预训练的发展方向
- more data, bigger model
- different pre-training tasks
- easier to transfer to all kinds of downstream tasks
- no need for task specific data
Reference
1. BERT详解(附带ELMo、GPT介绍)
2. 進擊的 BERT:NLP 界的巨人之力與遷移學習 强推 ☆☆☆
3. BERT模型的详细介绍