sklearn and keras 文本向量化
总结一下文本向量化
文本分析是机器学习算法的一个主要应用领域。然而,原始数据的这些符号序列不能直接提供给算法进行训练,因为大多数算法期望的是固定大小的数字特征向量,而不是可变长度的原始文本。
为了解决这个问题,scikit-learn提供了从文本内容中提取数字特征的常见方法,即:
- tokenizing: 标记字符串并为每个可能的token提供整数id,例如使用空白和标点作为token分隔符;(分词标记)
- counting: 统计每个文档中出现的token次数;(统计词频)
- normalizing: 通过减少大多数样本/文档中都会出现的一般性标记来进行标准化和加权。(标准化/归一化)
1、词袋模型(Bow,Bag of Words)
是文本向量化的一个模型,这种模型不考虑语法、词的顺序,只考虑所有的词的出现频率,简单说,就是分好的词放到一个袋子中,每个词都是独立的。
(1)sklearn的普通实现
from sklearn.feature_extraction.text import CountVectorizer
# 文档集
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
# 实例化
vectorizer = CountVectorizer()
# 根据文档集进行分词提取特征
X = vectorizer.fit_transform(corpus)
# 获取到相应分词的结果,也就是特征
vectorizer.get_feature_names()
# 展示向量化的矩阵
X.toarray()
# 生成一个分析器
analyze = vectorizer.build_analyzer()
# column的index
vectorizer.vocabulary_.get('document')
# 对于一些未见过的词将会被忽视,向量化为0
>>> vectorizer.transform(['Something completely new.']).toarray()
array([[0, 0, 0, 0, 0, 0, 0, 0, 0]]...)
# 对于一个文本的单词一摸一样的话,向量也是一样的,所以就需要保留单词顺序的一些东西
bigram_vectorizer = CountVectorizer(ngram_range=(1, 2),
token_pattern=r'\b\w+\b', min_df=1)
(2)中文的分词实现jieba
# 中文
corpus_zh = [
'我喜欢吃苹果',
'你喜欢吃橘子'
]
import jieba
# 默认使用英文的分词结果,或者一些
corpus_zh_out = [' '.join(jieba.cut(s, cut_all=False)) for s in corpus_zh]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus_zh_out)
vectorizer.get_feature_names()
X.toarray()
(3)CountVectorizer参数分析,实现了稀疏的表示
class sklearn.feature_extraction.text.CountVectorizer(*, input='content', encoding='utf-8', decode_error='strict', strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, stop_words=None, token_pattern='(?u)\b\w\w+\b', ngram_range=(1, 1), analyzer='word', max_df=1.0, min_df=1, max_features=None, vocabulary=None, binary=False, dtype=)
几个有用的分析:
analyzer :{‘word’, ‘char’, ‘char_wb’} or callable, default=’word’
分词级别,是‘word’(至少两个字母),还是‘char’按字符来。
**stop_words **{‘english’}, list, default=None;
停用词可以是English,输入一个list,默认没有
token_pattern:str, default=r”(?u)\b\w\w+\b”
这里r开头代表字符串里的每一个字符代表原始含义,没有转义。后面是正则表达式。只在analyzer是word的时候使用。两个\w代表匹配两个及以上的字符。
这里的正则表达式有个(?u)是给正则函数传递,意思是依赖于Unicode字符属性数据库的序列,如果您希望将标志作为正则表达式的一部分包含在内,而不是将标志参数传递给re.compile()函数,那么这非常有用
ngram_range:tuple (min_n, max_n), default=(1, 1)
n-gram的范围,保留哪些元组,一般(1,2),就是1到2的意思
max_df:float in range [0.0, 1.0] or int, default=1.0
忽略一些高于指定阈值的词汇,一般是停用词。
min_df:float in range [0.0, 1.0] or int, default=1
忽略一些高于指定阈值的词汇,一般是停用词。
max_features:int, default=None
根据词频筛选一些top-k的特征
binary:bool, default=False
如果是true,所有的非的数设置成1
dtype:type, default=np.int64
Type of the matrix returned by fit_transform() or transform().
在此方案中,特征和样本定义如下:
每个独立token出现的频率(已标准化或未标准化)作为特征。给定文档的所有token频率的向量作为多元样本。
因此,文本语料库可以由矩阵表示,每一行代表一个文本,每一列代表一个token(例如一个单词)。
向量化:将文本集合转换为数字特征向量的一般过程。
这种方法(tokenizing,counting和normalizing)称为“词袋”或“n-gram”模型。 即只通过单词频率来描述文档,而完全忽略文档中单词的相对位置信息。
什么是系数表示?
由于大多数文本通常只使用语料库中的很小一部分单词,因此生成的矩阵将具有许多为零的特征值(通常超过99%)。
例如,有一个文本集合,包含一万个文本(邮件等),它使用的词汇表大约为十万个词,而其中每个文档单独使用的词只有100到1000个。
为了能够将这样的矩阵存储在内存中并且加快矩阵/向量的代数运算,实现上通常会使用稀疏表示,在scipy.sparse包中有实现方法。
什么是停用词?
停用词是指诸如“and”,“the”,“him”之类的词,它们被认为在表示文本内容方面没有提供任何信息,可以将其删除以避免其影响预测效果。但是,有时候,类似的单词对于预测很有用,例如在对写作风格或语言个性进行分类时。
请谨慎选择停用词列表。 通用的停用词列表也可能包含对某些特定任务(例如计算机领域)非常有用的词。
此外,还应该确保停用词列表的预处理和标记化与Vectorizer中使用的预处理和标记化相同。
CountVectorizer的默认标记器将单词"we’ve"分为we和ve,因此,如果“we’ve”在stop_words中,而ve则没有,则在转换后的文本中会保留ve。
我们的Vectorizer将尝试识别并警告某些不一致之处。
2、TF-IDF概述
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与文本挖掘的常用加权技术。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
在大型文本语料库中,会经常出现一些单词(例如英语中的“ the”,“ a”,“ is”),而这些单词几乎不包含关于文档实际内容的有意义的信息。
如果我们将直接计数数据不加处理地提供给分类器,那么那些高频词会影响低频但更有意义的词的出现概率。
为了将计数特征重新加权为适合分类器使用的浮点值,通常使用tf–idf变换。
尽管tf–idf归一化通常非常有用,但是在某些情况下,二进制频率标记法可能会提供更好的特性。 这可以通过使用CountVectorizer的二进制参数来实现。
特别是,某些估计量(例如Bernoulli Naive Bayes)明确地对离散的布尔型随机变量建模。 同样,很短的文本可能带有tf–idf值的噪声,而二进制出现信息则更稳定。
通常,调整特征提取参数的最佳方法是使用交叉验证的网格搜索,例如用分类器将特征提取器进行流水线化。
(1)TF
TF: Term Frequency, 用于衡量一个词在一个文件中的出现频率。因为每个文档的长度的差别可以很大,因而一个词在某个文档中出现的次数可能远远大于另一个文档,所以词频通常就是一个词出现的次数除以文档的总长度,相当于是做了一次归一化。
TF(t) = (词t在文档中出现的总次数) / (文档的词总数).
(2)IDF
IDF: 逆向文件频率,用于衡量一个词的重要性。计算词频TF的时候,所有的词语都被当做一样重要的,但是某些词,比如”is”, “of”, “that”很可能出现很多很多次,但是可能根本并不重要,因此我们需要减轻在多个文档中都频繁出现的词的权重。
ID(t) = log(总文档数/词t出现的文档数)
TF-IDF = TF * IDF
(3)代码实现
在scikit-learn中,有两种方法进行TF-IDF的预处理。
CountVectorizer:只考虑词汇在文本中出现的频率
TfidfVectorizer:除了考量某词汇在文本出现的频率,还关注包含这个词汇的所有文本的数量,能够削减高频没有意义的词汇出现带来的影响, 挖掘更有意义的特征
第一种方法是在用CountVectorizer类向量化之后再调用TfidfTransformer类进行预处理。
- CountVectorizer
CountVectorizer和TfidfTransformer搭配计算TF-IDF
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
corpus=["I come to China to travel",
"This is a car polupar in China",
"I love tea and Apple ",
"The work is to write some papers in science"]
vectorizer=CountVectorizer()
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
print (tfidf)
- TfidfVectorizer
第二种方法是直接用TfidfVectorizer完成向量化与TF-IDF预处理。
sklearn.feature_extraction.text.TfidfVectorizer可以把一大堆文档转换成TF-IDF特征的矩阵。
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf2 = TfidfVectorizer()
re = tfidf2.fit_transform(corpus)
print(re)
# 导入TfidfVectorizer
In [2]: from sklearn.feature_extraction.text import TfidfVectorizer
# 实例化tf实例
In [3]: tv = TfidfVectorizer(use_idf=True, smooth_idf=True, norm=None)
# 输入训练集矩阵,每行表示一个文本
In [4]: train = ["Chinese Beijing Chinese",
...: "Chinese Chinese Shanghai",
...: "Chinese Macao",
...: "Tokyo Japan Chinese"]
...:
# 训练,构建词汇表以及词项idf值,并将输入文本列表转成VSM矩阵形式
In [6]: tv_fit = tv.fit_transform(train)
# 查看一下构建的词汇表
In [10]: tv.get_feature_names()
Out[10]: ['beijing', 'chinese', 'japan', 'macao', 'shanghai', 'tokyo']
# 查看输入文本列表的VSM矩阵
In [8]: tv_fit.toarray()
Out[8]:
array([[1.91629073, 2. , 0. , 0. , 0. , 0. ],
[0. , 2. , 0. , 0. , 1.91629073, 0. ],
[0. , 1. , 0. , 1.91629073, 0. , 0. ],
[0. , 1. , 1.91629073, 0. , 0. , 1.91629073]])
小结
TF-IDF是非常常用的文本挖掘预处理基本步骤,但是如果预处理中使用了Hash Trick,则一般就无法使用TF-IDF了,因为Hash Trick后我们已经无法得到哈希后的各特征的IDF的值。使用了TF-IDF并标准化以后,我们就可以使用各个文本的词特征向量作为文本的特征,进行分类或者聚类分析。当然TF-IDF不光可以用于文本挖掘,在信息检索等很多领域都有使用。因此值得好好的理解这个方法的思想。
3、Keras的Tokenizer类
不知道为啥新版本官网给这个函数的api说明给下架了
keras.preprocessing.text.Tokenizer
(num_words=None,
filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~ ',
lower=True,
split=' ',
char_level=False,
oov_token=None,
document_count=0)
该类允许使用两种方法向量化一个文本语料库:将每个文本转化为一个整数序列(每个整数都是词典中标记的索引);或者将其转化为一个向量,其中每个标记的系数可以是二进制值、词频、TF-IDF权重等。
参数
num_words: 需要保留的最大词数,基于词频。只有最常出现的 num_words 词会被保留。
filters: 一个字符串,其中每个元素是一个将从文本中过滤掉的字符。默认值是所有标点符号,加上制表符和换行符,减去 ’ 字符。
lower: 布尔值。是否将文本转换为小写。
split: 字符串。按该字符串切割文本。
char_level: 如果为 True,则每个字符都将被视为标记。
oov_token: 如果给出,它将被添加到 word_index 中,并用于在 text_to_sequence 调用期间替换词汇表外的单词。
默认情况下,删除所有标点符号,将文本转换为空格分隔的单词序列(单词可能包含 ’ 字符)。这些序列然后被分割成标记列表。然后它们将被索引或向量化。0 是不会被分配给任何单词的保留索引。

还有以下的方法:
- fit_on_texts(texts):
基于文本集texts构建词汇表。在调用texts_to_sequences或texts_to_matrix方法之前,必须先调用该方法构建词汇表。
-
texts_to_sequences(texts)
将文本集中的每篇文本变换为词语索引序列。注意:只有属于词汇表中前num_words的词才被索引替换,其他词直接忽略。词索引列表构成的文本集列表。
-
texts_to_sequences_generator(texts)
本函数是texts_to_sequences的生成器函数版
texts:待转为序列的文本列表
返回值:每次调用返回对应于一段输入文本的序列
例子如下:
from tensorflow.keras.preprocessing.text import Tokenizer
import sys
sentences = ["I love dog",
"I love cat"]
tokenizer = Tokenizer(num_words=100)
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print("word_index: ", word_index)
seq_normal = tokenizer.texts_to_sequences(sentences) # 没用生成器
print("seq_normal: ", seq_normal)
seq = tokenizer.texts_to_sequences_generator(sentences) # 用了生成器
print("seq_generator:", end=" ")
while True:
try:
print(next(seq), end=" ")
# next() 返回迭代器的下一个项目。
# next() 函数要和生成迭代器的 iter() 函数一起使用。
except StopIteration:
sys.exit()
>>> word_index: {'i': 1, 'love': 2, 'dog': 3, 'cat': 4}
>>> seq_normal: [[1, 2, 3], [1, 2, 4]]
>>> seq_generator: [1, 2, 3] [1, 2, 4]
4、keras的pad_sequences类
keras.preprocessing.sequence.pad_sequences(
sequences, maxlen=None, dtype='int32', padding='pre', truncating='pre', value=0.0)
参数
sequences: 列表的列表,每一个元素是一个序列。
maxlen: 整数,所有序列的最大长度。
dtype: 输出序列的类型。 要使用可变长度字符串填充序列,可以使用 object。
padding: 字符串,‘pre’ 或 ‘post’ ,在序列的前端补齐还是在后端补齐。
truncating: 字符串,‘pre’ 或 ‘post’ ,移除长度大于 maxlen 的序列的值,要么在序列前端截断,要么在后端。
value: 浮点数,表示用来补齐的值。
返回
- x: Numpy 矩阵,尺寸为 (len(sequences), maxlen)。
将多个序列截断或补齐为相同长度。
该函数将一个 num_samples 的序列(整数列表)转化为一个 2D Numpy 矩阵,其尺寸为 (num_samples, num_timesteps)。 num_timesteps 要么是给定的 maxlen 参数,要么是最长序列的长度。
比 num_timesteps 短的序列将在末端以 value 值补齐。
比 num_timesteps 长的序列将会被截断以满足所需要的长度。补齐或截断发生的位置分别由参数 pading 和 truncating 决定。
向前补齐为默认操作。
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
sentences = ["I love dog",
"I love cat",
"I really love tigers",
"I love rabbits since they are cute"]
tokenizer = Tokenizer(num_words=100)
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print("word_index: ", word_index)
seq_normal = tokenizer.texts_to_sequences(sentences)
padded1 = pad_sequences(seq_normal, maxlen=max([len(sentence.split(" ")) for sentence in sentences]))
print("padded1:\n", padded1)
padded2 = pad_sequences(seq_normal, maxlen=max([len(sentence.split(" ")) for sentence in sentences]), padding='post', value=101)
print("padded2:\n", padded2)
padded3 = pad_sequences(seq_normal, maxlen=5, truncating='post')
print("padded3:\n", padded3)
>>> word_index: {'i': 1, 'love': 2, 'dog': 3, 'cat': 4, 'really': 5, 'tigers': 6, 'rabbits': 7, 'since': 8, 'they': 9, 'are': 10, 'cute': 11}
>>> padded1:
[[ 0 0 0 0 1 2 3]
[ 0 0 0 0 1 2 4]
[ 0 0 0 1 5 2 6]
[ 1 2 7 8 9 10 11]]
>>>padded2:
[[ 1 2 3 101 101 101 101]
[ 1 2 4 101 101 101 101]
[ 1 5 2 6 101 101 101]
[ 1 2 7 8 9 10 11]]
>>>padded3:
[[0 0 1 2 3]
[0 0 1 2 4]
[0 1 5 2 6]
[1 2 7 8 9]]
5、keras的hashing_trick
hashing_trick将文本转换为固定大小散列空间中的索引序列。
keras.preprocessing.text.hashing_trick(text, n,
hash_function=None,
filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~ ', lower=True,
split=' ')
参数
text: 输入文本(字符串)。
n: 散列空间维度。
hash_function: 默认为 python 散列函数,可以是 ‘md5’ 或任意接受输入字符串并返回整数的函数。注意 ‘hash’ 不是稳定的散列函数,所以它在不同的运行中不一致,而 ‘md5’ 是一个稳定的散列函数。
filters: 要过滤的字符列表(或连接),如标点符号。默认:!"#$%&()*+,-./:;<=>?@[]^_{|}~,包含基本标点符号,制表符和换行符。
lower: 布尔值。是否将文本转换为小写。
split: 字符串。按该字符串切割文本。
返回值:整数词索引列表(唯一性无法保证)。
0 是不会被分配给任何单词的保留索引。由于哈希函数可能发生冲突,可能会将两个或更多字分配给同一索引。 碰撞的概率与散列空间的维度和不同对象的数量有关。

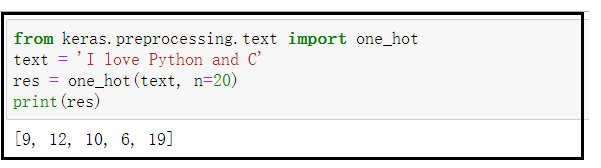
6、keras的one_hot
One-hot将文本编码为大小为 n 的单词索引列表。这是 hashing_trick函数的一个封装, 使用 hash 作为散列函数;单词索引映射无保证唯一性。
keras.preprocessing.text.one_hot(text, n,
filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~',
lower=True,
split=' ')
参数
text: 输入文本(字符串)。
n: 整数。词汇表尺寸。
filters: 要过滤的字符列表(或连接),如标点符号。默认:!"#$%&()*+,-./:;<=>?@[]^_{|}~,包含基本标点符号,制表符和换行符。
lower: 布尔值。是否将文本转换为小写。
split: 字符串。按该字符串切割文本。
返回值
[1, n] 之间的整数列表。每个整数编码一个词(唯一性无法保证)。
7、keras的text_to_word_sequence
text_to_word_sequence将文本转换为单词(或标记)的序列。
keras.preprocessing.text.text_to_word_sequence(text, filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~ ', lower=True,
split=' ')
参数:
text: 输入文本(字符串)。
filters: 要过滤的字符列表(或连接),如标点符号。默认:!"#$%&()*+,-./:;<=>?@[]^_{|}~,包含基本标点符号,制表符和换行符。
lower: 布尔值。是否将文本转换为小写。
split: 字符串。按该字符串切割文本。
返回值
词或标记的列表。

问题步骤
参考自:链接
文本向量化的一般步骤是word to vector:
字符串->分词->词汇序列化->词汇向量化
1、字符串文本的序列化
在word embedding的时候,不会直接把文本转化为向量,而是先转化为数字,再把数字转化为向量,那么这个过程该如何实现呢?
这里我们可以考虑把文本中的每个词语和其对应的数字,使用字典保存,同时实现方法把句子通过字典映射为包含数字的列表。
实现文本序列化之前,考虑以下几点:
- 如何使用字典把词语和数字进行对应
- 不同的词语出现的次数不尽相同,是否需要对高频或者低频词语进行过滤,以及总的词语数量是否需要进行限制
- 得到词典之后,如何把句子转化为数字序列,如何把数字序列转化为句子
- 不同句子长度不相同,每个batch的句子如何构造成相同的长度(可以对短句子进行填充,填充特殊字符)
- 对于新出现的词语在词典中没有出现怎么办(可以使用特殊字符代理)
思路分析:
- 对所有句子进行分词
- 词语存入字典,根据次数对词语进行过滤,并统计次数
- 实现文本转数字序列的方法
- 实现数字序列转文本方法
文本序列化功能类WordSequence的构建实现
import numpy as np
import pickle
# =======================================文本序列化:开始=======================================
class WordSequence:
UNK_TAG = "" # 表示未在词典库里出现的未知词汇
PAD_TAG = "" # 句子长度不够时的填充符
SOS_TAG = "" # 表示一句文本的开始
EOS_TAG = "" # 表示一句文本的结束
UNK = 0
PAD = 1
SOS = 2
EOS = 3
def __init__(self):
self.word_index_dict = {
self.UNK_TAG: self.UNK,
self.PAD_TAG: self.PAD,
self.SOS_TAG: self.SOS,
self.EOS_TAG: self.EOS} # 初始化词语-数字映射字典
self.index_word_dict = {} # 初始化数字-词语映射字典
self.word_count_dict = {} # 初始化词语-词频统计字典
self.fited = False
def __len__(self):
return len(self.word_index_dict)
# 接受句子,统计词频得到
def fit(self,sentence,min_count=1,max_count=None,max_features=None): # 【min_count:最小词频; max_count: 最大词频; max_features: 最大词语数(词典容量大小)】
"""
:param sentence:[word1,word2,word3]
:param min_count: 最小出现的次数
:param max_count: 最大出现的次数
:param max_feature: 总词语的最大数量
:return:
"""
for word in sentence:
self.word_count_dict[word] = self.word_count_dict.get(word,0) + 1 #所有的句子fit之后,self.word_count_dict就有了所有词语的词频
if min_count is not None: # 根据条件统计词频
self.word_count_dict = {word:count for word,count in self.word_count_dict.items() if count >= min_count}
if max_count is not None:# 根据条件统计词频
self.word_count_dict = {word:count for word,count in self.word_count_dict.items() if count <= max_count} # 根据条件构造词典
if max_features is not None: # 根据条件保留高词频词语
self.word_count_dict = dict(sorted(self.word_count_dict.items(),key=lambda x:x[-1],reverse=True)[:max_features]) # 保留词频排名靠前的词汇【self.word_count_dict.items()为待排序的对象,key表示排序指标,reverse=True表示降序排列】
for word in self.word_count_dict: # 根据word_count_dict字典构造词语-数字映射字典
if word not in self.word_index_dict.keys(): # 如果当前词语word还没有添加到word_index_dict字典,则添加
self.word_index_dict[word] = len(self.word_index_dict) # 每次word对应一个数字【使用self.word_index_dict添加当前word前已有词汇的数量作为其value】
self.fited = True
self.index_word_dict = dict(zip(self.word_index_dict.values(),self.word_index_dict.keys())) #把word_index_dict进行翻转【准备一个index->word的字典】
# word -> index
def to_index(self,word):
assert self.fited == True,"必须先进行fit操作"
return self.word_index_dict.get(word,self.UNK)
# 把句子转化为数字数组(向量)【输入:[str,str,str];输出:[int,int,int]】
def transform(self,sentence,max_len=None,add_eos=False):
if len(sentence) > max_len: # 句子过长,截取句子
if add_eos: # 如果每句文本需要添加结束标记
sentence = sentence[:max_len-1] + [self.EOS]
else:
sentence = sentence[:max_len]
else: # 句子过短,填充句子
if add_eos: # 如果每句文本需要添加结束标记
sentence = sentence + [self.EOS] + [self.PAD_TAG] *(max_len - len(sentence) - 1)
else:
sentence = sentence + [self.PAD_TAG] *(max_len - len(sentence))
index_sequence = [self.to_index(word) for word in sentence]
return index_sequence
# index -> word
def to_word(self,index):
assert self.fited , "必须先进行fit操作"
if index in self.inversed_dict:
return self.inversed_dict[index]
return self.UNK_TAG
# 把数字数组(向量)转化为句子【输入:[int,int,int];输出:[str,str,str]】
def inverse_transform(self,indexes):
sentence = [self.index_word_dict.get(index,"" ) for index in indexes]
return sentence
# =======================================文本序列化:结束=======================================
if __name__ == '__main__':
sentences = [["今天","天气","很","好"],["今天","去","吃","什么"]]
ws = WordSequence()
for sentence in sentences:
ws.fit(sentence)
print("ws.word_index_dict = {0}".format(ws.word_index_dict))
print("ws.fited = {0}".format(ws.fited))
pickle.dump(ws, open("./models/ws.pkl", "wb")) # 保存文本序列化对象
ws = pickle.load(open("./models/ws.pkl", "rb")) # 加载文本序列化对象
index_sequence = ws.transform(["今天","很","热"],max_len=10)
print("index_sequence = {0}".format(index_sequence))
2、“序列化后的字符串文本” 进行向量化
因为文本不能够直接被模型计算,所以需要将其转化为向量。
将一段文本使用张量进行表示,其中一般将词汇为表示成向量,称作词向量,再由各个词向量按顺序组成矩阵形成文本表示.
文本张量表示的作用:将文本表示成张量(矩阵)形式,能够使语言文本可以作为计算机处理程序的输入,进行接下来一系列的解析工作。
文本张量表示的方法:
- one-hot编码
- Word Embedding
one-hot编码的优劣势:
- 优势:操作简单,容易理解.
- 劣势:完全割裂了词与词之间的联系,而且在大语料集下,每个向量的长度过大,占据大量内存.
正因为one-hot编码明显的劣势,这种编码方式被应用的地方越来越少,取而代之的是稠密向量的表示方法word embedding
word embedding是深度学习中表示文本常用的一种方法。和one-hot编码不同,word embedding使用了浮点型的稠密矩阵来表示token。根据词典的大小,我们的向量通常使用不同的维度,例如100,256,300等。其中向量中的每一个值是一个参数,其初始值是随机生成的,之后会在训练的过程中进行学习而获得。
如果我们文本中有20000个词语,如果使用one-hot编码,那么我们会有2000020000的矩阵,其中大多数的位置都为0,但是如果我们使用word embedding来表示的话,只需要20000 维度,比如20000*300
我们会把所有的文本转化为向量,把句子用向量来表示
但是在这中间,我们会先把token使用数字来表示,再把数字使用向量来表示。
即:token---> num ---->vector
3、如何理解Embedding
Embedding,将离散变量转变为连续向量的方式为神经网络在各方面的应用带来了极大的扩展。在神经网络中,embedding 是非常有用的,因为它不光可以减少离散变量的空间维数,同时还可以有意义的表示该变量。
我们可以总结一下,embedding 有以下 3 个主要目的:
- 在 embedding 空间中查找最近邻,这可以很好的用于根据用户的兴趣来进行推荐。
- 作为监督性学习任务的输入。
- 用于可视化不同离散变量之间的关系。
one-hot缺点:
- 对于具有非常多类型的类别变量,变换后的向量维数过于巨大,且过于稀疏。
- 映射之间完全独立,并不能表示出不同类别之间的关系。
因此,考虑到这两个问题,表示类别变量的理想解决方案则是我们是否可以通过较少的维度表示出每个类别,并且还可以一定的表现出不同类别变量之间的关系,这也就是 embedding 出现的目的。
而为了更好的表示类别实体,我们还可以是用一个 embedding neural network 和 supervised 任务来进行学习训练,以找到最适合的表示以及挖掘其内在联系。
One-hot 编码的最大问题在于其转换不依赖于任何的内在关系,而通过一个监督性学习任务的网络,我们可以通过优化网络的参数和权重来减少 loss 以改善我们的 embedding 表示,loss 越小,则表示最终的向量表示中,越相关的类别,它们的表示越相近。
上面给出维基百科的例子中,可能有这样的一个 supervised 任务,“预测这本书是否是 Leo Tolstoy 写的”,而我们最终产生的 embedding 则会让 Tolstory 写的书之间的表示更接近。因此弄清楚如何创建监督学习任务和产生相关表示是 embedding 表示的关键。
我们可以定义维基百科上所有书籍为原始 37,000 维,使用 neural network embedding 将它们映射到 50 维,然后使用 TSNE 将它们映射到 2 维,其结果如下:
Embedding 可视化
Embedding 最酷的一个地方在于它们可以用来可视化出表示的数据的相关性,当然要我们能够观察,需要通过降维技术来达到 2 维或 3 维。最流行的降维技术是:t-Distributed Stochastic Neighbor Embedding (TSNE)。或着使用PCA向量处理降维到2维或者3维。
这样看好像并不能看出什么,但是如果我们根据不同书籍的特征着色,我们将可以很明显的看出结果。

我们可以清楚地看到属于同一类型的书籍的分组。虽然它并不完美,但惊奇的是,我们只用 2 个数字就代表维基百科上的所有书籍,而在这些数字中仍能捕捉到不同类型之间的差异。这代表着 embedding 的价值。
这里主要看一下keras的embedding层是怎么用的
keras embedding
keras.layers.Embedding(input_dim, output_dim, embeddings_initializer='uniform', embeddings_regularizer=None, activity_regularizer=None, embeddings_constraint=None, mask_zero=False, input_length=None)
将正整数(索引值)转换为固定尺寸的稠密向量。 例如: [[4], [20]] -> [[0.25, 0.1], [0.6, -0.2]],该层只能用作模型中的第一层。
参数
- input_dim: int > 0。词汇表大小, 即,最大整数 index + 1。
- output_dim: int >= 0。词向量的维度。
- embeddings_initializer:
embeddings矩阵的初始化方法 (详见 initializers)。 - embeddings_regularizer:
embeddingsmatrix 的正则化方法 (详见 regularizer)。 - embeddings_constraint:
embeddingsmatrix 的约束函数 (详见 constraints)。 - mask_zero: 是否把 0 看作为一个应该被遮蔽的特殊的 “padding” 值。 这对于可变长的 循环神经网络层 十分有用。 如果设定为
True,那么接下来的所有层都必须支持 masking,否则就会抛出异常。 如果 mask_zero 为True,作为结果,索引 0 就不能被用于词汇表中 (input_dim 应该与 vocabulary + 1 大小相同)。 - input_length: 输入序列的长度,当它是固定的时。 如果你需要连接
Flatten和Dense层,则这个参数是必须的 (没有它,dense 层的输出尺寸就无法计算)。
4、To do BERT and Transformer and Attention
见下一篇文章吧