【论文笔记】An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ViT)

题目:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
作者:谷歌大脑团队(Dosovitskiy, A., Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, M. Dehghani, Matthias Minderer, Georg Heigold, S. Gelly, Jakob Uszkoreit and N. Houlsby)
来源:ICLR 2021(国际表征学习会议) 被CCF 评选为一类会议
原文:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
代码:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
摘要
虽然 Transformer 架构已成为自然语言处理任务的事实上的标准,但其在计算机视觉中的应用仍然有限。 在视觉中,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构到位。 我们表明这种对 CNN 的依赖是不必要的,直接应用于图像块序列的纯变换器可以在图像分类任务上表现得非常好。 当在大量数据上进行预训练并转移到多个中小型图像识别基准(ImageNet、CIFAR-100、VTAB 等)时,视觉变换器 (ViT) 与最先进的相比取得了出色的结果- 艺术卷积网络,同时需要大量更少的计算资源来训练。
介绍
基于自我注意的架构,尤其是 Transformer(V aswani 等,2017),已成为自然语言处理 (NLP) 的首选模型。 主要方法是在大型文本语料库上进行预训练,然后在较小的特定任务数据集上进行微调(Devlin 等,2019)。 由于 Transformers 的计算效率和可扩展性,训练具有超过 100B 个参数的前所未有的模型成为可能(Brown 等人,2020 年;Lepikhin 等人,2020 年)。 随着模型和数据集的增长,仍然没有表现出饱和的迹象。
然而,在计算机视觉中,卷积架构仍然占主导地位(LeCun 等人,1989 年;Krizhevsky 等人,2012 年;He 等人,2016 年)。 受 NLP 成功的启发,多项工作尝试将类 CNN 架构与自注意力相结合(Wang 等人,2018 年;Carion 等人,2020 年),一些工作完全取代了卷积(Ramachandran 等人,2019 年;Wang 等人2020 年)。 , 2020a)。 后一种模型虽然理论上有效,但由于使用了专门的注意力模式,还没有在现代硬件加速器上有效地扩展。 因此,在大规模图像识别中,经典的类 ResNet 架构仍然是最先进的(Mahajan 等,2018;Xie 等,2020;Kolesnikov 等,2020)。
受到 nlp 中变压器缩放成功的启发,我们尝试将一个标准的变压器直接应用到图像中,以最少的可能的修改。为此,我们将一个图像分割成片,并提供这些片的线性嵌入序列作为转换器的输入。图像补丁与 nlp 应用程序中的标记(单词)处理方式相同。我们训练模型的图像分类监督的方式。
大致思路简洁的说:
引文
CV领域被CNN占据,NLP领域Transformer成为标配,近几年Transformer跨界迁移到CV领域的文章也有很多,大多基于两个思路:
(1)注意力机制与CNN结合;
(2)在整体结构不变的情况下注意力机制替换CNN某些结构;
But,这些特殊的注意力机制无法实现硬件层面加速,所以本文讲述的是在不依赖CNN结构的情况下,如何尽可能地讲NLP领域的标配——Transformer不做修改的迁移到CV领域。
思路
- 预处理
a.把图像(H,W,C)三维数据切片为“词向量”(num_token, token_dim);
b.添加位置编码Position Embedding,使得注意力Attention权重更容易观察到图像中的物体,帮助模型正确评估注意力权重;
c.添加一个专门用于分类的的[class]Token,因为该Token没有予以信息,可以能好的反映图像表征;
- 特征提取
a.对输入Patches进行LN标准化处理,用于加快网络收敛;
b.MSA(多头注意力机制),类似CNN中使用多个滤波器,有助于网络捕捉更丰富特征;
c.MLP(多层感知器),全连接+GELU激活函数+Dropout;
d.残差连接,防止梯度消失;
- 分类
提取[class]Token生成的结果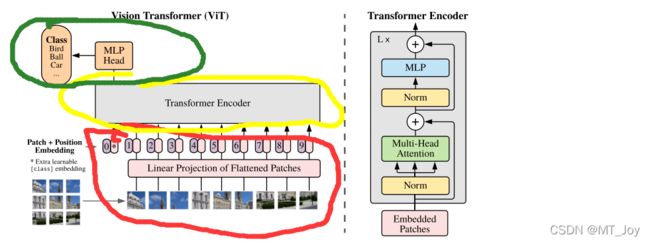
红色部分:预处理
黄色部分:特征提取
绿色部分:分类
实验(EXPERIMENTS)
评估了ResNet、Vision Transformer (ViT)和hybrid的学习能力。为了了解每个模型的数据需求,对不同大小的数据集进行了预训练,并评估了许多基准任务。在考虑模型预训练的计算成本时,ViT表现得非常好,以较低的预训练成本在大多数识别基准上达到了最先进的水平。
5.1 setup
数据集(datasets):各种大小的数据集以及测试基准。
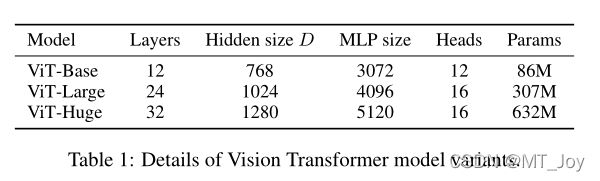
模型变体(Model Variants):基于BERT配置VIT,各种大小的VIT(base,large,huge),patch的大小P也是可调的,P越大,序列长度越小。P越小,长度越长,计算开销越大。
结论:
我们已经探索了 Transformers 在图像识别中的直接应用。与在计算机视觉中使用自注意力的先前工作不同,除了初始补丁提取步骤之外,我们不会将特定于图像的归纳偏差引入架构。相反,我们将图像解释为一系列补丁,并通过 NLP 中使用的标准 Transformer 编码器对其进行处理。这种简单但可扩展的策略与大型数据集的预训练结合使用时效果出奇地好。因此,Vision Transformer 在许多图像分类数据集上匹配或超过了最先进的技术,同时预训练相对便宜。
虽然这些初步结果令人鼓舞,但仍然存在许多挑战。一种是将 ViT 应用于其他计算机视觉任务,例如检测和分割。我们的结果,加上 Carion 等人的结果。 (2020),表明这种方法的前景。另一个挑战是继续探索自我监督的预训练方法。我们最初的实验表明自监督预训练的改进,但自监督和大规模 sup 之间仍然存在很大差距
总结
- 1.在超大数据集预训练后,归功于谷歌的钞能力和实验能力,实验结果很好。

- 2.未来还有不少任务,transformer应用于检测和分割领域;
- 3.继续降低训练时间和数据集大小,扩大模型的适用范围;