【论文阅读】An Image is Worth 16x16 Words:Transformers for Image Recognition at Scale
前言
- 博客主页:睡晚不猿序程
- ⌚首发时间:2022.9.2
- ⏰最近更新时间:2022.9.2
- 本文由 睡晚不猿序程 原创,首发于 CSDN
- 作者是蒻蒟本蒟,如果文章里有任何错误或者表述不清,请 tt 我,万分感谢!orz
文章目录
- 前言
-
- @[toc]
- 1. 内容简介
- 2. 摘要浏览
- 3. 图片、表格浏览
- 4. 引言浏览
- 自由阅读
- 5. 方法
-
- 5.1 Vision Transformer
- 5.2 微调以及高分辨率
- 6. 总结、预告
-
- 6.1 总结
- 6.2 预告
文章目录
- 前言
-
- @[toc]
- 1. 内容简介
- 2. 摘要浏览
- 3. 图片、表格浏览
- 4. 引言浏览
- 自由阅读
- 5. 方法
-
- 5.1 Vision Transformer
- 5.2 微调以及高分辨率
- 6. 总结、预告
-
- 6.1 总结
- 6.2 预告
1. 内容简介
论文标题:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
作者:Alexey Dosovitskiy,Lucas Beyer,等
发布于:arXiv 2020
自己认为的关键词:Transformer,图像识别
2. 摘要浏览
解决的问题:Transformer 在 NLP 任务上已经成为了标准,但是在 CV 任务上仍然有局限。该论文展现了纯 Tr 可以直接应用在一系列的 image patch 上,并且在图像分类任务上表现良好
主要贡献:原本注意力机制一般会和 CNN 一起使用,或者是用作 CNN 中的一个模块,而本论文将纯 Transformer 应用到了 CV 的图像分类任务
架构:Transformer
完成效果:在大规模的图片上进行预训练之后,然后再转移到中等规模的小数据集进行识别可以达到一个非常不错的准确率,并且训练所需要的计算资源资源更少
3. 图片、表格浏览
图一

整个模型的架构,可以看到直接使用了一个 Tr 的编码器来进行处理。
描述一下整个处理过程,首先他先将图片拆开成为固定大小的 patch,然后经过一个线性变换层将其变换成一个个的图向量(自创名词,可以这样说吧)。然后进行位置嵌入,同时连接上一个额外的可学习的 class token ,其大小和图向量的大小相同。最后直接送入 Tr Encoder 进行处理,然后使用分类向量作为分类依据,只需要连接上一个 MLP 头就可以了
表一

作者编写了三个不同大小的 ViT,其层数,隐藏状态大小,MLP 的大小以及头数都不同,所以参数数量也不同
表二

和目前的 SOTA 方法进行对比,其中 ViT 在 JFT-300M 数据集上进行了预训练,我们可以看到 ViT 全面超越了基于 ResNet 的方法,而且需要的计算资源远远小于基于 ResNet 的方法(2.5k day vs 9.9k day)。并且在小数据集上进行预训练的 ViT 效果也非常好
图二

VTAB:谷歌提出的视觉领域任务自适应基准,也就是某种评价指标
从这张图可以看到 ViT 在 VTAB 的各个子任务上都表现良好
图三、图四

图三(左):在 ImageNet 上进行预训练并迁移,可以看出效果比 BiT 差,然后在更大的数据集上进行预训练,可以看出 ViT 模型的正确率开始提升。
图四(右):
fewshot:小样本学习?这里应该是小样本分析
我们可以看到,随着训练集大小的增加, ResNet 的指标也在增加,但是比起 ViT,他非常平缓。而 ViT 指标的增加看起来还在保持
图五

展现了模型的效果以及其预训练时所需的计算复杂度,可以看到在差不多效果的情况下,ViT 的计算复杂度比 ResNet 的复杂度要好很多,在小的数据集上我们可以看到融合模型会优于 ViT,但是当数据集增大的时候,二者的差距并不大
图六

注意力机制的可视化,可以看到注意力机制还是有点用的
图七
 ’左:ViT-L/32 的前几个线性映射层的 RGB 可视化
’左:ViT-L/32 的前几个线性映射层的 RGB 可视化
中:ViT-L/32 位置嵌入的相似度,每一块展示了他对应的行和列的 patch 的相似度,可以看到还是有点用的
右:随着网络的深入注意力所能注意到的区域,每个点表示注意力跨越的距离。可以看到随着网络的深入,注意力可以看到的内容越来越多
4. 引言浏览
基于自注意力机制的架构已经在自然语言处理领域成为了首选,大部分采取的方法为:先在大的文本数据集上进行预训练,然后在小的子任务上进行微调。
在视觉任务上,CNN 仍然占据主导地位,有人用了尝试组合类 CNN 架构,并为其加上自注意力机制,或是彻底移除卷积。这些最新的模型理论上高效,但是因为使用了特殊的注意力机制,没能在现代硬件上高效应用。所以在大规模的图像识别任务上,传统的 ResNet 架构仍然是 SOTA 的
作者直接把标准的 Tr 应用到了图像上,并尽可能少的改动。做法大概是:
- 把图像划分为一个个的 patch(也就是划成小块)
- 对这些 patch 进行线性嵌入(linear embedding)
- 将经过变换的 patch 作为输入喂入 Tr
这些 image patch 被当作是 tokens 来进行处理,和 NLP 一样。作者采用全监督的方式来训练这个图像分类器
实验结果
在中等规模的数据集上(如 ImageNet),没有很强的正则化的情况下,模型的正确率一般,比同规模的 ResNet
低了一点。这是可以预料到的,因为他缺少了一些 CNN 独有的归纳偏置,如平移不变性,所以在小数据集上表现不是太好
但是换上大的训练数据集,情况就不一样了,大的训练数据所带来的提升超越了归纳偏置,ViT 在大量的图像识别基准上达到了 SOTA
自由阅读
5. 方法
作者尽可能的根据原始的 Transformer 来进行设计
5.1 Vision Transformer

上面展示了网络的结构,可以看到直接使用了 Tr 的编码器,基本没有变化。把图像拆分成了多个 16x16 大小的小图像,然后经过线性变化,当成是 token 输入到 Tr 中去,很巧妙
一个标准的 Tr 接受一个 1D 的 token,但是图像是 2D 的,所以需要进行处理,作者把图像 x ∈ R H × W × C x \in \mathbb R^{H\times W\times C} x∈RH×W×C 转化为了很多个 2D patches x p ∈ R N × P 2 ⋅ C x_p \in \mathbb R^{N\times P^2 \cdot C} xp∈RN×P2⋅C ,其中(H,W)是源图像的分辨率,(P,P)是每一个图像 patch 的分辨率,并且 N = H W / P 2 N=HW/P^2 N=HW/P2 。这些 patches 同时作为 Tr 的有效输入,Tr 有固定输入向量维度 D,所以我们要把这些图像展平,并且映射到一个 D 维的向量中,这个映射是可学习的,我们把这个映射称为 patch embedding
为了执行分类任务,作者增加了一个可学习的 embedding到经过了嵌入的 patches 的前面,这个向量经过了 Tr 的输出状态将会图像的表示。不管是在预训练话还是在微调,分类头都只作用在这个向量上。这个分类头在预训练的时候由拥有一个隐层的 MLP 实现,微调的时候使用一个线性层实现
和 Tr 相同,使用位置嵌入来保持位置信息。作者采用了可学习的 1D 位置嵌入,因为使用 2D 位置嵌入似乎没有更大的提升
Tr 的每一个块都包含有多头自注意力(MSA)和 MLP 块,并且使用 LayerNorm 来进行归一化并且在每一个块中都使用残差连接
MLP 使用了 GELU(高斯误差线性单元)
GELU
函数表达式:受到了 Dropout、ReLU 等机制的影响,希望将神经网络中不重要的激活信息设置为0。
也就是说,对于输入的值,会乘上一个伯努利分布 Bernoulli(Φ(x)),其中 Φ(x) = P(X ≤ x)。随着 x 的降低,它被归零的概率会提高。
这个激活函数平滑非单调,但是似乎是 NLP 领域的当前最佳,尤其在 Tr 模型上表现最好。由于其计算量大,一般采用近似式来替代原式计算

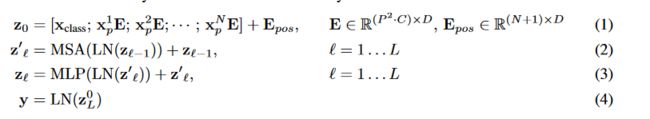
上面这些公式表示的就是整个网络的操作流程,首先有一个变换 E,把每一个图像 patch 转换成为向量,然后加上 E p o s E_{pos} Epos 进行位置嵌入,接下来就是计算多头注意力,然后进行 MLP 转换。经过了一系列上述处理,最后得到的 y 是经过了 LN 的第一个向量 z L 0 z_{L}^0 zL0
归纳偏置
相比起 CNN,Tr 所拥有的归纳偏置较少。在 CNN 中可以用用到很多的归纳偏置,例如二维邻域,变换不变性等,但是在 Tr 仅仅使用了 MLP 层。MLP 层是局部的,并且变换等价的,而自注意力是全局的。
并且二维相邻性的使用也比较吝啬:在刚开始的时候对图像进行分割并进行位置嵌入,然后接下来微调的时候在调整不同分辨率的图像的位置嵌入信息。这就表明,刚开始的时候,位置嵌入没有携带任何信息,这些信息都要网络从头学起
混合结构
和直接输入图片相似,我们也可以直接输入经过 CNN 处理的特征图。在这种情况下,用于patch embedding 的 E 直接作用于由 CNN 抽取的特征图分割得到的 patch 上。
作为一个特例,这个 patch 的大小可以是 1x1,这说明输入是直接通过简单的展平并投影到 Tr 的维度来获得的
5.2 微调以及高分辨率
作者使用 ViT 在大数据集上进行训练,并在下游任务上进行微调。所以预训练时用的分类头直接丢弃,然后接上一个零初始化的 D × K D \times K D×K 的分类头,作者说,在比预训练的数据更高的分辨率下进行微调是有益的——因为我们保持了 patch size 不变,输入更高分辨率的图像,可以让图向量数组的长度变长(一个高分辨率的图片可以分解为更多的 patch)
但是,预训练的位置嵌入可能会因此变得不再有意义,作者因此采取了一个 2D 的位置嵌入,根据图像的位置以及原图的位置来得到,注意,ViT 仅仅在这里用到了图像的 2D 结构这一归纳偏置
6. 总结、预告
6.1 总结
阅读这篇论文主要是因为 Transformer 现在已经应用非常广泛,希望之后也可以把这一结构应用到自己所研究的领域中去。所以 ViT 也算是必须要了解的
因为我主要是想要了解其架构以及处理方式,所以我们就没有继续看后面的实验以及对比部分
我自己总结一下 ViT ,首先,如果想要把图片直接丢入 Tr 中进行处理其实非常难,想象一下一张图片,假设大小为 256*256,并且是彩色图片,那么其大小就是 (3 ,256, 256),将其展平,则长度为 196,608,这已经超出了我们所能承受的长度,何况这才是一张图片。
ViT 很巧妙的避开了这个问题,他将一张图片当作是一个**“句子”**,把整个图片打散成一个一个的 “词语”(patch)。每一个 patch 大小为 16*16*3 ,如果把他展开大小为 768,完全可以接受了。
接下来的处理作者基本没有改动 Tr,基本就是把最纯粹的 Transformer 给搬过来了,首先把每一个 patch 展平,经过一个线性映射处理映射到 D 维,然后在最前面拼接上一个用于分类的 D 维向量,这个向量的输出将会作为我们进行分类的依据。接着进行位置嵌入,然后就可以送入 Tr 的 encoder 了。
得到的输出,我们取他的第一个向量,然后使用 MLP 得到分类结果。
上面就是整个 ViT 的运行过程了,其思想和存粹的 Tr 非常的相似。
6.2 预告
接下来可能要阅读 Swin Transformer 了!以前有粗浅的看了一下 Swin Transformer,但是有许多地方看不懂的,特别是他的滑动窗口,接下来要仔细看一下了