论文阅读 - An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
文章目录
-
- 1 概述
- 2 方法简述
-
- 2.1 encoder之前
- 2.2 encoder之后
- 3 实验结果
- 参考资料
1 概述
这篇论文是一篇将tranformer引入到图像领域的里程碑式的文章。因为这是第一次在处理图像时,将所有的卷积模块统统抛弃,只使用attention。并且实验证明了只用attention比使用卷积的网络在图像分类上效果要更好。
正片文章的内容并不难理解,前提熟知transformer的原理,不了解或者想要回顾一下的小伙伴,可以看我的另一篇搞懂Transformer。
而论文提出的vision transorformer就是在transformer的输入和输出上做了一些手脚,对transformer自身没有任何改动。
卷积模块在图像领域几乎已经位于不可替代的地位了,作者进行这样的尝试的原因是transformer在NLP领域取得了巨大的成功,说不定在图像领域也有奇效,并且同样的参数量下tranformer的计算效率比卷积模块更高。
经过试验之后,作者发现在训练数据量较小的情况下(如ImageNet),vision transformer的效果比resnet这样的主流卷积网络效果略差。但是当有大量的数据可以提供预训练的时候(如谷歌内部的JFT-300M),vision transformer的优势就体现出来了。在大数据集上预训练之后,再在小数据集上进行finetune,vision tranformer就比其他的主流卷积分类模型要好了。
卷积网络的计算方式有针对图像的很强的inductive bias。其一,卷积利用卷积核的方式告诉了卷积网络,每个像素点和它周围的像素点有很大的关联;其二,卷积核权重共享的机制告诉了卷积网络,图像当中的物体移动之后,仍旧是相同的物体。而这两点,vision transformer都不知道,因此它需要更多的数据来学习。
2 方法简述
vision transformer的结构并不复杂,一看图就明白了,其示意图如下图2-1所示。实在不明白的,看一下参考资料[4]或者[5]的代码就非常清楚了。
总体上可以分为两大块来看,encoder之前和encoder之后。中间的transformer encoder就不说了,就是标准的transformer,不过可以有 L L L层。当然也可把encoder换成比如BERT之类的其他的transformer。
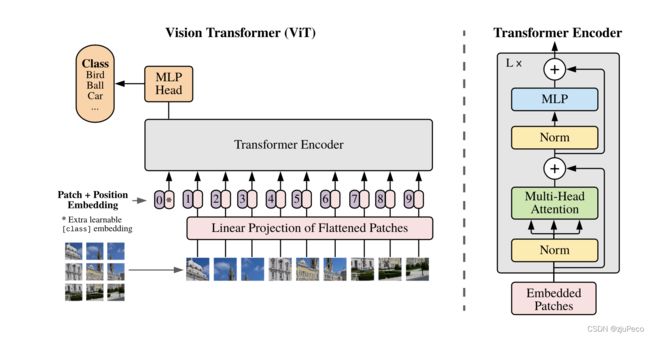
2.1 encoder之前
输入的图像会被切成一块块patches,一般代码实现当中会用patch_size来表示每一个patch的长和宽,切成patches之后,从左往右,从上往下排列成一个patches的序列,每个patch会被展开成patch_size[0] x patch_size[1]的输入,经过embedding层之后输出。此时的输出就是图2-1中transformer encoder下方1-9数字旁粉色的模块。
接着会在头部额外concat上一个特殊的特征*,这个特征的维度和patch经过embedding之后的维度一样,并且是可以被学习的。这个特征和BERT的class token很像。
同时会对所有的特征加上表示位置信息的position embedding,这个也是可以被学习的。注意是加上,而不是concat。
2.2 encoder之后
transformer encoder的每一个输入都会对应一个输出,在图像分类时,我们只需要拿第0个embedding对应的输出,过几层全连接来进行分类即可。
如此看来,这个0也就像是模型自己学出来的一个管家,它整理了所有patches的信息。
其他真的没啥了,总结起来就是前处理+后处理+超大的数据集。
3 实验结果
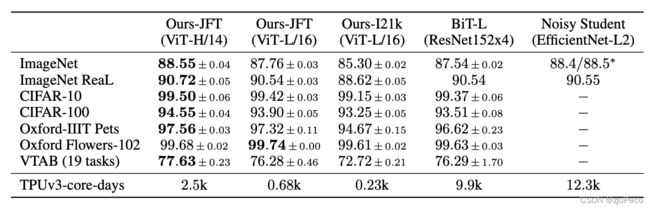
作者把vision transformer的效果和BiT进行了对比,这个也是他们自己出的一个模型。总的来说就是在各个数据集上都有更好的表现,而且训练所需要的资源也更为节省了,具体数据如下表3-1所示。
除此之外,作者还将模型学到的东西进行了可视化,其示意图如下图3-1所示。

图3-1左是图片刚输入每个patch在做embedding时,对patch进行embedding的filter学习到的权重的主成分结果图,可以看到不同的filter会关注patch的不同位置和不同纹理。
图3-1中间是每个patch在和其他patch之间的position embedding的相似程度,可以看出,position embedding的确有学出patch之间的距离。
图3-1右边是模型16个heads的attention distance的平均距离,这里可以看到,在浅层的时候,有些head就已经在看距离自身很远的patch了,这是CNN做不到的。
参考资料
[1] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
[2] Yannic Kilcher讲解vision transformer
[3] 秋刀鱼的炼丹工坊讲vision transformer
[4] https://github.com/lucidrains/vit-pytorch
[5] https://keras.io/examples/vision/image_classification_with_vision_transformer/