Deep Multimodal Representation Learning(深度多模态表示学习)
多模态表示学习旨在缩小不同模态之间的异质性差距,在利用普遍存在的多模态数据中发挥着不可或缺的作用。基于深度学习的多模态表示学习由于具有强大的多层次抽象表示能力,近年来引起了人们的广泛关注。
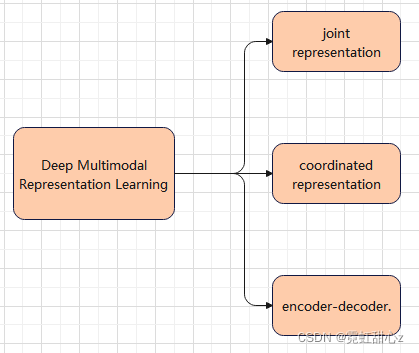
多模态融合的核心问题是异质性间隙,而为了便于讨论如何缩小异质性差距,根据不同模态集成的底层结构,我们将深度多模态表示学习方法分为三个框架:联合表示、协调表示和编解码器(如上图Fig1).
那么又为什么称为表征学习呢?为传达世界上关于物体的全面信息,描述同一物体不同方面的各种认知信号被记录在文本、图像、视频、声音和图形等不同类型的媒体中。在表示学习领域,单词“模态”指的是一种特定的编码信息的方式或机制。因此,上面列出的不同类型的媒体也指模式,涉及几种模式的表征学习任务将被描述为多模态。由于多模式数据从不同的角度描述一个对象,通常在内容上互补或补充,它们比单峰数据更提供信息。
那么如果进行多模态融合呢?
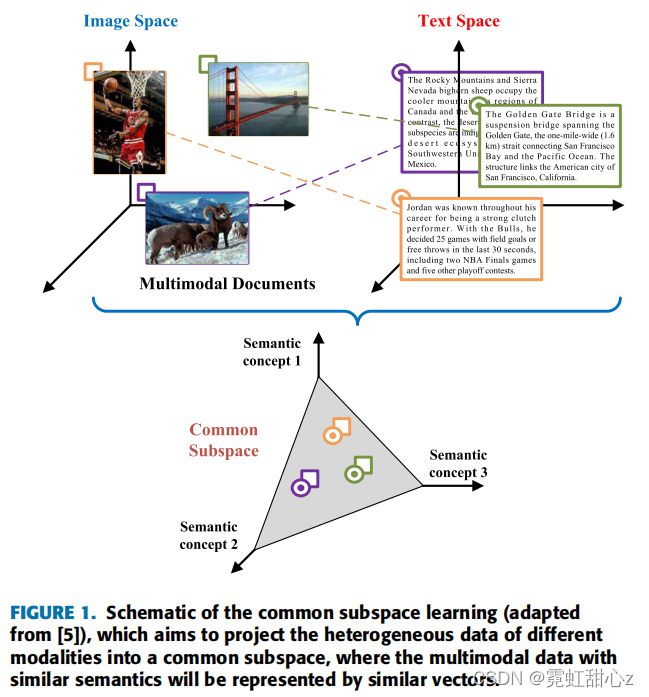
如上图所示,由于来自不同模态的特征向量最初位于不等子空间中,与相似语义相关的向量表示将是完全不同的。在这里,这种现象被称为异质性间隙,这将阻碍多模态数据被后续的机器学习模块全面利用。解决这一问题的一种流行方法是将异构特征投影到一个公共的子空间中,其中具有相似语义的多模态数据将由相似的向量表示。因此,多模态表示学习的主要目标是缩小联合语义子空间中的分布差距,同时保持模态特定语义的完整。
深度多模态表示学习框架
接下来将介绍三个模块:联合表示、协调表示、编码-解码器.
联合表示(Joint representation):其目的是将单峰表示投射到一个共享的语义子空间中,从而融合多模态特征;
协调表示(coordinated representation):包括跨模态相似度模型和规范相关分析,这是寻求学习在协调子空间中每个模态的分离但有约束的表示;
编码器-解码器(encoder-decoder models):它努力学习用于映射一种模态到另一种模态的中间表示。

上图,(a)联合表示旨在学习一个共享的语义子空间;(b)协调表示框架在某些约束下学习每个模态的分离但协调表示;(c)编码器-解码器框架将一种模式转换为另一种模式,并保持其语义一致。

融合张量的定义可以表述如下:
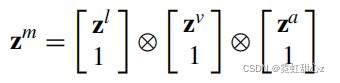
zm表示融合张量,zl、zv、za表示不同模态张量,⊗ 表示外积操作。
但是为了更有表现力,学习到的向量被期望融合互补的语义,形成不同的模式。这个互补的属性不能自动保证,因为联合表示倾向于保留跨模态的共享语义,而忽略了特定于模态的信息。此时,就有2种解决方案:添加额外正则项,;添加追踪正则。
2)COORDINATED REPRESENTATION
协调表示框架不是在联合子空间中学习表示,而是在某些约束下为每个模态学习分离但协调的表示。由于在不同模式中包含的信息是不平等的,学习分离表征有利于坚持唯一和有用的模式特异性特征。
通常约束类型的条件、协调表示方法可以分为两组:基于跨模态相似度、基于跨模态相关性。
基于跨模态相似度:学习一个公共的子空间,其中向量从不同的模式可以直接测量;
基于跨模态相关:学习一个共享的子空间,使来自不同模式的表示集的相关性使最大化。
跨模态相似度方法在相似度度量的约束下学习协调表示。该模型的学习目标是保持模态间和模态内相似结构,期望与相同语义或对象相关的跨模态相似距离尽可能最小,同时期望具有不同语义的距离尽可能最大。
3)ENCODER-DECODER
编码器-解码器框架主要由两个组件组成,一个编码器和解码器。编码器将源模态映射为潜在向量v,然后解码器基于向量v生成一个新的目标模态样本。(虽然大多数编码器-解码器模型只包含一个编码器和一个解码器,但一些变体也可以由几个编码器或解码器组成。)
广义编解码器模型的学习目标,可以表示为:
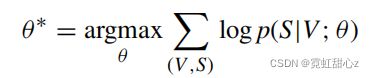
通过给定相应的视觉内容V和模型参数θ,使特征S的对数似然值最大化。
而像协调表示一样,为了更有效地捕获共享语义,一种流行的解决方案是通过一些正则化术语来保持模态之间的语义一致性。它取决于编码器和解码器之间的协调。