百度语音识别+百度ERNIE-Gram+pyaudio麦克风录音(NLP自然语言处理)
1.pyaudio安装及通过pyaudio实现录音
pip install pyaudio
在conda环境中安装没有报错

实现录音的代码如下:
# -*- coding: utf-8 -*-
from pyaudio import PyAudio, paInt16
import numpy as np
from datetime import datetime
import wave
class recoder:
NUM_SAMPLES = 2000 # pyaudio内置缓冲大小
SAMPLING_RATE = 16000 # 取样频率
LEVEL = 500 # 声音保存的阈值
COUNT_NUM = 20 # NUM_SAMPLES个取样之内出现COUNT_NUM个大于LEVEL的取样则记录声音
SAVE_LENGTH = 8 # 声音记录的最小长度:SAVE_LENGTH * NUM_SAMPLES 个取样
TIME_COUNT = 60 # 录音时间,单位s
Voice_String = []
def savewav(self,filename):
wf = wave.open(filename, 'wb')
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(self.SAMPLING_RATE)
wf.writeframes(np.array(self.Voice_String).tostring())
# wf.writeframes(self.Voice_String.decode())
wf.close()
def recoder(self):
pa = PyAudio()
stream = pa.open(format=paInt16, channels=1, rate=self.SAMPLING_RATE, input=True,
frames_per_buffer = self.NUM_SAMPLES)
save_count = 0
save_buffer = []
time_count = self.TIME_COUNT
while True:
time_count -= 1
# print time_count
# 读入NUM_SAMPLES个取样
string_audio_data = stream.read(self.NUM_SAMPLES)
# 将读入的数据转换为数组
audio_data = np.fromstring(string_audio_data, dtype=np.short)
# 计算大于LEVEL的取样的个数
large_sample_count = np.sum( audio_data > self.LEVEL )
print(np.max(audio_data))
# 如果个数大于COUNT_NUM,则至少保存SAVE_LENGTH个块
if large_sample_count > self.COUNT_NUM:
save_count = self.SAVE_LENGTH
else:
save_count -= 1
if save_count < 0:
save_count = 0
if save_count > 0:
# 将要保存的数据存放到save_buffer中
# print save_count > 0 and time_count >0
save_buffer.append(string_audio_data)
else:
# print save_buffer
# 将save_buffer中的数据写入WAV文件,WAV文件的文件名是保存的时刻
# print "debug"
if len(save_buffer) > 0:
self.Voice_String = save_buffer
save_buffer = []
print("Recode a piece of voice successfully!")
return True
if time_count==0:
if len(save_buffer)>0:
self.Voice_String = save_buffer
save_buffer = []
print("Recode a piece of voice successfully!")
return True
else:
return False
if __name__ == "__main__":
r = recoder()
r.recoder()
r.savewav("test.wav") # 储存录音文件
运行结果如下:


出现 successfully 即表示录音成功 。
2.百度语音识别
百度搜索:百度AI开放平台


点击 开放能力 短语音识别 立即使用 登陆后界面如下

点击右下方的免费领取资源,把需要使用的都领取了,然后点击创建应用
创建界面如下

随后下载SDK


我是linux的系统,就下载如上图的sdk
在应用列表里面会看到api_key和secret_key,后面会用到

打开下载的speech-demo文件夹,打开/rest-api-asr/python/asr_json.py
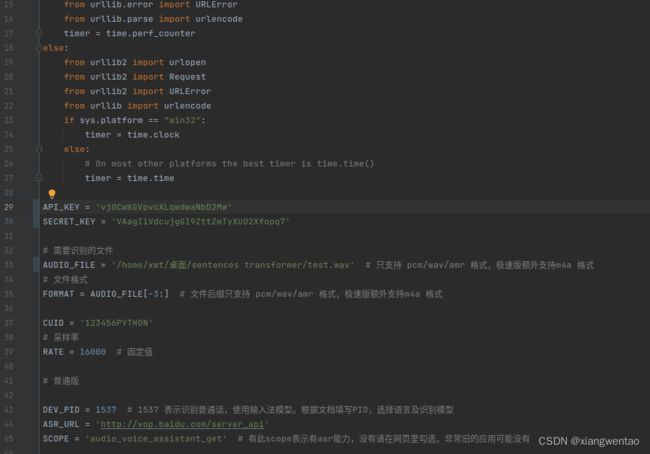
将api和secret换成刚刚申请的
将需要识别的 文件这个地方的语音文件换成步骤1生成的test.wav的路径

整段代码如下:
# coding=utf-8
import sys
import json
import base64
import time
import re
import csv
IS_PY3 = sys.version_info.major == 3
if IS_PY3:
from urllib.request import urlopen
from urllib.request import Request
from urllib.error import URLError
from urllib.parse import urlencode
timer = time.perf_counter
else:
from urllib2 import urlopen
from urllib2 import Request
from urllib2 import URLError
from urllib import urlencode
if sys.platform == "win32":
timer = time.clock
else:
# On most other platforms the best timer is time.time()
timer = time.time
API_KEY = 'vj0CwKGVpvcXLqwdwaNbD2Mw'
SECRET_KEY = 'VAagIiVdcujgGI9ZttZmTyXUO2Xfopq7'
# 需要识别的文件
AUDIO_FILE = '/home/xwt/桌面/sentences transformer/test.wav' # 只支持 pcm/wav/amr 格式,极速版额外支持m4a 格式
# 文件格式
FORMAT = AUDIO_FILE[-3:] # 文件后缀只支持 pcm/wav/amr 格式,极速版额外支持m4a 格式
CUID = '123456PYTHON'
# 采样率
RATE = 16000 # 固定值
# 普通版
DEV_PID = 1537 # 1537 表示识别普通话,使用输入法模型。根据文档填写PID,选择语言及识别模型
ASR_URL = 'http://vop.baidu.com/server_api'
SCOPE = 'audio_voice_assistant_get' # 有此scope表示有asr能力,没有请在网页里勾选,非常旧的应用可能没有
#测试自训练平台需要打开以下信息, 自训练平台模型上线后,您会看见 第二步:“”获取专属模型参数pid:8001,modelid:1234”,按照这个信息获取 dev_pid=8001,lm_id=1234
# DEV_PID = 8001 ;
# LM_ID = 1234 ;
# 极速版 打开注释的话请填写自己申请的appkey appSecret ,并在网页中开通极速版(开通后可能会收费)
# DEV_PID = 80001
# ASR_URL = 'http://vop.baidu.com/pro_api'
# SCOPE = 'brain_enhanced_asr' # 有此scope表示有极速版能力,没有请在网页里开通极速版
# 忽略scope检查,非常旧的应用可能没有
# SCOPE = False
class DemoError(Exception):
pass
""" TOKEN start """
TOKEN_URL = 'http://aip.baidubce.com/oauth/2.0/token'
def fetch_token():
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
post_data = urlencode(params)
if (IS_PY3):
post_data = post_data.encode( 'utf-8')
req = Request(TOKEN_URL, post_data)
try:
f = urlopen(req)
result_str = f.read()
except URLError as err:
print('token http response http code : ' + str(err.code))
result_str = err.read()
if (IS_PY3):
result_str = result_str.decode()
print(result_str)
result = json.loads(result_str)
print(result)
if ('access_token' in result.keys() and 'scope' in result.keys()):
print(SCOPE)
if SCOPE and (not SCOPE in result['scope'].split(' ')): # SCOPE = False 忽略检查
raise DemoError('scope is not correct')
print('SUCCESS WITH TOKEN: %s EXPIRES IN SECONDS: %s' % (result['access_token'], result['expires_in']))
return result['access_token']
else:
raise DemoError('MAYBE API_KEY or SECRET_KEY not correct: access_token or scope not found in token response')
""" TOKEN end """
if __name__ == '__main__':
token = fetch_token()
speech_data = []
with open(AUDIO_FILE, 'rb') as speech_file:
speech_data = speech_file.read()
length = len(speech_data)
if length == 0:
raise DemoError('file %s length read 0 bytes' % AUDIO_FILE)
speech = base64.b64encode(speech_data)
if (IS_PY3):
speech = str(speech, 'utf-8')
params = {'dev_pid': DEV_PID,
#"lm_id" : LM_ID, #测试自训练平台开启此项
'format': FORMAT,
'rate': RATE,
'token': token,
'cuid': CUID,
'channel': 1,
'speech': speech,
'len': length
}
post_data = json.dumps(params, sort_keys=False)
# print post_data
req = Request(ASR_URL, post_data.encode('utf-8'))
req.add_header('Content-Type', 'application/json')
try:
begin = timer()
f = urlopen(req)
result_str = f.read()
except URLError as err:
result_str = err.read()
if (IS_PY3):
result_str = str(result_str, 'utf-8')
print(result_str)
with open("result.txt", "w") as f:
f.write(result_str)
with open("result.txt", "r") as of:
content = of.read()
re_str = r'[\u4e00-\u9fa5]+'
resp = re.findall(re_str, content)
result = ' '.join(resp)
print(result)代码最后一部分我进行了修改,能够输入识别的中文,源代码还会输出其他的一些符号,有需要的可以参考改一下。建议对着源代码参考一下。

为了后续进行短句相似度匹配 在这个最后面又加了一段代码,意思是将识别结果保存到tsv文件中,方便后续操作。
with open("test.tsv", "w", newline='', encoding='utf-8') as d:
tsv_w = csv.writer(d, delimiter='\t')
tsv_w.writerow([result, '把桌子擦干净']) # 单行写入3.基于ERNIE-Gam进行语句相似度匹配
首先下载千言数据集lcqmc,下载连接如下
https://aistudio.baidu.com/aistudio/datasetdetail/78992
接下来需要安装环境cuda和paddle,这个不细讲(最好在conda中创建一个环境),网上很多教程,注意!!!cuda和paddle的版本一定要对应!!!不然会出现很多意想不到的错误!!!
进入pycharm 选择创建的环境
pip install --upgrade paddlenlp -i https://pypi.org/simple创建data_pre.py文件
import time
import os
import numpy as np
import paddle
import paddle.nn.functional as F
from paddlenlp.datasets import load_dataset
from paddlenlp.datasets import MapDataset
import paddlenlp
import pandas as pd
from paddle.io import Dataset
from sklearn.model_selection import train_test_split
class MyDataset(Dataset):
"""
构造自己的数据类,配合后面的Dataloader使用
"""
def __init__(self, data, mode='train'):
super(MyDataset, self).__init__()
self.mode = mode
self.data = self._load_data(data)
# 改造数据集 将dataframe格式数据转换为[{},{}]形式数据
def _load_data(self, data):
data_set = []
for index, row in data.iterrows():
data_dict = {}
data_dict['query'] = row['query']
data_dict['title'] = row['title']
if self.mode == 'train':
data_dict['label'] = row['label']
data_set.append(data_dict)
return data_set
def __getitem__(self, idx):
return self.data[idx]
def __len__(self):
return len(self.data)
train = pd.read_csv('/home/xwt/桌面/sentences transformer/own/train.tsv',sep='\t', names=['query', 'title','label'])
x_train,x_dev = train_test_split(train,test_size=0.1, stratify=train['label'].iloc[:])
x_train.shape
train_ds = MapDataset(MyDataset(x_train))
dev_ds = MapDataset(MyDataset(x_dev))
#输出训练集的前 3 条样本
#for idx, example in enumerate(train_ds):
# if idx <= 3:
# print(example)
此处需要将下载的lcqmc文件下的train.tsv文件的路径修改到此处
![]()
创建data_predict.py文件
import data_pre
from data_pre import *
tokenizer = paddlenlp.transformers.ErnieGramTokenizer.from_pretrained('ernie-gram-zh')
# 将 1 条明文数据的 query、title 拼接起来,根据预训练模型的 tokenizer 将明文转换为 ID 数据
# 返回 input_ids 和 token_type_ids
def convert_example(example, tokenizer, max_seq_length=512, is_test=False):
query, title = example["query"], example["title"]
encoded_inputs = tokenizer(
text=query, text_pair=title, max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"]
if not is_test:
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
# 在预测或者评估阶段,不返回 label 字段
else:
return input_ids, token_type_ids
# 为了后续方便使用,我们使用python偏函数(partial)给 convert_example 赋予一些默认参数
from functools import partial
# 训练集和验证集的样本转换函数
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=512)
from paddlenlp.data import Stack, Pad, Tuple
# 我们的训练数据会返回 input_ids, token_type_ids, labels 3 个字段
# 因此针对这 3 个字段需要分别定义 3 个组 batch 操作
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack(dtype="int64") # label
): [data for data in fn(samples)]
# 定义分布式 Sampler: 自动对训练数据进行切分,支持多卡并行训练
batch_sampler = paddle.io.DistributedBatchSampler(train_ds, batch_size=32, shuffle=True)
# 基于 train_ds 定义 train_data_loader
# 因为我们使用了分布式的 DistributedBatchSampler, train_data_loader 会自动对训练数据进行切分
train_data_loader = paddle.io.DataLoader(
dataset=train_ds.map(trans_func),
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
return_list=True)
# 针对验证集数据加载,我们使用单卡进行评估,所以采用 paddle.io.BatchSampler 即可
# 定义 dev_data_loader
batch_sampler = paddle.io.BatchSampler(dev_ds, batch_size=32, shuffle=False)
dev_data_loader = paddle.io.DataLoader(
dataset=dev_ds.map(trans_func),
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
return_list=True)创建modle_build.py文件
import data_pre
import paddle.nn as nn
from data_pre import *
# 我们基于 ERNIE-Gram 模型结构搭建 Point-wise 语义匹配网络
# 所以此处先定义 ERNIE-Gram 的 pretrained_model
pretrained_model = paddlenlp.transformers.ErnieGramModel.from_pretrained('ernie-gram-zh')
# pretrained_model = paddlenlp.transformers.ErnieModel.from_pretrained('ernie-1.0')
class PointwiseMatching(nn.Layer):
# 此处的 pretained_model 在本例中会被 ERNIE-Gram 预训练模型初始化
def __init__(self, pretrained_model, dropout=None):
super().__init__()
self.ptm = pretrained_model
self.dropout = nn.Dropout(dropout if dropout is not None else 0.1)
# 语义匹配任务: 相似、不相似 2 分类任务
self.classifier = nn.Linear(self.ptm.config["hidden_size"], 2)
def forward(self,
input_ids,
token_type_ids=None,
position_ids=None,
attention_mask=None):
# 此处的 Input_ids 由两条文本的 token ids 拼接而成
# token_type_ids 表示两段文本的类型编码
# 返回的 cls_embedding 就表示这两段文本经过模型的计算之后而得到的语义表示向量
_, cls_embedding = self.ptm(input_ids, token_type_ids, position_ids,
attention_mask)
cls_embedding = self.dropout(cls_embedding)
# 基于文本对的语义表示向量进行 2 分类任务
logits = self.classifier(cls_embedding)
probs = F.softmax(logits)
return probs
# 定义 Point-wise 语义匹配网络
model = PointwiseMatching(pretrained_model)创建modle_train.py文件
import data_pre
import data_predict
import modle_build
from paddlenlp.transformers import LinearDecayWithWarmup
from data_pre import *
from data_predict import *
from modle_build import *
epochs = 3
num_training_steps = len(train_data_loader) * epochs
# 定义 learning_rate_scheduler,负责在训练过程中对 lr 进行调度
lr_scheduler = LinearDecayWithWarmup(5E-5, num_training_steps, 0.0)
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
# 定义 Optimizer
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=0.0,
apply_decay_param_fun=lambda x: x in decay_params)
# 采用交叉熵 损失函数
criterion = paddle.nn.loss.CrossEntropyLoss()
# 评估的时候采用准确率指标
metric = paddle.metric.Accuracy()
# 因为训练过程中同时要在验证集进行模型评估,因此我们先定义评估函数
@paddle.no_grad()
def evaluate(model, criterion, metric, data_loader, phase="dev"):
model.eval()
metric.reset()
losses = []
for batch in data_loader:
input_ids, token_type_ids, labels = batch
probs = model(input_ids=input_ids, token_type_ids=token_type_ids)
loss = criterion(probs, labels)
losses.append(loss.numpy())
correct = metric.compute(probs, labels)
metric.update(correct)
accu = metric.accumulate()
print("eval {} loss: {:.5}, accu: {:.5}".format(phase,
np.mean(losses), accu))
model.train()
metric.reset()
# 接下来,开始正式训练模型,训练时间较长,可注释掉这部分
global_step = 0
tic_train = time.time()
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch
probs = model(input_ids=input_ids, token_type_ids=token_type_ids)
loss = criterion(probs, labels)
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
# 每间隔 10 step 输出训练指标
if global_step % 10 == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %.5f, accu: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, acc,
10 / (time.time() - tic_train)))
tic_train = time.time()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
# 每间隔 100 step 在验证集和测试集上进行评估
if global_step % 100 == 0:
evaluate(model, criterion, metric, dev_data_loader, "dev")
# 训练结束后,存储模型参数
save_dir = os.path.join("checkpoint", "model_%d" % global_step)
os.makedirs(save_dir)
save_param_path = os.path.join(save_dir, 'model_state.pdparams')
paddle.save(model.state_dict(), save_param_path)
tokenizer.save_pretrained(save_dir)此处就开始训练数据集,训练时间比较长,可以根据实际情况将数据集的内容进行删减,选练结束后会生成一个文件夹

每次训练生成的model_162似乎不是固定的,不用特别在意。
创建modle_predict.py文件
import data_pre
import data_predict
import modle_build
# import sys
# sys.path.append('/home/xwt/桌面/sentences transformer/speech-demo/rest-api-asr/python/asr_json.py')
# import asr_json
from data_pre import *
from data_predict import *
from functools import partial
from modle_build import *
# 定义预测函数
def predict(model, data_loader):
batch_probs = []
# 预测阶段打开 eval 模式,模型中的 dropout 等操作会关掉
model.eval()
with paddle.no_grad():
for batch_data in data_loader:
input_ids, token_type_ids = batch_data
input_ids = paddle.to_tensor(input_ids)
token_type_ids = paddle.to_tensor(token_type_ids)
# 获取每个样本的预测概率: [batch_size, 2] 的矩阵
batch_prob = model(
input_ids=input_ids, token_type_ids=token_type_ids).numpy()
batch_probs.append(batch_prob)
batch_probs = np.concatenate(batch_probs, axis=0)
return batch_probs
# 定义预测数据的 data_loader
# 预测数据的转换函数
# predict 数据没有 label, 因此 convert_exmaple 的 is_test 参数设为 True
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=512,
is_test=True)
# 预测数据的组 batch 操作
# predict 数据只返回 input_ids 和 token_type_ids,因此只需要 2 个 Pad 对象作为 batchify_fn
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment_ids
): [data for data in fn(samples)]
# 加载预测数据
test = pd.read_csv('/home/xwt/桌面/sentences transformer/speech-demo/rest-api-asr/python/test.tsv',sep='\t', names=['query', 'title'])
test_ds = MapDataset(MyDataset(test,mode='test'))
batch_sampler = paddle.io.BatchSampler(test_ds, batch_size=32, shuffle=False)
# 生成预测数据 data_loader
predict_data_loader = paddle.io.DataLoader(
dataset=test_ds.map(trans_func),
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
return_list=True)
pretrained_model = paddlenlp.transformers.ErnieGramModel.from_pretrained('ernie-gram-zh')
model = PointwiseMatching(pretrained_model)
state_dict = paddle.load("/home/xwt/桌面/sentences transformer/checkpoint/model_162/model_state.pdparams")
model.set_dict(state_dict)
# 执行预测函数
y_probs = predict(model, predict_data_loader)
# 根据预测概率获取预测 label
y_preds = np.argmax(y_probs, axis=1)
# 将预测结果存储在lcqmc.tsv 中,用来后续提交
# 同时将预测结果输出到终端,便于大家直观感受模型预测效果
test = pd.read_csv('/home/xwt/桌面/sentences transformer/speech-demo/rest-api-asr/python/test.tsv', sep='\t', names=['query', 'title'])
test_ds = MapDataset(MyDataset(test,mode='test'))
with open("lcqmc.tsv", 'w', encoding="utf-8") as f:
f.write("index\tprediction\n")
for idx, y_pred in enumerate(y_preds):
f.write("{}\t{}\n".format(idx, y_pred))
text_pair = test_ds[idx]
text_pair["label"] = y_pred
print(text_pair)
if y_pred == 1:
print("擦桌子")
else:
print("请给出正确指令")
这里有两个需要修改的地方
第一个
![]()
将预测数据更换为步骤2生成的test.tsv文件的路径
第二个
![]()
将paddle.load()里面的路径修改刚刚上一个py文件运行后生成的文件的路径
从上到下 依次运行每一个py文件
最后的输出结果如下

最后根据自己的需要进行修改即可!