TPLinker 联合抽取 实体链接方式+源码分析
关系抽取–TPLinker: https://blog.csdn.net/weixin_42223207/article/details/116425447

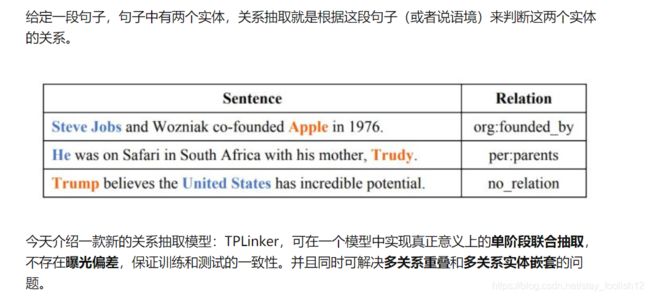
Tagging
TPLinker模型需要对关系三元组(subject, relation, object)进行手动Tagging,过程分为三部分:
(1)entity head to entity tail (EH-TO-ET)
(2)subject head to object head (SH-to-OH)
(3)subject tail to object tail (ST-to-OT)
标记示例见下图,EH-TO-ET用紫色表示,SH-to-OH用红色表示,ST-to-OT用蓝色表示。
论文笔记:路由器 TPLinker 也来做关系抽取:https://zhuanlan.zhihu.com/p/304104571
关系抽取之TPLinker解读加源码分析:https://zhuanlan.zhihu.com/p/342300800
关于解码过程
通过实体抽取得到字典D后,遍历关系,通过关系得到有关系的两个实体的尾部E, 再通过关系得到有关系的两个实体的头部,结合字典D得到这两个实体尾部set(s),set(o)(此为真实的标签),再通过set(s),set(o)在不在E里面,来判断是否成功抽取了一条三元组。
其中相关的公式:
文章的大概内容进行了解读,现在到了代码解读环节:
输入数据部分:
输入的seq的长度为seq_len ,获取句子的最大长度
train and valid max token num
max_tok_num = 0
all_data = train_data + valid_data
for sample in all_data:
tokens = tokenize(sample["text"])
max_tok_num = max(max_tok_num, len(tokens))
max_tok_num # 获取句子的最大长度
接下来对文本超过长度的进行划窗处理:
if max_tok_num > hyper_parameters["max_seq_len"]: # 截断长度
train_data = preprocessor.split_into_short_samples(train_data,
hyper_parameters["max_seq_len"],
sliding_len = hyper_parameters["sliding_len"],
encoder = config["encoder"] #超过长度则滑动窗口得到新的样本
)
valid_data = preprocessor.split_into_short_samples(valid_data,
hyper_parameters["max_seq_len"],
sliding_len = hyper_parameters["sliding_len"],
encoder = config["encoder"]
)
接下来看划窗的具体操作
def split_into_short_samples(self, sample_list, max_seq_len, sliding_len = 50, encoder = "BERT", data_type = "train"):
new_sample_list = []
for sample in tqdm(sample_list, desc = "Splitting into subtexts"):
text_id = sample["id"]
text = sample["text"]
tokens = self._tokenize(text)
tok2char_span = self._get_tok2char_span_map(text) #返回句子中单词的偏移量
# sliding at token level
split_sample_list = []
for start_ind in range(0, len(tokens), sliding_len): #sliding_len 滑动窗口的大小,
if encoder == "BERT": # if use bert, do not split a word into two samples
while "##" in tokens[start_ind]:
start_ind -= 1
end_ind = start_ind + max_seq_len # 结束的长度
char_span_list = tok2char_span[start_ind:end_ind] #截断
char_level_span = [char_span_list[0][0], char_span_list[-1][1]] #第一个词到最后一个词的长度
sub_text = text[char_level_span[0]:char_level_span[1]]#原始文本截断
new_sample = {
"id": text_id,
"text": sub_text,
"tok_offset": start_ind, #token的偏移量
"char_offset": char_level_span[0], #每个字符的偏移量
}
if data_type == "test": # test set
if len(sub_text) > 0:
split_sample_list.append(new_sample)
else: # train or valid dataset, only save spo and entities in the subtext
# spo
sub_rel_list = []
for rel in sample["relation_list"]:
subj_tok_span = rel["subj_tok_span"]
obj_tok_span = rel["obj_tok_span"]
# if subject and object are both in this subtext, add this spo to new sample
if subj_tok_span[0] >= start_ind and subj_tok_span[1] <= end_ind \
and obj_tok_span[0] >= start_ind and obj_tok_span[1] <= end_ind:
new_rel = copy.deepcopy(rel)
new_rel["subj_tok_span"] = [subj_tok_span[0] - start_ind, subj_tok_span[1] - start_ind] # start_ind: 单词级别的偏移量
new_rel["obj_tok_span"] = [obj_tok_span[0] - start_ind, obj_tok_span[1] - start_ind]
new_rel["subj_char_span"][0] -= char_level_span[0] # 字符级别的偏移量
new_rel["subj_char_span"][1] -= char_level_span[0]
new_rel["obj_char_span"][0] -= char_level_span[0]
new_rel["obj_char_span"][1] -= char_level_span[0]
sub_rel_list.append(new_rel)
# entity
sub_ent_list = []
for ent in sample["entity_list"]:
tok_span = ent["tok_span"]
# if entity in this subtext, add the entity to new sample
if tok_span[0] >= start_ind and tok_span[1] <= end_ind:
new_ent = copy.deepcopy(ent)
new_ent["tok_span"] = [tok_span[0] - start_ind, tok_span[1] - start_ind]
new_ent["char_span"][0] -= char_level_span[0]
new_ent["char_span"][1] -= char_level_span[0]
sub_ent_list.append(new_ent)
# event
if "event_list" in sample:
sub_event_list = []
for event in sample["event_list"]:
trigger_tok_span = event["trigger_tok_span"]
if trigger_tok_span[1] > end_ind or trigger_tok_span[0] < start_ind:
continue
new_event = copy.deepcopy(event)
new_arg_list = []
for arg in new_event["argument_list"]:
if arg["tok_span"][0] >= start_ind and arg["tok_span"][1] <= end_ind:
new_arg_list.append(arg)
new_event["argument_list"] = new_arg_list
sub_event_list.append(new_event)
new_sample["event_list"] = sub_event_list # maybe empty
new_sample["entity_list"] = sub_ent_list # maybe empty
new_sample["relation_list"] = sub_rel_list # maybe empty
split_sample_list.append(new_sample)
# all segments covered, no need to continue
if end_ind > len(tokens):
break
new_sample_list.extend(split_sample_list)
return new_sample_list
输入数据,DataMaker4Bert中定义:
class DataMaker4Bert():
def __init__(self, tokenizer, handshaking_tagger):
self.tokenizer = tokenizer
self.handshaking_tagger = handshaking_tagger
def get_indexed_data(self, data, max_seq_len, data_type = "train"): #index转换为data
indexed_samples = []
for ind, sample in tqdm(enumerate(data), desc = "Generate indexed train or valid data"):
text = sample["text"]
# codes for bert input
codes = self.tokenizer.encode_plus(text,
return_offsets_mapping = True,
add_special_tokens = False,
max_length = max_seq_len,
truncation = True,
pad_to_max_length = True)
# tagging
spots_tuple = None
if data_type != "test":
spots_tuple = self.handshaking_tagger.get_spots(sample) #获取实体,头,尾标签
# get codes
input_ids = torch.tensor(codes["input_ids"]).long()
attention_mask = torch.tensor(codes["attention_mask"]).long()
token_type_ids = torch.tensor(codes["token_type_ids"]).long()
tok2char_span = codes["offset_mapping"]
sample_tp = (sample,
input_ids,
attention_mask,
token_type_ids,
tok2char_span,
spots_tuple,
)
indexed_samples.append(sample_tp)
return indexed_samples
输入的是tokenizer和handshakingtagger,tokenizer为bert等一系列模型的标准输入,而get_spots函数获取了实体,头,尾的标签,具体看下代码
def get_spots(self, sample):
'''
entity spot and tail_rel spot: (span_pos1, span_pos2, tag_id)
head_rel spot: (rel_id, span_pos1, span_pos2, tag_id)
'''
ent_matrix_spots, head_rel_matrix_spots, tail_rel_matrix_spots = [], [], []
for rel in sample["relation_list"]:
subj_tok_span = rel["subj_tok_span"]
obj_tok_span = rel["obj_tok_span"]
ent_matrix_spots.append((subj_tok_span[0], subj_tok_span[1] - 1, self.tag2id_ent["ENT-H2T"])) #sub token的[起始位置,尾部位置,实体标签(1)]
ent_matrix_spots.append((obj_tok_span[0], obj_tok_span[1] - 1, self.tag2id_ent["ENT-H2T"]))# obj token的[起始位置,尾部位置,实体标签(1)]
if subj_tok_span[0] <= obj_tok_span[0]:
head_rel_matrix_spots.append((self.rel2id[rel["predicate"]], subj_tok_span[0], obj_tok_span[0], self.tag2id_head_rel["REL-SH2OH"]))#【关系类别,实体_1 头部,实体_2头部,关系标签(1)】
else:
head_rel_matrix_spots.append((self.rel2id[rel["predicate"]], obj_tok_span[0], subj_tok_span[0], self.tag2id_head_rel["REL-OH2SH"]))#【关系类别,实体_1 头部,实体_2头部,关系标签(2)】
if subj_tok_span[1] <= obj_tok_span[1]:
tail_rel_matrix_spots.append((self.rel2id[rel["predicate"]], subj_tok_span[1] - 1, obj_tok_span[1] - 1, self.tag2id_tail_rel["REL-ST2OT"]))#【关系类别,实体_1 尾部,实体_2尾部,关系标签(1)】
else:
tail_rel_matrix_spots.append((self.rel2id[rel["predicate"]], obj_tok_span[1] - 1, subj_tok_span[1] - 1, self.tag2id_tail_rel["REL-OT2ST"]))#【关系类别,实体_1 尾部,实体_2尾部,关系标签(2)】
return ent_matrix_spots, head_rel_matrix_spots, tail_rel_matrix_spots
获取输入的数据
indexed_train_data = data_maker.get_indexed_data(train_data, max_seq_len) #获取输入
# index_train_data = data_maker.get_indexed_data(train_test_data,max_seq_len)
indexed_valid_data = data_maker.get_indexed_data(valid_data, max_seq_len)
tokenizer = BertTokenizerFast.from_pretrained(config["bert_path"], add_special_tokens = False, do_lower_case = False)
data_maker = DataMaker4Bert(tokenizer, handshaking_tagger) #(sample,input_ids,attention_mask,token_type_ids,tok2char_span,spots_tuple,)
接下来则是定义HandshakingTaggingScheme
max_seq_len = min(max_tok_num, hyper_parameters["max_seq_len"]) #max_len 长度
rel2id = json.load(open(rel2id_path, "r", encoding = "utf-8"))
handshaking_tagger = HandshakingTaggingScheme(rel2id = rel2id, max_seq_len = max_seq_len) #初始化
查看具体的定义
class HandshakingTaggingScheme(object):
"""docstring for HandshakingTaggingScheme"""
def __init__(self, rel2id, max_seq_len):
super(HandshakingTaggingScheme, self).__init__()
self.rel2id = rel2id
self.id2rel = {ind:rel for rel, ind in rel2id.items()}
self.tag2id_ent = { #实体头尾
"O": 0,
"ENT-H2T": 1, # entity head to entity tail
}
self.id2tag_ent = {id_:tag for tag, id_ in self.tag2id_ent.items()}
self.tag2id_head_rel = { #sub,obj头对头标识1,obj头对sub头标识2
"O": 0,
"REL-SH2OH": 1, # subject head to object head
"REL-OH2SH": 2, # object head to subject head
}
self.id2tag_head_rel = {id_:tag for tag, id_ in self.tag2id_head_rel.items()}
self.tag2id_tail_rel = {
"O": 0,
"REL-ST2OT": 1, # subject tail to object tail
"REL-OT2ST": 2, # object tail to subject tail
}
self.id2tag_tail_rel = {id_:tag for tag, id_ in self.tag2id_tail_rel.items()}
# mapping shaking sequence and matrix
self.matrix_size = max_seq_len
# e.g. [(0, 0), (0, 1), (0, 2), (1, 1), (1, 2), (2, 2)] #转换成矩阵上三角矩阵平铺
self.shaking_ind2matrix_ind = [(ind, end_ind) for ind in range(self.matrix_size) for end_ind in list(range(self.matrix_size))[ind:]]
self.matrix_ind2shaking_ind = [[0 for i in range(self.matrix_size)] for j in range(self.matrix_size)]
for shaking_ind, matrix_ind in enumerate(self.shaking_ind2matrix_ind): #上三角矩阵,上三角每个元素储存着上三角铺平序列的相对应的位置序号
self.matrix_ind2shaking_ind[matrix_ind[0]][matrix_ind[1]] = shaking_ind
这里比较关键的是shaking_ind2matrix_ind,与matrix_ind2shaking_ind,其中shaking_ind2matrix_ind如下所示,是一个上三角铺平序列
[(0, 0), (0, 1), (0, 2), (0, 3), (0, 4), (0, 5), (0, 6), (0, 7), (0, 8), (0, 9), (0, 10), (0, 11), (0, 12), (0, 13), …]
而matrix_ind2shaking_ind为优化前的二维矩阵,其中上三角每个元素储存着上三角铺平序列的相对应的位置序号
[[0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], …]
最后组成上三角矩阵(打印的结果没有填满)
[[0, 1, 2, 3, 4, 5, 6, 7, 8, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], [0, 0, 0, 0, 0, 0, 0, 0, 0, …], …]
载入数据
train_dataloader = DataLoader(MyDataset(indexed_train_data),
batch_size = hyper_parameters["batch_size"],
shuffle = False,
num_workers = 5,
drop_last = False,
collate_fn = data_maker.generate_batch,
)
查看DataLoader的返回值:
def generate_batch(self, batch_data, data_type = "train"):
sample_list = []
input_ids_list = []
attention_mask_list = []
token_type_ids_list = []
tok2char_span_list = []
ent_spots_list = []
head_rel_spots_list = []
tail_rel_spots_list = []
for tp in batch_data:
sample_list.append(tp[0])
input_ids_list.append(tp[1])
attention_mask_list.append(tp[2])
token_type_ids_list.append(tp[3])
tok2char_span_list.append(tp[4])
if data_type != "test":
ent_matrix_spots, head_rel_matrix_spots, tail_rel_matrix_spots = tp[5]
ent_spots_list.append(ent_matrix_spots)
head_rel_spots_list.append(head_rel_matrix_spots)
tail_rel_spots_list.append(tail_rel_matrix_spots)
# @specific: indexed by bert tokenizer
batch_input_ids = torch.stack(input_ids_list, dim = 0)
batch_attention_mask = torch.stack(attention_mask_list, dim = 0)
batch_token_type_ids = torch.stack(token_type_ids_list, dim = 0)
batch_ent_shaking_tag, batch_head_rel_shaking_tag, batch_tail_rel_shaking_tag = None, None, None
if data_type != "test":
batch_ent_shaking_tag = self.handshaking_tagger.sharing_spots2shaking_tag4batch(ent_spots_list)
batch_head_rel_shaking_tag = self.handshaking_tagger.spots2shaking_tag4batch(head_rel_spots_list)
batch_tail_rel_shaking_tag = self.handshaking_tagger.spots2shaking_tag4batch(tail_rel_spots_list)
return sample_list, \
batch_input_ids, batch_attention_mask, batch_token_type_ids, tok2char_span_list, \
batch_ent_shaking_tag, batch_head_rel_shaking_tag, batch_tail_rel_shaking_tag
其中比较重要的是batch_ent_shaking_tag, batch_head_rel_shaking_tag, batch_tail_rel_shaking_tag这三个函数,在实体batch_ent_shaking_tag中用到了handshaking_tagger的sharing_spots2shaking_tag4batch的函数
def sharing_spots2shaking_tag4batch(self, batch_spots):
'''
convert spots to batch shaking seq tag
因长序列的stack是费时操作,所以写这个函数用作生成批量shaking tag
如果每个样本生成一条shaking tag再stack,一个32的batch耗时1s,太昂贵
spots: [(start_ind, end_ind, tag_id), ], for entiy
return:
batch_shake_seq_tag: (batch_size, shaking_seq_len)
'''
shaking_seq_len = self.matrix_size * (self.matrix_size + 1) // 2
batch_shaking_seq_tag = torch.zeros(len(batch_spots), shaking_seq_len).long()
for batch_id, spots in enumerate(batch_spots):
for sp in spots:
shaking_ind = self.matrix_ind2shaking_ind[sp[0]][sp[1]] #在矩阵中找到实体的的start_int,跟end_int的位置值
tag_id = sp[2]
batch_shaking_seq_tag[batch_id][shaking_ind] = tag_id #铺平上三角矩阵,标注序列中的实体标识1的位置
return batch_shaking_seq_tag
在关系batch_head_rel_shaking_tag与batch_tail_rel_shaking_tag中用到了spots2shaking_tag4batch
def spots2shaking_tag4batch(self, batch_spots):
‘’’
convert spots to batch shaking seq tag
spots: [(rel_id, start_ind, end_ind, tag_id), ], for head relation and tail_relation
return:
batch_shake_seq_tag: (batch_size, rel_size, shaking_seq_len)
‘’’
shaking_seq_len = self.matrix_size * (self.matrix_size + 1) // 2
batch_shaking_seq_tag = torch.zeros(len(batch_spots), len(self.rel2id), shaking_seq_len).long()
for batch_id, spots in enumerate(batch_spots):
for sp in spots:
shaking_ind = self.matrix_ind2shaking_ind[sp[1]][sp[2]]
tag_id = sp[3]
rel_id = sp[0]
batch_shaking_seq_tag[batch_id][rel_id][shaking_ind] = tag_id
return batch_shaking_seq_tag
跟实体类似,只是多了关系总数,然后整个函数的返回为
return sample_list,
batch_input_ids, tok2char_span_list,
batch_ent_shaking_tag, batch_head_rel_shaking_tag, batch_tail_rel_shaking_tag
初始化模型
rel_extractor = TPLinkerBert(encoder,
len(rel2id),
hyper_parameters[“shaking_type”],
hyper_parameters[“inner_enc_type”],
hyper_parameters[“dist_emb_size”],
hyper_parameters[“ent_add_dist”],
hyper_parameters[“rel_add_dist”],
)
模型的具体定义
class TPLinkerBert(nn.Module):
def __init__(self, encoder,
rel_size,
shaking_type,
inner_enc_type,
dist_emb_size,
ent_add_dist,
rel_add_dist
):
super().__init__()
self.encoder = encoder
hidden_size = encoder.config.hidden_size
self.ent_fc = nn.Linear(hidden_size, 2) #实体预测,0,1
self.head_rel_fc_list = [nn.Linear(hidden_size, 3) for _ in range(rel_size)] #rel_size多少种关系
self.tail_rel_fc_list = [nn.Linear(hidden_size, 3) for _ in range(rel_size)]# 对每个关系进行个linear层的3分类【0,1,2】
for ind, fc in enumerate(self.head_rel_fc_list):
self.register_parameter("weight_4_head_rel{}".format(ind), fc.weight) #过3层全连接层
self.register_parameter("bias_4_head_rel{}".format(ind), fc.bias) #偏差
for ind, fc in enumerate(self.tail_rel_fc_list):
self.register_parameter("weight_4_tail_rel{}".format(ind), fc.weight)
self.register_parameter("bias_4_tail_rel{}".format(ind), fc.bias)
# handshaking kernel
self.handshaking_kernel = HandshakingKernel(hidden_size, shaking_type, inner_enc_type)
# distance embedding
self.dist_emb_size = dist_emb_size
self.dist_embbedings = None # it will be set in the first forwarding
self.ent_add_dist = ent_add_dist
self.rel_add_dist = rel_add_dist
self.head_rel_fc_list与self.tail_rel_fc_list相同,是关系的一个全连接(标签有三个0,1,2),每一种关系有一个独立的MLP层,self.head_rel_fc_list是列表的形式。
上面为关系和实体关系预测,实体和各个关系都经过了mlp层,我们假设有5种关系,则会有11层MLP即为:1个实体预测层+(1个头部层+1个尾部层)*5
def forward(self, input_ids, attention_mask, token_type_ids):
# input_ids, attention_mask, token_type_ids: (batch_size, seq_len)
context_outputs = self.encoder(input_ids, attention_mask, token_type_ids) # 0 last_hidden 1 pooled
# last_hidden_state: (batch_size, seq_len, hidden_size)
last_hidden_state = context_outputs[0]
# shaking_hiddens: (batch_size, 1 + ... + seq_len, hidden_size)
shaking_hiddens = self.handshaking_kernel(last_hidden_state) #铺平上三角矩阵
shaking_hiddens4ent = shaking_hiddens
shaking_hiddens4rel = shaking_hiddens
# add distance embeddings if it is set
if self.dist_emb_size != -1:
# set self.dist_embbedings
hidden_size = shaking_hiddens.size()[-1]
if self.dist_embbedings is None:
dist_emb = torch.zeros([self.dist_emb_size, hidden_size]).to(shaking_hiddens.device)
for d in range(self.dist_emb_size):
for i in range(hidden_size):
if i % 2 == 0:
dist_emb[d][i] = math.sin(d / 10000**(i / hidden_size))
else:
dist_emb[d][i] = math.cos(d / 10000**((i - 1) / hidden_size))
seq_len = input_ids.size()[1]
dist_embbeding_segs = []
for after_num in range(seq_len, 0, -1): #铺平
dist_embbeding_segs.append(dist_emb[:after_num, :])
self.dist_embbedings = torch.cat(dist_embbeding_segs, dim = 0)
if self.ent_add_dist:
shaking_hiddens4ent = shaking_hiddens + self.dist_embbedings[None,:,:].repeat(shaking_hiddens.size()[0], 1, 1)
if self.rel_add_dist:
shaking_hiddens4rel = shaking_hiddens + self.dist_embbedings[None,:,:].repeat(shaking_hiddens.size()[0], 1, 1)
# if self.dist_emb_size != -1 and self.ent_add_dist:
# shaking_hiddens4ent = shaking_hiddens + self.dist_embbedings[None,:,:].repeat(shaking_hiddens.size()[0], 1, 1)
# else:
# shaking_hiddens4ent = shaking_hiddens
# if self.dist_emb_size != -1 and self.rel_add_dist:
# shaking_hiddens4rel = shaking_hiddens + self.dist_embbedings[None,:,:].repeat(shaking_hiddens.size()[0], 1, 1)
# else:
# shaking_hiddens4rel = shaking_hiddens
ent_shaking_outputs = self.ent_fc(shaking_hiddens4ent) #实体预测,(0,1)
head_rel_shaking_outputs_list = []
nn.ModuleList()
for fc in self.head_rel_fc_list:
head_rel_shaking_outputs_list.append(fc(shaking_hiddens4rel)) #对每一种关系头进行分类
tail_rel_shaking_outputs_list = []
for fc in self.tail_rel_fc_list: #对每一种关系尾进行分类
tail_rel_shaking_outputs_list.append(fc(shaking_hiddens4rel))
head_rel_shaking_outputs = torch.stack(head_rel_shaking_outputs_list, dim = 1) #n种关系拼接在一起
tail_rel_shaking_outputs = torch.stack(tail_rel_shaking_outputs_list, dim = 1) #n种关系拼接在一起
return ent_shaking_outputs, head_rel_shaking_outputs, tail_rel_shaking_outputs
ent_shaking_outputs为实体预测,head_rel_shaking_outputs_list对关系头进行分类,tail_rel_shaking_outputs_list对关系尾进行分类,其中关键函数shaking_hiddens4ent中的HandshakingKernel函数定义如下
class HandshakingKernel(nn.Module):
def __init__(self, hidden_size, shaking_type, inner_enc_type):
super().__init__()
self.shaking_type = shaking_type
if shaking_type == "cat":
self.combine_fc = nn.Linear(hidden_size * 2, hidden_size) #fc层
elif shaking_type == "cat_plus":
self.combine_fc = nn.Linear(hidden_size * 3, hidden_size)
elif shaking_type == "cln":
self.tp_cln = LayerNorm(hidden_size, hidden_size, conditional = True)
elif shaking_type == "cln_plus":
self.tp_cln = LayerNorm(hidden_size, hidden_size, conditional = True)
self.inner_context_cln = LayerNorm(hidden_size, hidden_size, conditional = True)
self.inner_enc_type = inner_enc_type #一层单向lstm
if inner_enc_type == "mix_pooling":
self.lamtha = Parameter(torch.rand(hidden_size))
elif inner_enc_type == "lstm":
self.inner_context_lstm = nn.LSTM(hidden_size,
hidden_size,
num_layers = 1,
bidirectional = False,
batch_first = True)
def enc_inner_hiddens(self, seq_hiddens, inner_enc_type = "lstm"):
# seq_hiddens: (batch_size, seq_len, hidden_size)
def pool(seqence, pooling_type):
if pooling_type == "mean_pooling":
pooling = torch.mean(seqence, dim = -2)
elif pooling_type == "max_pooling":
pooling, _ = torch.max(seqence, dim = -2)
elif pooling_type == "mix_pooling":
pooling = self.lamtha * torch.mean(seqence, dim = -2) + (1 - self.lamtha) * torch.max(seqence, dim = -2)[0]
return pooling
if "pooling" in inner_enc_type:
inner_context = torch.stack([pool(seq_hiddens[:, :i+1, :], inner_enc_type) for i in range(seq_hiddens.size()[1])], dim = 1)
elif inner_enc_type == "lstm":
inner_context, _ = self.inner_context_lstm(seq_hiddens)
return inner_context
def forward(self, seq_hiddens):
'''
seq_hiddens: (batch_size, seq_len, hidden_size)
return:
shaking_hiddenss: (batch_size, (1 + seq_len) * seq_len / 2, hidden_size) (32, 5+4+3+2+1, 5)
'''#一句话中每个字与剩下的字构成上三角矩阵如:长度为5则的到的为[[batch,5,hidden_size],[batch,4,hidden_size]...]
seq_len = seq_hiddens.size()[-2] #句子的长度
shaking_hiddens_list = []
for ind in range(seq_len):
hidden_each_step = seq_hiddens[:, ind, :] #取每个batch的每个字的维度
visible_hiddens = seq_hiddens[:, ind:, :] # 从当前取到最后
repeat_hiddens = hidden_each_step[:, None, :].repeat(1, seq_len - ind, 1) #复制dim=1的维度跟visible维度保持一致
if self.shaking_type == "cat":#选择的是cat模式,可以在配置文件中设置
shaking_hiddens = torch.cat([repeat_hiddens, visible_hiddens], dim = -1) #将当前每个字的维度与其后的每个字的维度拼接在一起
shaking_hiddens = torch.tanh(self.combine_fc(shaking_hiddens))#过一个线性层
elif self.shaking_type == "cat_plus":
inner_context = self.enc_inner_hiddens(visible_hiddens, self.inner_enc_type)
shaking_hiddens = torch.cat([repeat_hiddens, visible_hiddens, inner_context], dim = -1)
shaking_hiddens = torch.tanh(self.combine_fc(shaking_hiddens))
elif self.shaking_type == "cln":
shaking_hiddens = self.tp_cln(visible_hiddens, repeat_hiddens)
elif self.shaking_type == "cln_plus":
inner_context = self.enc_inner_hiddens(visible_hiddens, self.inner_enc_type)
shaking_hiddens = self.tp_cln(visible_hiddens, repeat_hiddens)
shaking_hiddens = self.inner_context_cln(shaking_hiddens, inner_context)
shaking_hiddens_list.append(shaking_hiddens) #添加到列表中
long_shaking_hiddens = torch.cat(shaking_hiddens_list, dim = 1)#铺平上三角矩阵
return long_shaking_hiddens
输入的seq_hiddens维度是[batch,seq_len, hiddensize],是一句话经过bert编码过后的值,而HandshakingKernel函数的作用是将矩阵变为上三角矩阵,即本身矩阵为[seq_len * seq_len],在经过函数过后为每一行都减1,最后通过long_shakinghiddens把函数把结果铺平,得到[seq_len+(seq_len -1) + (seq_len -2)…+1],对应了图片部分。
整个函数先是循环每句话中的词,当ind是0时,hidden_each_step代表了循环的每个词的编码[batch,1,hidden_size],visiblehiddens是循环到的这个单词以及之后的单词的编码,维度就是[batch,seq_len,hidden_size],repeat_hiddens对hidden_each_step的第二个维度进行了复制,维度为[batch,seq_len,hidden_size],将当前单词和其后的各个单词的编码进行拼接维度是[batch,seq_len,hidden_size*2]组成上三角矩阵的一行,在经过MLP层后shakinghiddens的维度是[batch,seq_len,hidden_size],之后每一行依次类推。
关于loss部分
total_loss, total_ent_sample_acc, total_head_rel_sample_acc, total_tail_rel_sample_acc = 0., 0., 0., 0.
for batch_ind, batch_train_data in enumerate(dataloader):
t_batch = time.time()
z = (2 * len(rel2id) + 1) # 2倍的关系
steps_per_ep = len(dataloader) #有多少数据
total_steps = hyper_parameters["loss_weight_recover_steps"] + 1 # + 1 avoid division by zero error #加速loss在一定的步数回归
current_step = steps_per_ep * ep + batch_ind # ?
w_ent = max(1 / z + 1 - current_step / total_steps, 1 / z)
w_rel = min((len(rel2id) / z) * current_step / total_steps, (len(rel2id) / z))
loss_weights = {"ent": w_ent, "rel": w_rel} #给予不同任务的权重
loss, ent_sample_acc, head_rel_sample_acc, tail_rel_sample_acc = train_step(batch_train_data, optimizer, loss_weights)
scheduler.step()
total_loss += loss
total_ent_sample_acc += ent_sample_acc
total_head_rel_sample_acc += head_rel_sample_acc
total_tail_rel_sample_acc += tail_rel_sample_acc
avg_loss = total_loss / (batch_ind + 1)
avg_ent_sample_acc = total_ent_sample_acc / (batch_ind + 1)
avg_head_rel_sample_acc = total_head_rel_sample_acc / (batch_ind + 1)
avg_tail_rel_sample_acc = total_tail_rel_sample_acc / (batch_ind + 1)
随着step加大,w_ent的权重递减,w_rel权重递增。先关注实体,保证实体抽准确,后面关注关系的抽取,由于目前工作原因,更多细节待闲时在进行解读。
百度信息抽取Lic2020关系抽取:https://zhuanlan.zhihu.com/p/138858558