深度学习图像分类神经网络
深度学习常见框架
- 基础介绍:
-
- 全连接层
- 卷积层:
- 池化层:
- LeNet
-
- 简介:
- 代码:
- 结果:
- AlexNet:
-
- 数据集:
- 代码:
- 训练后的结果:
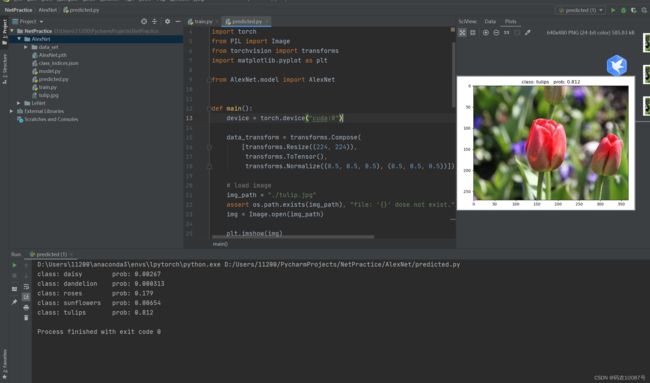
- 测试结果:
基础介绍:
全连接层
卷积层:
1.卷积核的channel与输入特征层的channel相同
2.输出的特征矩阵channel与卷积核个数相同
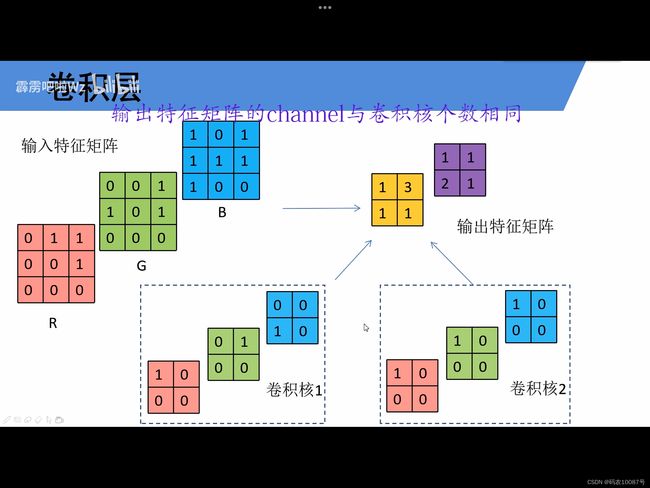
3.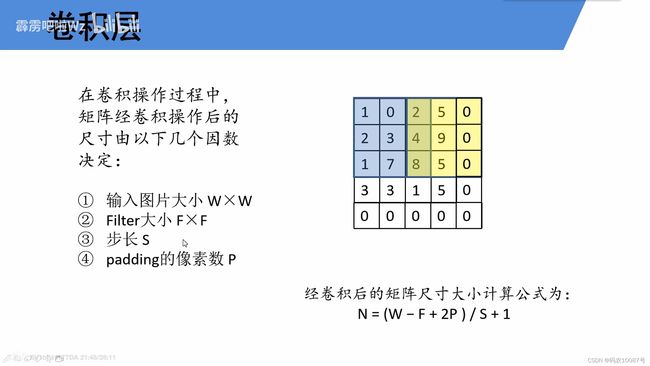
这张图里,
W=4,
F是滤波器也就是卷积核,F=3
S=2
P=1
一般都是补2p,这张图只给右边和下边补了,所以 N=(W-F+P)/S+1
池化层:


LeNet
简介:
详细介绍
代码:
model:
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5)
# 输入为 3 因为是RGB三通道,输出为16,即有16个卷积核
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
# 实际是(batch*16*28*28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
train:
import torch
import torchvision
import torch.nn as nn
from LeNet.model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
def main():
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 50000张训练图片
# 第一次使用时要将download设置为True才会自动去下载数据集
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36,
shuffle=True, num_workers=0)
# 10000张验证图片
# 第一次使用时要将download设置为True才会自动去下载数据集
val_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=10000,
shuffle=False, num_workers=0)
val_data_iter = iter(val_loader)
val_image, val_label = next(val_data_iter)
# classes = ('plane', 'car', 'bird', 'cat',
# 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
for epoch in range(5): # loop over the dataset multiple times
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if step % 500 == 499: # print every 500 mini-batches
with torch.no_grad():
outputs = net(val_image) # [batch, 10]
_, predict_y = torch.max(outputs, dim=1)
accuracy = torch.eq(predict_y, val_label).sum().item() / len(val_loader.dataset)
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
running_loss = 0.0
print('Finished Training')
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
if __name__ == '__main__':
main()
predicted:
import torch
import torchvision.transforms as transforms
from PIL import Image
from LeNet.model import LeNet
def main():
transform = transforms.Compose(
[transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
net.load_state_dict(torch.load('Lenet.pth'))
im = Image.open('1.jpg')
im = transform(im) # [C, H, W]
im = torch.unsqueeze(im, dim=0) # [N, C, H, W]
with torch.no_grad():
outputs = net(im)
predict = torch.max(outputs, dim=1)[1].numpy()
print(classes[int(predict)])
if __name__ == '__main__':
main()
结果:
训练结果:
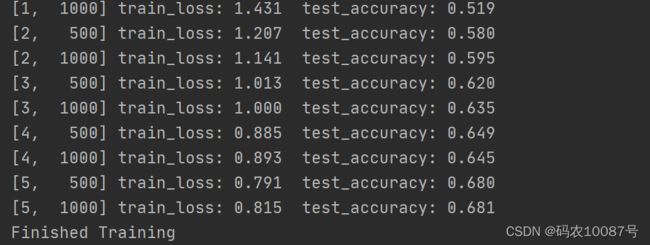
测试图片:

测试结果:
AlexNet:
数据集:
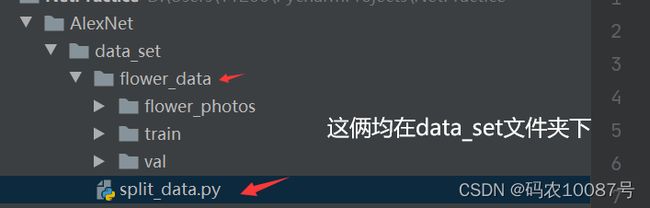
用split_data.py文件将flower_data文件夹里的图片分成训练数据集和验证数据集,最终形成后的如上图。
代码:
model:
import torch.nn as nn
import torch
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
# 这里改动了一些,将卷积核的个数改为了48,为了较快运算
# padding 论文里是左边补一列,右边补两列,这里用padding = 2,和论文里实质一样的效果,因为多余的会舍弃。
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True), # inplace 增加计算量,但是降低内存使用的一种方法。
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
# 全连接层的打包
self.classifier = nn.Sequential(
nn.Dropout(p=0.5), # 防止过拟合,一般放在全连接和全连接层之间。p代表随机失活的一个比例
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1) # 张平处理,dim=0是N批处理,dim=1是channel,从dim=1开始展平
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
train:
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from tqdm import tqdm
from AlexNet.model import AlexNet
def main():
device = torch.device("cuda:0")
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224), # 随机裁剪
transforms.RandomHorizontalFlip(), # 随机翻转
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "./.")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 32
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=4, shuffle=True,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
#
# def imshow(img):
# img = img / 2 + 0.5 # unnormalize
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1, 2, 0)))
# plt.show()
#
# print(' '.join('%5s' % cla_dict[test_label[j].item()] for j in range(4)))
# imshow(utils.make_grid(test_image))
# 花分类只有5个类别,初始化权重为True
net = AlexNet(num_classes=5, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
# pata = list(net.parameters())
optimizer = optim.Adam(net.parameters(), lr=0.0002)
epochs = 10
save_path = './AlexNet.pth'
best_acc = 0.0 # 保存准确率最高的训练的模型
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train() # 启用dropout方法
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval() # 关闭dropout方法
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()
predicted:
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from AlexNet.model import AlexNet
def main():
device = torch.device("cuda:0")
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img_path = "./tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# create model
model = AlexNet(num_classes=5).to(device)
# load model weights
weights_path = "./AlexNet.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()
训练后的结果:
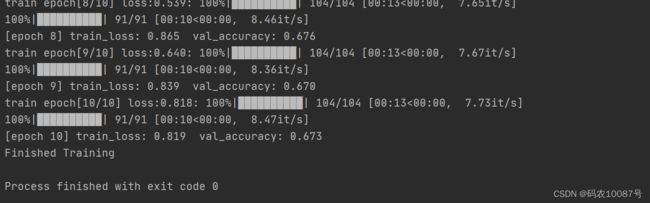
测试结果: