故障树手册(Fault Tree handbook)(6)
第十章 概率与统计分析
1 概述
在这章中,我们将试图去描述和故障树相关的概率与统计概念中的基本元素。这些知识也是故障树量化的基础。在这方面基础好的读者可以直接跳过本章去阅读第十一章,在后边需要的时候再来回顾对应的内容。
我们现在先来讨论概率分布理论。我们首先会讲解二项分布,接着学习常规的分布原理,并重点学习一些在系统分析中常用到的特殊分布。然后我们将具备统计评估的基础知识。
我们的表示法或许不是最好的传统数学统计,我们的方法是一个作者在对工程学的学生和工程师统计课程的过程中所采用的改进后的方法。我们有时会为了更好更快的阐述概念而牺牲一些数学的严谨性。
2 二项分布
假设我们有四个相似的系统,这些系统都经过特定时间的测试。在测试的最后我们进一步的假设所有的测试结果我们都准确的以“成功”或“失败”进行了记录。如果成功的概率用p来表示(失败的概率就是1-p),那么在四次实验外的成功的概率是多少?
这个实验的结果集合可以用如下表示(下标表示第几次实验,S表示成功,F表示失败):

S 1 F 2 S 3 F 4 S_1F_2S_3F_4 S1F2S3F4表示“第一次沈工,第二次失败,第三次成功,第四次失败”。该结果的概率为 p ⋅ ( 1 − p ) ⋅ p ⋅ ( 1 − p ) = p 2 ⋅ ( 1 − p ) 2 p\cdot(1-p)\cdot p \cdot (1-p)=p^2\cdot (1-p)^2 p⋅(1−p)⋅p⋅(1−p)=p2⋅(1−p)2。注意在这四次实验中,四次都成功的方法只有1种,三次成功一次失败的方式有四种,两次成功两次失败的方式有6种,一次成功三次失败的方式有四种,全部失败的方式有一种。总的来说,对于n次实验,其中成功x次的方式为
C x n = n ! x ! ( n − x ) ! C_x^n=\frac{n!}{x!(n-x)!} Cxn=x!(n−x)!n!
它其实就是n个物体一次拿出x个的组合的数量。注意一共有 2 4 = 16 2^4=16 24=16个不同的结果。如果实验n次,每次结果要么是“成功”要么是“失败”,那么就应该会有 2 n 2^n 2n个结果。
让我们按照如下的方式进行分类:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6VWT3guE-1586708457762)(asserts/figureX-t2.png)]

考虑最后一列的各项。 4 p 3 ( 1 − p ) 4p^3(1-p) 4p3(1−p)表示四次实验中有3次成功的概率。四次实验中成功三次可以有四种方式,如果有3次成功,那么我们一定有一次失败。三次成功一次失败的概率是 p 3 ( 1 − p ) p^3(1-p) p3(1−p),因为有四种结果方式,因此最终的概率是 4 p 3 ( 1 − p ) 4p^3(1-p) 4p3(1−p)。最后一列的表达式表示二项分布的单独项,它的标准形式如下所示:
如果任意实验的成功概率是p,那么
P [ n 实 验 成 功 x 次 ] = C n x p x ( 1 − p ) n − x = b ( x ; n , p ) (X-1) P[n实验成功x次]=C^x_n p^x(1-p)^{n-x}=b(x;n,p) \tag{X-1} P[n实验成功x次]=Cnxpx(1−p)n−x=b(x;n,p)(X-1)
b ( x ; n , p ) b(x;n,p) b(x;n,p)表示概率密度形式的二项分布。概率密度形式会在后边的章节进行讨论。如果读者让n=4,且x的取值范围是0到4,将能看到从公式X-1中得到的前一个例子的概率列中的单独项。
在n次实验中最多获得X成功的概率,以及最少获得X项成功的概率,可以通过将对应的单独项相加来获得。
P [ n 次 实 验 最 多 成 功 x 次 ] = ∑ s = 0 x C n s P s ( 1 − p ) n − s ≡ B ( x ; n , p ) (X-2) P[n次实验最多成功x次]=\sum_{s=0}^{x}C^s_nP^s(1-p)^{n-s}\equiv B(x;n,p) \tag{X-2} P[n次实验最多成功x次]=s=0∑xCnsPs(1−p)n−s≡B(x;n,p)(X-2)
P [ n 次 实 验 最 少 成 功 x 次 ] = ∑ s = x n C n s p s ( 1 − p ) n − s = 1 − ∑ s = 0 x − 1 C n s P s ( 1 − p ) n − s (X-3) P[n次实验最少成功x次]=\sum_{s=x}^{n}C_n^sp^s(1-p)^{n-s}=1-\sum_{s=0}^{x-1}C_n^sP^s(1-p)^{n-s} \tag{X-3} P[n次实验最少成功x次]=s=x∑nCnsps(1−p)n−s=1−s=0∑x−1CnsPs(1−p)n−s(X-3)
其中,B(n;n,p)是累积分布形式里的二项分布(累积分布将会在后一个章节讨论)。在这个阶段,我们可以简单的解释二项式是成功次数小于等于某个值的概率。因此,回到我们的例子,四次实验中成功两次的概率是:
6 p 2 ( 1 − p ) + 4 p 3 ( 1 − p ) + p 4 = 1 − [ ( 1 − p ) 4 + 4 p ( 1 − p ) 3 ] 6p^2(1-p)^+4p^3(1-p)+p^4=1-[(1-p)^4+4p(1-p)^3] 6p2(1−p)+4p3(1−p)+p4=1−[(1−p)4+4p(1−p)3]
二项分布是一个非常大的表格,经常是公式X-2的形式但有时候会是公式X-3的形式,有时候是X-1的形式。可以查看参考资料【1】,【33】,【41】中的例子。
二项分布的统计平均值是np,方差是 n p ( 1 − p ) np(1-p) np(1−p)。平均值是分布位置的度量,而方差是分散程度的度量。这些知识会在随后的章节中讨论。
在使用二项式的过程中,我们已经做出了很多的假设。明确的列出这些假设非常重要。
- 每一次实验都有且只有两个实验结果。我们可以用“正常”“故障”来表示结果,也可以用其他的方式准确表示。
- 一共有n次随机试验,n是已经确定的数字。
- 所有n次实验完全独立。
- 成功的概率可以用p或者其他字母表示,p在实验的过程中是一个不变的常数。
非常重要的一点是,如果问题出现,并违反了上边一条或多条的假设,那么使用二项分布就是有疑问的,除非对违反的效果进行调查。事实上,所有的分布和所有的数学方程的特征都是基于一些假设和限制的,使用这些分布或方程涉及到这些假设和限制的相关方面。
现在让我们重新审视这些假设,假如说其中某一条假设并不成立,那么我们能做什么?我们来看几个违反这些假设的例子。
-
如果实验的结果不止一个会怎样?在某些测试方法中,会有三个可能的决策:接受批次,拒绝批次,继续实验。如果我们从装有白色、绿色、红色、黄色、蓝色芯片的容器内抽取一个芯片,每一次的实验结果会有5种可能性。这种案例不会构成严重问题,我们简单的用二项分布的扩展方法来取代二项分布,这个方法就是多项分布,该方法在很多统计著作中都有讲到(例如参考资料52)。如果适用,我们也可以将结果分类为“成功”与“失败”,并在更粗略的分类上使用二项式。(在这里“成功”的概率是所有归类为成功的事件的概率的和)
-
现在我们假设实验的次数n是未知的,但是知道成功的次数。例如,我们扔一个骰子直到扔出一个5.我们并不能事先知道我们要抛多少次。或者,我们可以去测试相似的继电器直到发现一个坏的,同样的,我们不知道需要测试多少次。在这种情况下,我们不能使用二项式,但是另一个和二项分布相关的分布是可以用的,它叫做“负二项分布”(参考资料13)。负二项分布 b ^ ( x ; k , p ) \hat{b}(x;k,p) b^(x;k,p)给出了进行到x个实验时第k次成功的概率。
b ^ ( x ; b , p ) = C x − 1 k − 1 p k ( 1 − p ) x − k (X-4) \hat{b}(x;b,p)=C_{x-1}^{k-1}p^k(1-p)^{x-k} \tag{X-4} b^(x;b,p)=Cx−1k−1pk(1−p)x−k(X-4) -
如果n次实验的结果是互相依存的(例如第x+1次的结果依赖于前x次的结果或可能与前面的结果有关),困难就会增加好多。需要各种条件概率表示。特定结果顺序概率依赖于发生的次序,每个不同的次序有不同的概率。举个例子,用二项分布来估计是否会下雨就是不可行的事情,因为天气模式一般会持续几天或几周,星期三是什么天气与星期二是什么天气有关。如果独立性存疑,则应该先进行独立性检查在应用二项分布解决问题(参考资料11)。
-
如果成功的概率在实验的进行过程中发生了变化,当实验的样本选自一个固定的范围且不拿出替换,这时我们能用超几何分布(hypergeometric distribution)解决该问题。这个分布的形式如下:
h ( x ; n , a , b ) = C a x C b n − x C a + b n (X-5) h(x;n,a,b)=\frac{C_a^xC_b^{n-x}}{C_{a+b}^n} \tag{X-5} h(x;n,a,b)=Ca+bnCaxCbn−x(X-5)
其中,a是总体中具有特征A的项目数量,b是总体中具有特征B的项目数量,N=(a+b)是总体或批次的大小,n是从总体中抽取样本的大小,x是样本中具有特征A的数量。
举个例子,特征A是有缺陷的,特征B是没有缺陷的。 h ( x ; n , a , b ) h(x;n,a,b) h(x;n,a,b)得出恰好n样本中有x个具备特征A的概率。
当从一个小数量总体中进行抽样且不替换时,必须应用超几何分布。(”小“表示N和n在数量上是同一级别的)。举个例子,如果我们接受了50个电感,其中10个有缺陷,那么有问题的部分就有五分之一,但是当我们抽取20个样本而不替换时,该比例会发生变化。
从公式X-5我们可以看出,使用超几何分布涉及到包含阶乘在内的复杂的计算,因为这个原因,二项式经常在此类问题中使用以获得近似的结果。二项分布能在 N ≥ 10 n N \geq 10n N≥10n(其中N是总体数量,n是抽样数量,一些作者认为这里应该是 N ≥ 8 n N \geq 8n N≥8n)时获得近似结果。在此类问题中, a / n a/n a/n近似等于 p p p。
一个应用二项分布的特殊例子,考虑如下的问题,ABC公司大量生产一个型号的电阻。以前的经验表明电阻的缺陷率是百分之一。因此,一个采样的缺陷概率 p = 0.01 p=0.01 p=0.01。如果从生产线上一次采样10个电阻,那么其中只有一个缺陷电阻的概率是多少?我们可以得出
x = 1 , n = 10 , p = 0.01 b ( x = 1 ; n = 10 , p = 0.01 ) = C 10 1 × 0.01 × 0.9 9 9 x=1,n=10,p=0.01 \\ b(x=1;n=10,p=0.01)=C_{10}^1 \times 0.01 \times 0.99^9 x=1,n=10,p=0.01b(x=1;n=10,p=0.01)=C101×0.01×0.999
如果二项式分布表可用,我们就可以简单的通过寻找B(1)-B(0)来评估,因为
B ( 1 ) = P [ 0 或 1 个 缺 陷 电 阻 ] B ( 0 ) = P [ 只 有 0 个 缺 陷 电 阻 ] B ( 1 ) − B ( 0 ) = 0.9957 − 0.9044 = 0.0913 \begin{aligned} &B(1)=P[0或1个缺陷电阻] \\ &B(0)=P[只有0个缺陷电阻] \\ &B(1)-B(0)=0.9957-0.9044=0.0913 \\ \end{aligned} B(1)=P[0或1个缺陷电阻]B(0)=P[只有0个缺陷电阻]B(1)−B(0)=0.9957−0.9044=0.0913
为了日后相似的计算,我们可以画一张10个抽样中含有 x = 0 , 1 , 2 , 3..10 x=0,1,2,3..10 x=0,1,2,3..10个故障电阻的概率的分布函数。该分布如图X-1所示,图X-1的曲线并不是十分合理,因为二项分布是离散的,但是这样连续插值可以更好的显示出分布的总体形状。

在可靠性和安全性评估中,如果每一个每一个冗余部件工作独立,且每个冗余部件都有(近似)同样的失效概率,那么二项分布是适用于该冗余系统的。举个例子,假设我们有一个n冗余部件,假设其中多于x个发生故障,则系统就会故障。该系统不发生故障的概率就是小于等于x个部件故障的概率,这正是二项累积概率 B ( x ; n , p ) B(x;n,p) B(x;n,p)。
或者,假设有一种情况中有n个可能发生的事件,倘若多于x件事情发生,则出现灾难。如果n件事情互相独立且发生概率相同。那么二项分布就是适用的。总的来说,当某事件重复n次,我们想直到其中某个结果出现x次,小于x次或者大于x次的概率时,二项分布就是适用的。这里的“n次实验“可以是n个部件,n年,n个系统或者其他适用的数量单位。
我们将短暂的返回二项分布,因为它的两个限制形式对我们很重要。我们将对其分布和分布参数进行讨论研究。
3. 累积分布函数(Cumulative Distribution Function)
让我们用X代表随机实验的可能结果。X经常用来表示随机变量,这个值可能会是离散(比如一个批次里边的数量)的或者连续的(比如重量,高度)。事实上,即使表面上是连续的变量,由于存在测量的分辨率,看起来连续的值也是一个离散变量。将这些量看成是连续的会让数学层面方便一些。用对应的小写字母x来表示一个随机量会更方便一些。
在这里我们需要展现的基本公式将以连续值的形式给出,在需要给出连续值与离散值的不同的地方,我们会加以说明。总的来说,在操作上是用求和富豪来代替整数符号的问题。在累积分布方程中用于表示概率形式的 F ( x ) F(x) F(x)里,我们一般表示X的值要小于等于x的值。
F ( x ) = P [ X ≤ x ] (X-6) F(x)=P[X \leq x] \tag{X-6} F(x)=P[X≤x](X-6)
根据公式X-6,因为F(x)是个概率,因此
0 ≤ F ( x ) ≤ 1 0\leq F(x) \leq 1 0≤F(x)≤1
如果X的取值范围是负无穷到正无穷,那么
F ( − ∞ ) = 0 F ( + ∞ ) = 1 F(-\infty) =0 \\ F(+\infty) =1 \\ F(−∞)=0F(+∞)=1
如果X有更小的限定 x 1 < X < x u x_1
F ( x 1 ) = 0 F ( x u ) = 1 F(x_1)=0 \\ F(x_u)=1 F(x1)=0F(xu)=1
F(x)有个很重要的性质是随着x的增加,它的值是不会减小的。在严格的数学含义上,它是一个非减函数,但是不一定单调。它可以更简洁的表示如下:
If x 2 > x 1 x_2>x_1 x2>x1, then F ( x 2 ) ≥ F ( x 1 ) F(x_2)\geq F(x_1) F(x2)≥F(x1)
一个更重要的性质如公式X-7所示:
P [ x 1 ≤ X ≤ x 2 ] = F ( x 2 ) − F ( x 1 ) (X-7) P[x_1 \leq X \leq x_2]=F(x_2)-F(x_1) \tag{X-7} P[x1≤X≤x2]=F(x2)−F(x1)(X-7)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oqkWE3Xc-1586708457765)(asserts/figureX-2.png)]

我们在第二节遇到的二项累积分布B(x;n,p)是F(x)一种特殊形式。F(x)连续和离散变量的标准形式如图X-2所示。
我们展现在上边方程中的累积分布函数的性质对离散和连续随机变量是有效的。
举一个随机变量和对应的累积分布的例子,在一个随机试验中,我们观察一个单独的器件的故障次数。每当该部件故障,我们就修好它,将时间t归0,并记录下次故障的时间。

我们假设维修并不会改变部件故有性质,也就是说每次维修都会让部件回到初始状态。随机变量T是初始化或维修后到发生故障的时间。我们用 t i t_i ti来表示T的特定值。累积分布 F ( t ) F(t) F(t)用来表示任意给定故障时间少于或等于t的概率。
另一个例子,我们针对某样物体进行反复的测量。随机变量X表示测量结果, x i x_i xi表示某次测量结果。累积分布F(x)表示测量值小于或者等于x的概率。我们能从 F e s t ( x i ) F_{est}(x_i) Fest(xi)来估计 F ( x ) F(x) F(x),其中
F e s t ( x i ) = n i n F_{est}(x_i)=\frac{n_i}{n} Fest(xi)=nni
n是测量的总次数, n i n_i ni是测量的X小于等于 x i x_i xi的测量次数,随着n不断的变大, F e s t ( x i ) F_{est}(x_i) Fest(xi)也在不断的接近 F ( x i ) F(x_i) F(xi)。在应用中,累积分布函数必须根据理论思考来确定,或者通过统计方法估算。
4. 概率密度函数(probability Density Function)
对于连续随机变量,概率密度函数(probablity desity function,简称pdf),f(x),可以通过F(x)微分的方式获取。
f ( x ) = d d x F ( x ) (X-8) f(x)=\frac{d}{dx}F(x) \tag{X-8} f(x)=dxdF(x)(X-8)
它的等效形式是
F ( x ) = ∫ − ∞ x f ( y ) d y (X-9) F(x)=\int_{-\infty}^{x}f(y)dy \tag{X-9} F(x)=∫−∞xf(y)dy(X-9)
因为f(x)是非递减函数的斜率,我们有
f ( x ) ≥ 0 (X-10) f(x) \geq 0 \tag{X-10} f(x)≥0(X-10)
若概率函数在整个范围内进行积分,那么结果是统一的。
∫ − ∞ ∞ f ( x ) d ( x ) = 1 (X-11) \int_{-\infty}^{\infty}f(x)d(x)=1 \tag{X-11} ∫−∞∞f(x)d(x)=1(X-11)
f ( x ) f(x) f(x)的性质使得我们可以把其下的区域看成概率。
概率密度的基本含义可以用公式X-12表示:
f ( x ) d x = P [ x < X < x + d x ] (X-12) f(x)dx=P[x
我们前边的公式X-7可以用另外一种特别有用的形式表示:
P [ x 1 ≤ X ≤ x 2 ] = ∫ x 1 x 2 f ( x ) d x (X-13) P[x_1\leq X \leq x_2]=\int_{x_1}{x_2}f(x)dx \tag{X-13} P[x1≤X≤x2]=∫x1x2f(x)dx(X-13)
f(x)的标准形状阐述于图X-3,其中a是一个对称分布,b是一个向右倾斜的分布,c是向左倾斜的分布。(在图中,x增加相当于图形右移)。
在持续变量的情况下,概率必须用区间表示。这是因为对于指定的x值的概率一直等于0,因为在任意区间中有无数个X的值。因此 f ( x ) d x f(x)dx f(x)dx是目标落在x和x+dx区间的数量的概率。当然,dx的区间长度应该尽可能的小。f(x)本身也就是单位区间的概率。在这个例子中,我们用加法符号来替代积分符号,将所有目标区间的x的概率加起来。公式X-13将适用于所有离散的X。
在先前故障案例中, f ( t ) d t f(t)dt f(t)dt给出了部件在t和t+dt之间发生故障的概率。在测量的例子中,f(x)dx给出了测量结果位于x和x+dx之间的概率。从经验角度出发,如果我们考虑大量的测量,f(x)dx可以用以下公式进行估计
f ( x ) δ x = δ n i n f(x)\delta x= \frac{\delta n_i}{n} f(x)δx=nδni
这里n是测量的总次数, δ n i \delta n_i δni是X位于x和 x + δ x x+\delta x x+δx之间的数量。
5。 分布参数和矩
特定概率密度函数的特征是通过分布参数描述的。一类参数用于沿着横坐标定位分布。因此,像这类的参数被称作位置参数(location parameter)。
最常见的位置参数是统计平均数。其他常用到的位置参数有:中值(median)(50%在概率密度曲线下方的区域在中值的左边;另50%在右边);模(mode),位于概率曲线的最大值或“峰值”上(在二项分布或三项分布中,可能会没有最大值或有多个最大值的情况);中列数(mid-range),当变量在有限的区间内,它是最大值和最小值的平均值,除此之外,其他的都不很重要。图X-4展示这些概念。

在(a)中,中值用 x . 50 x_{.50} x.50表示。从中值的定义中可以看出,50%的次数结果将会小于等于 x . 50 x_{.50} x.50,而50%的次数,将会大于。因此 P ( x ≤ x . 50 ) = . 50 P(x\leq x_{.50})=.50 P(x≤x.50)=.50,根据累积分布, F ( x . 50 ) = . 50 。 中 值 是 F(x_{.50})=.50。中值是 F(x.50)=.50。中值是\alpha 百 分 数 的 特 殊 例 子 , 百分数的特殊例子, 百分数的特殊例子,x_\alpha 定 义 为 F ( x α ) = α 定义为F(x_\alpha)=\alpha 定义为F(xα)=α,例如,90%百分数是 F ( x . 90 ) = . 90 F(x_{.90})=.90 F(x.90)=.90,90%的次数中结果中的x数值将会小于等于 x . 90 x_{.90} x.90。
在(b)中,模是用 x m x_m xm表示,给出了最大概率的结果的值。在©中,我们看到如何从两个极值中得出中列数。
均值(average)也被成为平均值(mean)或期望值(expected value)。如果我们重复做相同的随机实验,对结果取平均值。那么这个实际平均值会随着实验次数的增加越来越接近理论平均值。(我们假设分布存在平均值,这样实验平均值会越来越趋向于总体平均值)
在图X-3(a)中那样的对称分布的情况下,均值,中值和模是统一的。对于倾斜的分布,如图X-3(c),中值将落于模和均值之间。在图X-5中,这两个对称分布图形有着相同的均值,中值和模。但是对于中心聚集程度的角度来看,它们却是不一样的。用来描述这分布这方面的参数叫分散参数(dispersion parameters)。其他和这个类似的参数还有方差(variance)、方差的开方和标准差(standard deviation)。其他分散参数比较少用到,是种植绝对偏差(median absolute deviation),范围在上限值和下限值之间。我们将会在后一章里边计算方差。
事实上,还有很多其他的分布参数,我们这里涉及到的都是一些基本的参数。当累积概率分布的形式确定后,我们必须掌握计算分布参数的具体方法。这些通用方法中的一些方法需要计算分布中的矩,并且在理论统计中十分重要。分布的矩可以在任意指定点上计算,但是我们限制只在(a)中计算原点的矩,(b)中计算均值的矩。
(a) 原点的矩
第一个关于原点的矩被定义如下:
μ 1 ′ = ∫ − ∞ + ∞ x f ( x ) d x (X-14) \mu _1 ' = \int_{-\infty}^{+\infty}xf(x)dx \tag{X-14} μ1′=∫−∞+∞xf(x)dx(X-14)
它表示X的平均或期望值,用 E [ X ] E[X] E[X]表示。我们使用 μ \mu μ来简单的表示均值,因为 E [ X ] = μ E[X]=\mu E[X]=μ。
第二个关于原点的矩被定义如下:
μ 2 ′ = ∫ − ∞ + ∞ x 2 f ( x ) d x (X-15) \mu _2 '=\int_{-\infty}^{+\infty}x^2f(x)dx \tag{X-15} μ2′=∫−∞+∞x2f(x)dx(X-15)
他表示 X 2 X^2 X2的期望值, E [ X 2 ] E[X^2] E[X2]。
总而言之,第n个关于原点的矩是
μ n ′ = ∫ − ∞ + ∞ x n f ( x ) d x (X-16) \mu _n '=\int_{-\infty}^{+\infty}x^nf(x)dx \tag{X-16} μn′=∫−∞+∞xnf(x)dx(X-16)
表示 X n X^n Xn的期望, E [ X n ] E[X^n] E[Xn]
如果 Y = g ( X ) Y=g(X) Y=g(X)是任意关于X的函数,X是根据概率密度函数f(x)的分布, g ( X ) g(X) g(X)的期望可以通过如下方式获得:
E [ Y ] = E [ g ( X ) ] = ∫ − ∞ + ∞ g ( x ) f ( x ) d x (X-17) E[Y]=E[g(X)]=\int_{-\infty}^{+\infty}g(x)f(x)dx \tag{X-17} E[Y]=E[g(X)]=∫−∞+∞g(x)f(x)dx(X-17)
(b)均值的矩
第一个关于均值的矩定义如下:
μ 1 = ∫ − ∞ + ∞ ( x − μ ) f ( x ) d x (X-18) \mu_1=\int_{-\infty}^{+\infty}(x-\mu)f(x)dx \tag{X-18} μ1=∫−∞+∞(x−μ)f(x)dx(X-18)
因为它总是等于0,所以并没有什么用处。
第二个关于均值的矩的定义如下:
μ 2 = ∫ − ∞ + ∞ ( x − μ ) 2 f ( x ) d x (X-19) \mu_2=\int_{-\infty}^{+\infty}(x-\mu)^2f(x)dx \tag{X-19} μ2=∫−∞+∞(x−μ)2f(x)dx(X-19)
它表示了方差 σ 2 \sigma ^2 σ2或者$E[(X-\mu)^2f(x)dx]。总的来说,均值的第n个矩定义如下:
μ n = ∫ − ∞ + ∞ ( x − μ ) n f ( x ) d x (X-20) \mu_n=\int_{-\infty}^{+\infty}(x-\mu)^nf(x)dx \tag{X-20} μn=∫−∞+∞(x−μ)nf(x)dx(X-20)
表示 E [ ( X − μ ) n ] E[(X-\mu)^n] E[(X−μ)n]。
有一个非常有用的关系:
μ 2 = μ 2 ′ − ( μ 1 ′ ) 2 (X-21) \mu_2=\mu_2'-(\mu_1')^2 \tag{X-21} μ2=μ2′−(μ1′)2(X-21)
公式21允许我们通过评估X-15中的积分,而不是X-19中更复杂的积分来计算方差。公式21可以通过如下方式得到轻易的证明:
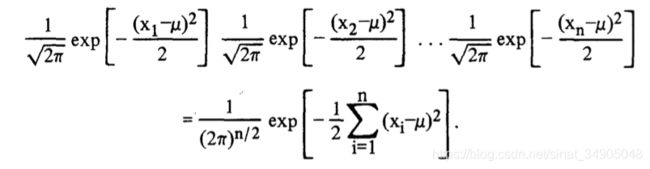
在离散随机变量的情况下,原点的第一个矩表示为:
μ = μ 1 ′ = ∑ i = 1 n X i p ( x i ) (X-22) \mu=\mu_1 ' =\sum_{i=1}^n X_i p(x_i) \tag{X-22} μ=μ1′=i=1∑nXip(xi)(X-22)
这里 p ( x i ) p(x_i) p(xi)是 x i x_i xi的概率,最常用的寻找n个值的平均值的方程如下:
x ^ = 1 n ∑ i = 1 n x i \hat{x}=\frac{1}{n}\sum_{i=1}^n x_i x^=n1i=1∑nxi
这是公式22应用的特殊情况,每个值都被认为拥有同样的出现的概率 1 n \frac{1}{n} n1。
例如,对于单一的骰子,我们有
μ = μ ′ = 1 + 2 + 3 + 4 + 5 + 6 6 = 3.5 \mu=\mu '=\frac{1+2+3+4+5+6}{6}=3.5 μ=μ′=61+2+3+4+5+6=3.5
尽管实际上不会出现这样的结果,但是期望值是3.5.
同样的,如果随机变量是离散的,那么第二个均值的矩的形式如下:
μ 2 = ∑ i = 1 n ( x i − μ ) 2 p ( x i ) (X-23) \mu _2=\sum_{i=1}{n}(x_i-\mu)^2p(x_i) \tag{X-23} μ2=i=1∑n(xi−μ)2p(xi)(X-23)
在所有 x i x_i xi都有同样的“权重”1/n的情况下,公式X-23可以简化成计算n个读书采样的方差的采样等式:
s 2 = 1 n ∑ i = 1 n ( x i − x ^ ) 2 (X-24) s^2=\frac{1}{n}\sum_{i=1}{n}(x_i-\hat{x})^2 \tag{X-24} s2=n1i=1∑n(xi−x^)2(X-24)
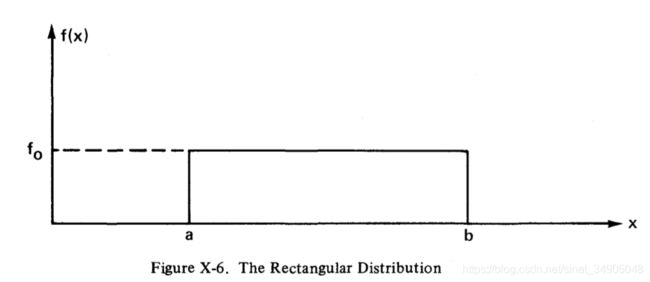
我们用一个应用分布矩的简单例子来总结这一节的内容。参考如图X-6那样的矩形概率密度函数,它在a和b中的任何值基本都是相等的,因为都相等,所以 f ( x ) = f 0 f(x)=f_0 f(x)=f0。因此,这个概率密度函数的积分应该是1,我们有:
A r e a = f 0 ( b − a ) = 1 Area=f_0(b-a)=1 Area=f0(b−a)=1,于是 f 0 = 1 b − a f_0=\frac{1}{b-a} f0=b−a1。
分布的均值(期望)计算如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cVvsse9F-1586708457771)(asserts/equationX-2.png)]
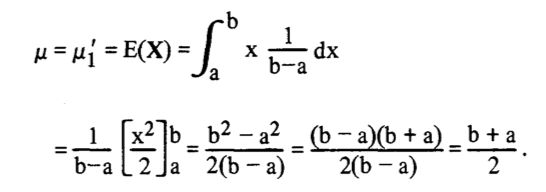
分布的方差计算如下:
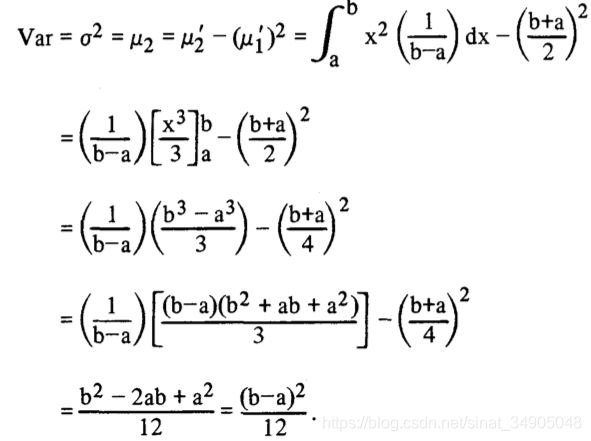
10.6 二项式的极限形式:正态分布和泊松分布
有一些很重要的分布是二项分布的极限形式。例如:
lim n → ∞ [ C n x p x ( 1 − p ) n − x ] \lim_{n\to \infty}[C_n^x p^x(1-p)^{n-x}] n→∞lim[Cnxpx(1−p)n−x]
上面的式子是p是固定的,n趋近于无穷的一种极限形式。省略数学细节,该过程会转换成著名的正态分布形式:高斯分布。
f ( x ; μ , σ ) = 1 2 π σ e x p [ − 1 2 ( x − μ σ ) 2 ] (X-25) f(x;\mu,\sigma)=\frac{1}{\sqrt{2\pi}\sigma}exp[-\frac{1}{2}(\frac{x-\mu}{\sigma})^2] \tag{X-25} f(x;μ,σ)=2πσ1exp[−21(σx−μ)2](X-25)
这里 μ \mu μ和 σ \sigma σ是平均值和标准差。正态分布已经广泛的应用表格进行处理,但不是X-25那样的形式。X-25那样的表格需要对 μ \mu μ和 σ \sigma σ进行广泛的覆盖,这将使得表格过于臃肿而降低可用性。找到一种转换形式,将 μ \mu μ和 σ \sigma σ标准化,变成0和1,这是有可能的。这种转换是:
z = x − μ σ (X-26) z=\frac{x-\mu}{\sigma} \tag{X-26} z=σx−μ(X-26)
对应的基于z的表现形式为
f ( z ) = 1 2 π e − z 2 / 2 (X-27) f(z)=\frac{1}{\sqrt{2\pi}}e^{-z^2/2} \tag{X-27} f(z)=2π1e−z2/2(X-27)
这个式子被叫做标准正态分布,它是所有正态分布表格的基本形式。
读者注意到,从公式X-25经由公式X-26到公式X-27,并不是一个简单的替换的过程。这个变换用到了转换的雅克比式(参考【25】)。在这个例子中,雅克比式是 σ \sigma σ,这里抵消了 1 / ( 2 π σ ) 1/(\sqrt{2\pi}\sigma) 1/(2πσ)中的 σ \sigma σ。 f ( z ) f(z) f(z)的图形如图X-7所示:
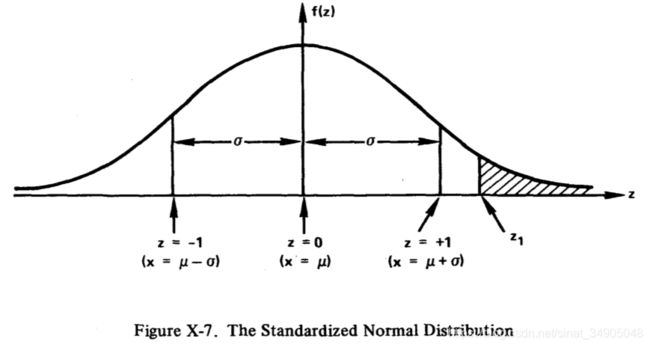
这里列举了一些标准正态分布的几个特征。其中我们最感兴趣的是曲线之下横轴上的两个点之间的部分。读者应该还记得这样的区域可以当成一个概率,因为曲线下的所有区域之和是一致的。假设存在一个点 z 1 z_1 z1,一些表格记录了从 z 1 z_1 z1到 + ∞ +\infty +∞的曲线下的区域(图中的阴影部分);一些表格记录了从 z 1 z_1 z1到 − ∞ -\infty −∞的曲线下的区域,还有一些表格记录了从 z 1 z_1 z1到原点的曲线下的区域。当然,在智能的使用表格之前,必须确认要制表的区域。
对于正态分布,对于原始的变量X, σ \sigma σ衡量了平均值 μ \mu μ到曲线拐点的距离,概率密度曲线从 μ − σ \mu-\sigma μ−σ到 μ + σ \mu+\sigma μ+σ的区域约等于0.68,从 μ − 2 σ \mu-2\sigma μ−2σ到 μ + 2 σ \mu+2\sigma μ+2σ约等于是0.95.
这里假设读者已经熟悉正态分布和它的表格。尽管如此,我们还是给出一个简答的数学实例,有经验的可以略过。锻件中的槽的宽度符合正态分布,它的均值 μ \mu μ等于0.900英寸,标准差 σ \sigma σ等于0.0030英寸。如果说明书中的限制(允许误差)为 0.9000 ± 0.0050 0.9000\pm 0.0050 0.9000±0.0050,占有总产出多少百分比的数将被拒绝?拒绝的锻件是其宽度数值是在图中阴影部分的那些。

对于x=0.9050的z值为
z = 0.9050 − 0.9000 0.0030 = 1.67 z=\frac{0.9050-0.9000}{0.0030}=1.67 z=0.00300.9050−0.9000=1.67
从标准正态表格可以得出,右边的尾巴区域在 P [ Z ≥ 1.67 ] P[Z\geq 1.67] P[Z≥1.67]等于0.0475。这是 X ≥ 0.9050 X\geq 0.9050 X≥0.9050的概率。由于图形是对称的,所以左边的尾巴区域也是0.0475.所以两边尾巴加在一起的就是0.0950.这就是一个零件宽度在说明书外的概率。因此,9.5%就是零件被退回的概率。
这个退回率相当高。如果说明书不做更改,我们可以通过认真工作,降低 σ \sigma σ来降低退回率。假设我们的目标退回率是1/1000=0.001,那么最大允许的退回率 σ \sigma σ,这里记为 σ ′ \sigma ' σ′,应该是多少?
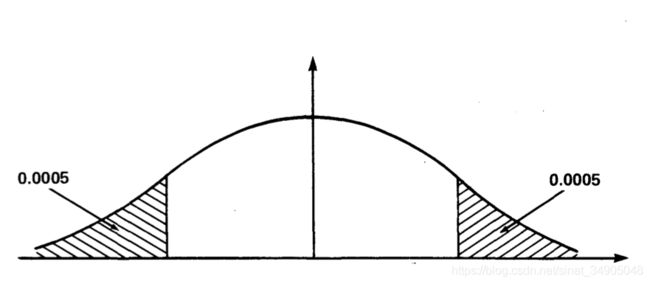
如果退回率是0.001,则每个尾巴上的区域必须是0.001/2=0.0005。从表格中得出,截去0.0005区域尾巴的z的值是3.3。从 z = ( x − μ ) / σ z=(x-\mu)/\sigma z=(x−μ)/σ我们可以得出 σ ′ = ( x − μ ) / z \sigma '=(x-\mu)/z σ′=(x−μ)/z,
因此 σ ′ = 0.9050 − 0.9000 3.3 = 0.00152 英 寸 \sigma '=\frac{0.9050-0.9000}{3.3}=0.00152英寸 σ′=3.30.9050−0.9000=0.00152英寸。
因此,对于0.001的退回率,最大允许 σ \sigma σ的值是0.00152英寸。
我们研究正态分布有很多种理由。其中之一就是根据中心极限定理,不管每个测量的分布如何,大量的测量的均值就趋近于正态分布。另一个理由是正态分布为许多消耗模型提供了相当好的统计模型。
从系统和可靠性分析的角度出发,另一种重要的形式是以下二项分布的极限形式:
lim n → ∞ p → 0 { C n x p x ( 1 − p ) n − x } (X-28) \lim_{n\to \infty \\ p\to 0}\{C_n^xp^x(1-p)^{n-x}\} \tag{X-28} n→∞p→0lim{Cnxpx(1−p)n−x}(X-28)
在公式X-28中,这个极限采用了这样一种形式来使得np保持有限。这个极限过程的结果为
( n p ) x x ! e − n p = m x m ! e − m (X-29) \frac{(np)^x}{x!}e^{-np}=\frac{m^x}{m!}e^{-m} \tag{X-29} x!(np)xe−np=m!mxe−m(X-29)
这里m=np。(这个数学过程可以在很多参考资料中找到,例如参考【32】,45-46页)
公式29给出了稀有事件( p → 0 p\to 0 p→0)在大量试验下( n → ∞ n \to \infty n→∞),精确的x的发生概率。事件预期的发生次数是 n p = m np=m np=m。公式X-29的分布就是泊松分布。如同矩的方法展示(虽然有更简单的方法),泊松分布的均值和方差在数值上都等于m。
即使p不是特别小,n也不是特别大,泊松分布还是能很好的近似二项分布。举个例子,假设在批量生产过程中遇到不合格产品的概率是0.1(即p=0.1),那么在一批次10个零件中(n=10)发现不合格产品正好是1个的概率是多少?准确的数值可以通过二项分布得到
b ( 1 ; 10 , 0.1 ) = 0.3874 b(1;10,0.1)=0.3874 b(1;10,0.1)=0.3874
泊松分布可以得到近似结果为0.3679,于实际值相差不大。如果我们提高批次的数量到20(n=20),则结果更加接近:二项分布为0.2702,泊松分布为0.2707.
泊松分布非常重要,不仅因为它能近似计算二项分布,而且它能描述很多稀有事件的性质,而不论其潜在的物理过程如何。泊松分布在描述稳态系统组件或系统的故障发生方面还有很多应用。我们将在后边的章节描述这些系统应用方式。
10.7 针对系统故障的泊松分布应用——指数分布
假设我们有一个稳态系统,它不在燃烧或损耗状态。我们进一步假设,当它失效时,它会恢复到初始状态,维修的时间可以忽略。我们的关注点是系统故障。我们着重关注系统出现故障的次数为0次的概率。因此,在泊松分布中,我们在公式X-29中令x=0。其结果是:
P [ 系 统 故 障 次 数 为 0 ] = e − m P[系统故障次数为0]=e^{-m} P[系统故障次数为0]=e−m
其中,m为大量的实验中系统预期的故障数。
现在,就系统失效而言,我们关注的参数是时间。因此我们要寻找如何用时间来表达m。这件事很简单。
假设我们有系统的数据,平均每50小时系统就会故障。我们说故障的平均时间( θ \theta θ)就是50小时。如果我们让系统工作100小时,我们预计会遇到两次失败,因为100/50=2。采用符号t表示工作时间,我们有
时 间 t 内 我 们 预 计 的 故 障 次 数 = t / θ = λ t 时间t内我们预计的故障次数=t/\theta=\lambda t 时间t内我们预计的故障次数=t/θ=λt,这里 λ = 1 / θ \lambda = 1/\theta λ=1/θ。
但是m为预计的故障次数。因此
P [ 系 统 故 障 0 次 ] = e − m = e t / θ = e λ t P[系统故障0次]=e^{-m}=e^{t/\theta}=e^{\lambda t} P[系统故障0次]=e−m=et/θ=eλt。
现在,系统的可靠性,R(t)通过时间t内持续正常工作的概率来定义。因此我们有:
R ( t ) = e − t / θ = e − λ t (X-30) R(t)=e^{-t/\theta}=e^{-\lambda t} \tag{X-30} R(t)=e−t/θ=e−λt(X-30)
时间t之前系统出现故障的概率由累计分布函数F(t)给出。系统可能在时间t前失效或者不失效,因此我们有
R ( t ) = e − λ t = 1 − F ( t ) R(t)=e^{-\lambda t}=1-F(t) R(t)=e−λt=1−F(t)
以及
F ( t ) = 1 − e − λ t (X-31) F(t)=1-e^{-\lambda t} \tag{X-31} F(t)=1−e−λt(X-31)
有关公式X-31的概率密度函数现在可以轻易的得出
f ( t ) = d d t F ( t ) = d d t ( 1 − e − λ t ) f ( t ) = λ e − λ t (X-32) f(t)=\frac{d}{dt}F(t)=\frac{d}{dt}(1-e^{-\lambda t}) \\ f(t)=\lambda e^{-\lambda t} \tag{X-32} f(t)=dtdF(t)=dtd(1−e−λt)f(t)=λe−λt(X-32)
公式X-32中的概率密度函数通常指的是“失效时间的指数分布”。公式X-30在某些时候简称是实数分布。
公式X-30,X-31,X-32给出的可靠性、累计分布、概率密度函数,在系统分析和可靠性方面用处非常广泛。原因很简单,指数分布是个非常简单的分布。只有一个参数(故障率或故障平均时间)必须通过经验确定。但是我们必须十分小心的应用公式X-30来计算系统可靠性。因为公式X-30来自于泊松分布。而后者是二项分布的极限形式。二项分布被我们在前一章所列举的很多假设所限制。在极限过程中一些假设被修改。但其中之一并没有涉及。这个假设就是所有的实验都是互相独立的。换句话说,一个实验就是在某个时间段有机会发生故障。
当系统故障是可修复的,我们关于独立实验的假设。解释如下。在未来某时段故障的概率是一个只和时间段长度有关的函数,和过去的故障次数无关。如果系统是不可修复的。则我们的假设需要更改成如下的形式:没有先前的故障,对于不可修复的部件,如果我们在一个靠前的时间出现了一次故障,那么在某一个后边时刻,它的已发生故障的概率是1,后续发生故障的概率是0,以为事件已经发生了。
表征故障过程的另一种方法如下。对于指数分布,到时间t还没有出现故障,那么在(t,t+ δ t \delta t δt)时段中发生故障的概率和同样时间长度的其他时段概率是相等的(到该时段还未发生故障)。它和(0, δ t \delta t δt)时间段的故障概率是相同的。因此,因为我们从t=0开始运行系统,在时间t上我们的系统“和新的一样”,这是指数分布的另外一种描述。
如果我们从假设出发——在特定时间段里故障的概率是一个只和时间段的长度有关的函数,我们能单独从这个假设中得到指数分布。假设一个不可修复的系统,他能存在于两种状态之一: E 1 E_1 E1为系统工作, E 0 E_0 E0为系统故障。我们定义
P 1 ( t ) = 在 时 间 t 系 统 在 E 1 状 态 的 概 率 P 0 ( t ) = 在 时 间 t 系 统 在 E 0 状 态 的 概 率 P_1(t)=在时间t系统在E_1状态的概率 \\ P_0(t)=在时间t系统在E_0状态的概率 P1(t)=在时间t系统在E1状态的概率P0(t)=在时间t系统在E0状态的概率
假设开始时系统处于 E 1 E_1 E1状态.
现在 P 1 ( t + δ t ) P_1(t+\delta t) P1(t+δt)表示系统在 t + δ t t+\delta t t+δt时系统处于状态E1的概率。我们有
P 1 ( t + δ t ) = P 1 ( t ) [ 1 − λ δ t ] = P 1 ( t ) − P 1 ( t ) λ δ t P_1(t+\delta t)=P_1(t)[1-\lambda \delta t]=P_1(t)-P_1(t)\lambda \delta t P1(t+δt)=P1(t)[1−λδt]=P1(t)−P1(t)λδt
这里,根据我们开始的假设(系统故障概率只和时间段的长度有关), λ δ t \lambda \delta t λδt给出的系统在时间段 δ t \delta t δt中从状态E1到E0的转换概率, λ \lambda λ是一个常数(失效率)。因此 ( 1 − λ δ t ) (1-\lambda \delta t) (1−λδt)表示系统在 δ t \delta t δt时刻没有从E1到E0的概率。代数重排产生了如下的差分方程。
P 1 ( t + δ t ) − P 1 ( t ) δ t = − λ P 1 ( t ) \frac{P_1(t+\delta t)-P_1(t)}{\delta t}=-\lambda P_1(t) δtP1(t+δt)−P1(t)=−λP1(t)
如果我们让时间段的长度接近0,根据定义,方程左边的极限形式就是 P 1 ( t ) P_1(t) P1(t)关于t的导数。
lim δ t → 0 [ P 1 ( t + δ t ) − P 1 ( t ) δ t ] = d d t P 1 ( t ) = P 1 ′ ( t ) = − λ P 1 ( t ) \lim_{\delta t \to 0}[\frac{P_1(t+\delta t)-P_1(t)}{\delta t}]=\frac{d}{dt}P_1(t)=P_1 '(t)= -\lambda P_1(t) δt→0lim[δtP1(t+δt)−P1(t)]=dtdP1(t)=P1′(t)=−λP1(t)
这是关于时间微分的主要观点,是由牛顿提出。我们现在有了微分方程:
P 1 ′ ( t ) = − λ P 1 ( t ) P_1'(t)=-\lambda P_1(t) P1′(t)=−λP1(t)
如果我们记得限制条件 P 1 ( t = 0 ) = 1 P_1(t=0)=1 P1(t=0)=1,则这很容易整合。
d [ P 1 ( t ) ] P 1 ( t ) = − λ d t [ l n P 1 ( t ) ] 0 t = [ − λ t ] 0 t l n P 1 ( t ) − l n 1 = − λ t P 1 ( t ) = e − l a m b d a t \begin{aligned} &\frac{d[P_1(t)]}{P_1(t)}=-\lambda dt \\ &[ln\ P_1(t)]^t_0=[-\lambda t]_0^t \\ & ln \ P_1(t)-ln 1=-\lambda t &P_1(t)=e^{-lambda t} \end{aligned} P1(t)d[P1(t)]=−λdt[ln P1(t)]0t=[−λt]0tln P1(t)−ln1=−λtP1(t)=e−lambdat
这正是系统的可靠性,因为 P 0 ( t ) + P 1 ( t ) = 1 P_0(t)+P_1(t)=1 P0(t)+P1(t)=1,我们有
P 0 ( t ) = 1 − e − λ t = 1 − R ( t ) = F ( t ) P_0(t)=1-e^{-\lambda t}=1-R(t)=F(t) P0(t)=1−e−λt=1−R(t)=F(t)
对应的概率密度函数是
f ( t ) = λ e − λ t f(t)=\lambda e^{-\lambda t} f(t)=λe−λt
我们认识到这是指数分布。
10.8 失效率函数
上一章中
F ( t ) = P [ t 之 前 发 生 故 障 的 ] F(t)=P[t之前发生故障的] F(t)=P[t之前发生故障的]
f ( t ) d t = P [ t 和 t + d t 之 间 发 生 故 障 ] f(t)dt=P[t和t+dt之间发生故障] f(t)dt=P[t和t+dt之间发生故障]
我们现在定义一个条件概率, λ ( t ) \lambda(t) λ(t),叫做失效率函数(failure rate function)
λ ( t ) d t = P [ 故 障 在 t 和 t + d t 间 发 生 ∣ 先 前 没 有 发 生 故 障 ] (X-33) \lambda (t)dt=P[故障在t和t+dt间发生|先前没有发生故障] \tag{X-33} λ(t)dt=P[故障在t和t+dt间发生∣先前没有发生故障](X-33)
对于任意常规分布,有一个重要的性质:
λ ( t ) = f ( t ) 1 − F ( t ) (X-34) \lambda (t)=\frac{f(t)}{1-F(t)} \tag{X-34} λ(t)=1−F(t)f(t)(X-34)
该式证明如下.
我们用T来表示失效发生的时间。T是一个随机变量,定义如下:
λ ( t ) d t = P [ t < T < t + d t ∣ t < T ] \lambda (t)dt=P[t
让我们用(t
因此
λ ( t ) d t = P [ ( t < T < t + d t ) ⋂ ( t < T ) ] P ( t < T ) \lambda (t)dt=\frac{P[(t
现在事件A是事件B的一个特例。当A发生,则B自动发生,在集合理论中,A是B的一个子集,在这些条件下, A ⋂ B = A A\bigcap B=A A⋂B=A。于是
λ ( t ) d t = P [ t < T < t + d t ] P ( t < T ) = P [ A ] P [ B ] = f ( t ) d t 1 − F ( t ) \lambda (t)dt=\frac{P[t
最终
λ ( t ) = f ( t ) 1 − F ( t ) \lambda(t)=\frac{f(t)}{1-F(t)} λ(t)=1−F(t)f(t)
这也就是公式X-34.
如果我们为一个系统画出关于时间的 λ ( t ) \lambda (t) λ(t),则曲线如图X-8所示。这个曲线呈现浴缸的样子。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-txmufdU3-1586708457778)(asserts/figureX-8.png)]
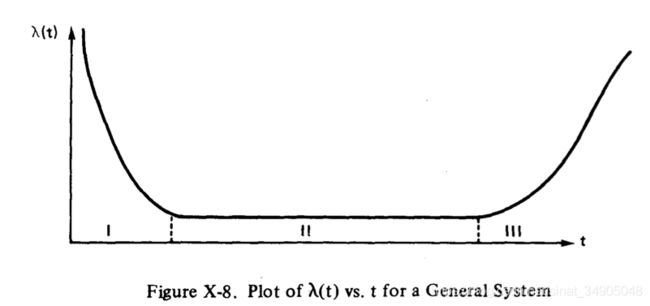
图8的曲线可以分成I,II,III的三部分。I区被称为“婴儿死亡率区域”,这个区域很难确定分布。适合这部分曲线的分布可能取决于系统本身的特性。制造商经常要对产品进行老化测试,以降低批量产品运送给顾客前的早期故障。II区对应“一个常数故障率”,是指数分布适用的机会失败区域。区域III对应磨损过程,正态分布经常为此提供一个适当的模型。对于一个真实的系统, λ ( t ) − t \lambda (t) - t λ(t)−t曲线经常与图X-8的描述差异较大。例如,区域II的指数分布经常整个消失,或者老化区域是可以忽略的。
返回故障率方程,可以很方便的对X-34的F(t)和f(t)求解。通过以下形式改写X-34来完成。
λ ( t ) d t = [ − F ′ ( t ) d t ] 1 − F ( t ) (X-35) \lambda (t)dt=\frac{[-F'(t)dt]}{1-F(t)} \tag{X-35} λ(t)dt=1−F(t)[−F′(t)dt](X-35)
其中 F ′ ( t ) = d F ( t ) d t F'(t)=\frac{dF(t)}{dt} F′(t)=dtdF(t).
对X-35两边取积分,得到
− ∫ 0 t λ ( x ) d x = l n [ 1 − F ( t ) ] -\int_0^t \lambda(x)dx=ln[1-F(t)] −∫0tλ(x)dx=ln[1−F(t)]
它等效于
1 − F ( t ) = e x p [ − ∫ 0 t λ ( x ) d x ] 1-F(t)=exp[-\int_0^t\lambda (x)dx] 1−F(t)=exp[−∫0tλ(x)dx]
因此 F ( t ) = 1 − e x p [ − ∫ 0 t λ ( x ) d x ] (X-36) F(t)=1-exp[-\int_0^t\lambda (x)dx] \tag{X-36} F(t)=1−exp[−∫0tλ(x)dx](X-36)
如果我们对X-36取微分,我们有
f ( t ) = λ ( t ) e x p [ − ∫ 0 t λ ( x ) d x ] (X-37) f(t)=\lambda (t)exp[-\int_0^t\lambda (x)dx] \tag{X-37} f(t)=λ(t)exp[−∫0tλ(x)dx](X-37)
假如我们令 λ ( t ) = λ = 常 数 \lambda(t)=\lambda=常数 λ(t)=λ=常数,那么对于X-36和X-37,我们有
F ( t ) = 1 − e − λ t f ( t ) = λ e − l a m b d a t F(t)=1-e^{-\lambda t} \\ f(t)=\lambda e^{-lambda t} F(t)=1−e−λtf(t)=λe−lambdat
这是一个指数分布。对于该指数分布,然后,故障率是一个常数(仅依赖于时间t),
λ ( t ) d t = P [ 故 障 发 生 在 t 和 t + d t 之 间 ∣ 以 前 没 有 发 生 故 障 ] = λ d t \lambda(t)dt=P[故障发生在t和t+dt之间 | 以前没有发生故障]=\lambda dt λ(t)dt=P[故障发生在t和t+dt之间∣以前没有发生故障]=λdt
如果我们选择采用指数分布来描述部件的故障分布。我们假设我们处于“浴缸曲线”中恒定的,稳态的部分,没有老化和磨损的发生。因为故障率是一个常数,指数分布通常指作为“随机故障率分布”,如以后的故障概率依赖于以前时序正常工作时间。
如果我们采用 e = t / θ e^{=t/\theta} e=t/θ来表示可靠性也是十分有价值的,即使是磨损发生(但不是老化),我们这里依旧是保守的。例如 R ( t ) ≥ e − t / θ R(t)\geq e^{-t/\theta} R(t)≥e−t/θ,这里R(t)是实际上的可靠性, θ \theta θ是实际的故障平均时间。对于 t ≤ θ t \leq \theta t≤θ这个关系是真实的(参考[15])。
公式X-36,X-37可以用来评估多种不同类型的故障率模型。例如,如果 λ ( t ) = k t \lambda(t)=kt λ(t)=kt(线性增加的故障率)我们可以得出
R ( t ) = 1 − F ( t ) = e x p ( − k t 2 / 2 ) R(t)=1-F(t)=exp(-kt^2/2) R(t)=1−F(t)=exp(−kt2/2)
这被叫做瑞利分布。一个时间故障率相关的重要分布,通过将 λ ( t ) = K t m ( m > − 1 ) \lambda (t)=Kt^m (m>-1) λ(t)=Ktm(m>−1)代入,可以获得威布尔分布.
f ( t ) = k t m e x p ( − k t m + 1 m + 1 ) f(t)=kt^mexp(-\frac{kt^{m+1}}{m+1}) f(t)=ktmexp(−m+1ktm+1)
和
R ( t ) = 1 − F ( t ) = e x p ( − k t m + 1 m + 1 ) R(t)=1-F(t)=exp(-\frac{kt^{m+1}}{m+1}) R(t)=1−F(t)=exp(−m+1ktm+1)
威布尔分布是两参数的分布,k是比例参数(scale parameter),m是形状参数(shape parameter)。对于m=0,我们得到指数分布,当m增加,一个磨损行为就被建模。当m增长到2,f(t)则变成正态分布。当m小于0但是大于-1,则浴缸曲线的老化区域的模型就被建立起来。因此,改变m的值,我们能使用威布尔分布来包含浴缸曲线的I,II,III区域。读者可以从其他的文献中找到威布尔分布的更多的讲解。(参考【23】p137-138, 附录D,[36] p190)
10.9 一个涉及时间-失效分布的应用
时间-失效分布的概念是十分重要的,为了加深读者的印象,我们设计了如下的例子。
我们从两个供应商那里买了相似的部件A和B。供应商A声称平均寿命是100小时( θ A = 100 \theta_A=100 θA=100小时),并声称其时间-失效分布是指数分布。B的平均寿命也是100小时,但是它的时间-失效分布是正态分布,其均值是100小时,标准差是40小时。
让我们尝试计算这两个部件的10小时工作时间的可靠性。首先,我们考虑部件A。
R A ( t ) = e − t / θ A R A ( 10 ) = e − 10 / 100 = e − 0.1 = 0.905 R_A(t)=e^{-t/\theta_A} \\ R_A(10)=e^{-10/100}=e^{-0.1}=0.905 RA(t)=e−t/θARA(10)=e−10/100=e−0.1=0.905
因此,对于部件A,它的可靠性是90.5%。
现在让我们考虑部件B。它的分布是正态分布。我们需要找到对应t=10小时的变量z的值。
z = t − θ B σ B = 10 − 100 40 = − 2.25 z=\frac{t-\theta_B}{\sigma_B}=\frac{10-100}{40}=-2.25 z=σBt−θB=4010−100=−2.25
这个值是z去掉尾部区域的0.01222(从标准正态表),表明了10小时之前的失效概率。因此
R B ( t = 10 ) = 1 − 0.01222 = 0.988 R_B(t=10)=1-0.01222=0.988 RB(t=10)=1−0.01222=0.988
B的可靠性是98.8%。
根据以上的内容,我们发现尽管 θ A = θ B \theta_A=\theta_B θA=θB,但是 R A R_A RA和 R B R_B RB还是不一样。这个结果不同因为他们的分布是不同的。当t增加,最终指数分布会比正态分布有更高的可靠性。例如,对于t=100小时, R A = 36.8 R_A=36.8 RA=36.8, R B = 50.0 R_B=50.0% RB=50.0,但是对于t=200小时,这两个分布都会有相同的可靠性。读者可以计算下给定R_A=R_B$下t的值。
10.10 统计估计
假设我们参加洛杉矶地区中20到30岁的男人身高的研究。这是一个很大的总量,尽管我们想要去测量诶一个人的身高,但是实际上是不允许的。
我们采用一个妥协的方式解决该问题,我们从总量里边进行随机采样。随机采样的重要性将在后边叙述。从样本中,我们能估计任意感兴趣的参数,例如样本的均值,样本的中值,样本的方差等。现在的问题是,对于总量的采样统计这个方法到底怎么样?事实上,我们是否能保证样本均值比样本中值或中位数在总体均值中更好?为了回答这个问题,我们需要准确的了解诸如此类语句在统计上的含义。
“ θ a ^ \hat{\theta_a} θa^”表示总量参数 θ \theta θ的好的估计方法
“ θ b ^ \hat{\theta_b} θb^”表示总量参数 θ \theta θ的最好的估计方法
“ θ b ^ \hat{\theta_b} θb^”是比 θ c ^ \hat{\theta_c} θc^更好的估计方法(//TODO:这里没看懂,是不是应该是a?)
这些问题将在第十三章重新讲解。首先我们必须讨论选择随机样本的重要性,然后我们必须建立抽样分布的概念,特别是均值的抽样分布。
10.11 随机样本
一个随机样本,表示在一个总体中每一个样本都有相同的机会被涵盖(采样)。大多数统计计算是基于随机假设的;如果一个结论是通过看似是随机的,但实际上是反应某些总体特征的样本得出的,那么这个结论一定是大错特错的。
一个经典的随机假设是无效的例子,在1936年的Literary Digest投票上。投票想要做一个抽样调查,目的是看罗斯福和蓝盾谁能当选美国下一任总统。投票显示蓝盾将获胜,然而实际上却是罗斯福通过11069785票的普遍多数和523比8的选举人票数赢得了选举。在这个例子里,投票大部分是通过电话进行。在当时的经济大萧条时期,拥有电话的人大部分是富裕的共和党人,他们都倾向于投票给蓝盾。通过非随机样本做出的结论有明显的错误。在此之后不久Literary Digest就不复存在了。
如果想要在刚获取的一箱样本中进行随机抽样,那么只从箱子上边拿是不对的。如果你这样做了,你可能得到了过于乐观的结论,因为有可能箱子在运输过程中跌落,导致下边的部件都是故障的。不论何时进行抽样,必须小心保证抽样的随机性因为所有的估计技术都是基于随机抽样的。一个简单的方法,就是利用随机数表来保证抽样的随机性。其他随机抽样的方法在资料【10】有详细的描述。
10.12 抽样分布
假设从某总量中抽取样本的数量为n,并计算样本的均值 x 1 ‾ , 其 中 \overline{x_1},其中 x1,其中\overline{x_1}=\frac{1}{n}\sum_{i=1}{n}x_i , 我 们 现 在 能 进 行 第 二 次 数 量 为 n 的 抽 样 , 并 计 算 它 的 均 值 ,我们现在能进行第二次数量为n的抽样,并计算它的均值 ,我们现在能进行第二次数量为n的抽样,并计算它的均值\overline{x_2} 。 采 用 类 似 的 方 式 , 我 们 能 生 成 其 他 的 采 样 均 值 , 。采用类似的方式,我们能生成其他的采样均值, 。采用类似的方式,我们能生成其他的采样均值,\overline{x_3},\overline{x_4},\overline{x_5} 等 。 我 们 并 不 期 望 这 些 均 值 都 相 等 。 事 实 上 , 这 些 均 值 都 是 随 机 变 量 。 我 们 将 样 本 均 值 用 等。我们并不期望这些均值都相等。事实上,这些均值都是随机变量。我们将样本均值用 等。我们并不期望这些均值都相等。事实上,这些均值都是随机变量。我们将样本均值用\overline{X} 表 示 , 它 代 表 随 机 变 量 。 问 题 来 了 , 表示,它代表随机变量。问题来了, 表示,它代表随机变量。问题来了,\overline{X}$是如何分布的?所谓的受限中心极限定理(restricted central limit theorem)提供了部分答案,它是这样说的:
如果X(随机变量)是按照均值 μ \mu μ,方差 σ \sigma σ进行正态分布的,那么 X ‾ \overline{X} X是按照均值 μ X ‾ = μ \mu_{\overline{X}}=\mu μX=μ,方差 ( ω X ‾ ) 2 = ω 2 / n (\omega_{\overline{X}})^2=\omega^2/n (ωX)2=ω2/n进行正态分布的,n是样本大小。
这个定理只在总体数量是无限大的情况下才是完全正确的。对于有限的总量为N,样本大小为n,则
( ω X ‾ ) = ω 2 n ( N − n N − 1 ) (\omega_{\overline{X}})=\frac{\omega^2}{n}(\frac{N-n}{N-1}) (ωX)=nω2(N−1N−n)
更重要的是,一般的中心极限定理,指的是如果X是按照均值 μ \mu μ和方差 ω 2 \omega^2 ω2分布的,但是其他的分布是未知的, X ‾ \overline{X} X的分布和均值 μ \mu μ和方差 ω 2 / n \omega^2/n ω2/n非常接近,最少对于很大的n来说是这样的(n大于等于50)。
因此,不论何时我们处理大样本的均值,我们都会关注正态分布。均值采样分布的方差随着样本大小的增加而减少,这为尽可能多的采集样本数量提供了依据。注意针对 x ‾ \overline{x} x的z变换为
z = x ‾ − μ ω / n z=\frac{\overline{x}-\mu}{\omega/\sqrt{n}} z=ω/nx−μ
其他评估的方法(例如中位数,范围,方差等)的特征在于其对应的采样分布,其中的大部分可以在统计学的进一步资料中找到(例如参考【30】)。比如,对于一个正态分布,方差估计值 s 2 s^2 s2是卡方分布得到的 χ 2 \chi^2 χ2的函数。
χ 2 = ( n − 1 ) s 2 σ 2 \chi^2=\frac{(n-1)s^2}{\sigma^2} χ2=σ2(n−1)s2
卡方分布已经被广泛的制表,并大量应用于决策准则,拟合判断优度分析,以及假设测试。
10.13 点估计——总述(//TODO: Check General meaning )
从样本中计算单一的数值(比如 x ‾ \overline{x} x),构成了对应参数的点估计。代表值集合的相关随机变量称为样本估计量。为了便于描述,我们定义 θ \theta θ代表要估计的总量参数, θ a ^ , θ b ^ , θ c ^ \hat{\theta_a},\hat{\theta_b},\hat{\theta_c} θa^,θb^,θc^表示 θ \theta θ中要估计的各类样本。例如,如果 θ \theta θ表示总量的平均值,那么 θ a ^ \hat{\theta_a} θa^就可以表示样本均值估计量; θ b ^ \hat{\theta_b} θb^代表中位数估计; θ c ^ \hat{\theta_c} θc^代表中间范围估计,等等。
θ a ^ , θ b ^ , θ c ^ \hat{\theta_a},\hat{\theta_b},\hat{\theta_c} θa^,θb^,θc^估计量都有采样分布。读者应注意,以下的估计量特征与采样分布有关。
a) 无偏估计量
如果一个估计量的采样分布存在这样一个均值,该均值与被估计的总量参数相等,那么这个估计量叫做无偏估计量。因此,如果 θ a ^ \hat{\theta_a} θa^是一个总量均值 μ \mu μ的无偏估计量,那么
E ( θ a ^ ) = μ E(\hat{\theta_a})=\mu E(θa^)=μ
从期望的属性中,我们知道样本均值 X ‾ \overline{X} X是一个 μ \mu μ的无偏估计量,因为 E ( X ‾ ) = μ E(\overline{X})=\mu E(X)=μ。另一方面
S 2 = 1 n ∑ i = 1 n ( X i − X ‾ ) 2 S^2=\frac{1}{n}\sum_{i=1}^{n}(X_i-\overline{X})^2 S2=n1i=1∑n(Xi−X)2
是 σ 2 \sigma^2 σ2的偏差估计量。如果我们乘以 n / ( n − 1 ) n/(n-1) n/(n−1)(贝塞尔修正)我们有
S 2 = 1 n − 1 ∑ i = 1 n ( X i − X ‾ ) 2 S^2=\frac{1}{n-1}\sum_{i=1}{n}(X_i-\overline{X})^2 S2=n−11i=1∑n(Xi−X)2
这是 σ 2 \sigma^2 σ2的无偏估计量。
b) 最小均方差估计量和最小方差估计量
一个估计量的均方差定义如下:
M S E = E ( θ ^ − θ ) 2 (X-38) MSE=E(\hat{\theta}-\theta)^2 \tag{X-38} MSE=E(θ^−θ)2(X-38)
MSE是一个衡量估计值 θ ^ \hat{\theta} θ^偏离真实值 θ \theta θ的总量的一个方法。通过在公式X-38的圆括号中加上或减去 E ( θ ^ ) E(\hat{\theta}) E(θ^),并利用该结果,我们能重写MSE为如下形式:
M S E = E [ θ ^ − E ( θ ^ ) ] 2 + [ E ( θ ^ ) − θ ] 2 MSE=E[\hat{\theta}-E(\hat{\theta})]^2+[E(\hat{\theta})-\theta]^2 MSE=E[θ^−E(θ^)]2+[E(θ^)−θ]2
右手边的第一项是估计值的方差,第二项是估计值偏差的平方。如果估计是是无偏的,那么 E ( θ ^ ) = θ E(\hat{\theta})=\theta E(θ^)=θ,且
M S E = E [ θ ^ − E ( θ ^ ) ] 2 MSE=E[\hat{\theta}-E(\hat{\theta})]^2 MSE=E[θ^−E(θ^)]2
因此对于无偏估计量的MSE是简单的估计量的方差。
如果针对多个估计量 θ a ^ , θ b ^ , θ c ^ \hat{\theta_a},\hat{\theta_b},\hat{\theta_c} θa^,θb^,θc^…,其中之一有最小的MSE,那么这个估计量就叫做最小均方差(minimum mean square error,MMSE)估计量。如果在这些估计量中,所有的都是无偏的,其中之一有最小的方差,那么这个估计量就叫做最小方差无偏估计量(minimum variance unbiased estimator,MVUE)
估计量的选择依赖于应用情况。如果我们打算用于许多的应用,那么我们一般想要估计量是无偏的,因为一般来说我们希望估计量等于真实的值。如果我们从两个或者多个无偏估计量中选择,我们经常选择最小方差的那个。如果比较两个无偏的估计量 θ 1 ^ \hat{\theta_1} θ1^和 θ 2 ^ \hat{\theta_2} θ2^,那么其中具有相对较小的方差的那个更有效。在实际应用中,我们用它们的比值
v a r ( θ 2 ^ ) v a r ( θ 1 ^ ) \frac{var(\hat{\theta_2})}{var(\hat{\theta_1})} var(θ1^)var(θ2^)
它是一个衡量估计值 θ 1 ^ \hat{\theta_1} θ1^与 θ 2 ^ \hat{\theta_2} θ2^相对效率的方法。
但是,如果我们打算只应用估计值一次或者几次,那么一个(有偏差)MMSE估计值或许更有效率。在这个例子中,相对于长时间的无偏的性质,我们对与真实值的最小偏离量更感兴趣。
c) 一致估计量(Consistent Estimators) //TODO:I don’t know my translation is correct or not.
如果 θ a ^ \hat{\theta_a} θa^是 θ \theta θ的一致估计量,那么
P [ ∣ θ a ^ − θ ∣ < ϵ ] > ( 1 − δ ) n > n ′ P[|\hat{\theta_a} - \theta | < \epsilon] > (1-\delta) \ \ \ n>n' P[∣θa^−θ∣<ϵ]>(1−δ) n>n′
这里 ϵ \epsilon ϵ和 δ \delta δ是任意小的正数, n ′ n' n′是某个整数。我们可以将上面的等式解释为随着采样量n的增加,估计量的概率密度函数将集中与参数的真实值。当n变得非常大,估计值偏离真实值的概率将趋近于0.这种情形我们叫“ θ a ^ \hat{\theta_a} θa^的概率收敛到 θ \theta θ“。
性质a,b,c是评价估计量好与坏的理论特征。关于估计量的进一步的考虑将在参考[24]中给出。
10.14 点估计量——极大似然
一个计算估计量非常重要的技术叫做极大似然法。这个方法用途很广,例如,在生命测试中计算参数估计量。对于一般条件下的大样本数量(n趋近于无穷),极大似然技术可以得到一致估计量(consistent)、最小均值平方差估计量(MMSE)和最小方差无偏估计量(MVUE)。甚至对于中小规模的样本,极大似然技术也能产生可用的估计量。该技术基于以下的假设:从总体中抽取的特殊样本是最有可能被选择的样本。为了证明这个推论是正确的,考虑如下两个例子。
桥牌玩家不希望拿一手包含所有13张黑桃的牌。拿到这样一手牌的概率是十分小的,因为它只有一种发生的方式。但是,拿到一手黑桃的概率是和一手其他同样一张张分配好的牌的概率是一样的,因为它们也是只有一种方式。拿到一手牌的的样子可以是这样的:
- 4张黑桃
- 2张红心
- 4张方块
- 3张草花
这手牌有许多种获得的方式。准确的来说, C 1 3 4 C 1 3 2 C 1 3 4 C 1 3 3 = ( 13 ) 4 ( 11 ) 3 ( 10 ) 2 ( 3 ) C_13^4 C_13^2 C_13^4 C_13^3=(13)^4(11)^3(10)^2(3) C134C132C134C133=(13)4(11)3(10)2(3)种方式(超过10亿)。事实上,你将会得到4-4-3-2的分布大概20%的机会。剩下的次数将会得到和这个十分类似的一手牌。极大似然技术是基于这样一个假设:我们得到的抽样是最大概率得到的那一个,或者是接近最大可能的那一个。
为了更实际的阐述,假设我们有一个特殊的摄像头来拍摄一个满是气体的箱子里的分子。当这个摄像头开发出来,我们不仅能看到分子的位置,还能看到分子的矢量速度。我们可以拍照几千年,并且它们所有的照片将看起来很类似:空间中的同类型分子向所有方向的运动。即使这样,我们依旧有概率(即使很小),我们将找到一张照片,所有的分子都在盒子的一个角落,且运动方向都是北方。如果我们应用极大似然技术到一个样本(一张给定的照片),然后我们将作出一个假设:这个样本是一个可能性,但不是非常不可能的一个。
总的来说,极大似然技术是在以下假设上发现的:我们的样本是我们从总体中抽取到的最有可能的那一个——总是带有附带条件:我们尽力确保它是随机的。
假设我们从一个根据概率密度函数(pdf) f ( x ; θ ) f(x;\theta) f(x;θ)的总体随机抽样,这里 θ \theta θ是一个未知的总体参数,我们想要对其进行估计。假设我们的采样(大小为n)是 x 1 , x 2 . . . x n x_1,x_2...x_n x1,x2...xn,且样本的变量是独立的。利用概率密度函数,我们写下了一个表达式,该表达式给出了与特定样本相关的概率,并应用最大化的条件。
我们在区间 d x 1 dx_1 dx1中第一个读到是 x 1 x_1 x1的概率明显就是 f ( x 1 ; θ ) d x 1 f(x_1;\theta)dx_1 f(x1;θ)dx1。在 d x 1 dx_1 dx1中第一个读取到的是 x 1 x_1 x1,并且在 d x 2 dx_2 dx2中第二个读到的是 x 2 x_2 x2的概率是
f ( x 1 ; θ ) d x 1 f ˙ ( x 2 ; θ ) d x 2 f(x_1;\theta)dx_1 \dot f(x_2;\theta)dx_2 f(x1;θ)dx1f˙(x2;θ)dx2
根据这种推理方式,我们能写出例子的概率表达式为
P [ s a m p l e ] = f ( x 1 ; θ ) d x 1 f ( x 2 ; θ ) d x 2 f ( x 3 ; θ ) d x 3 . . . f ( x n ; θ ) d x n (X-39) P[sample]=f(x_1;\theta)dx_1 f(x_2;\theta)dx_2 f(x_3;\theta)dx_3...f(x_n;\theta)dx_n \tag{X-39} P[sample]=f(x1;θ)dx1f(x2;θ)dx2f(x3;θ)dx3...f(xn;θ)dxn(X-39)
如果我们抛弃微分,我们能得到一个被称作似然函数的表达式
Likelihood Function = f ( x 1 ; θ ) f ( x 2 ; θ ) . . . f ( x n ; θ ) = ∏ i = 1 n f ( x i ; θ ) (X-40) \text{Likelihood Function}= f(x_1;\theta)f(x_2;\theta)...f(x_n;\theta)=\prod_{i=1}^n f(x_i;\theta) \tag{X-40} Likelihood Function=f(x1;θ)f(x2;θ)...f(xn;θ)=i=1∏nf(xi;θ)(X-40)
符号 ∏ \prod ∏表示连乘。似然函数在该例子中不再等于概率,但是它表示与该概率成比例的数量。(如果概率变量不独立,则似然可能会由多种分布组成,我们将试图使其最大化,具体参考[24])
注意的是这个函数是仅仅是关于 θ \theta θ的,因为所有的x都是已知的。我们现在将研究如何取值 θ \theta θ,使得 L ( θ ) L(\theta) L(θ)最大化。我们通过将其求导,让导数等于0从而得到极值条件下 θ \theta θ的值。
d d θ L ( θ ) = 0 \frac{d}{d\theta}L(\theta) =0 dθdL(θ)=0
假设我们能解出该方程,将结果写作 θ M L \theta_ML θML,这就是极大似然估计一个未知总体的参数 θ \theta θ。
我们现在思考一些极大似然技术在实际中的具体应用的例子。假设我们从一个总体中随机抽样,该总体符合正态分布,其均值 μ \mu μ为未知,方差 σ 2 \sigma^2 σ2为1。
f ( x ; μ , σ = 1 ) = 1 2 π e x p [ − ( x − μ ) 2 2 ] . f(x;\mu,\sigma=1)=\frac{1}{\sqrt{2\pi}}exp[-\frac{(x-\mu)^2}{2}]. f(x;μ,σ=1)=2π1exp[−2(x−μ)2].
我们想对 μ \mu μ做出极大似然估计。
极大似然估计的函数是
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Msijvk6t-1586708457779)(asserts/equationX_t1.png)]
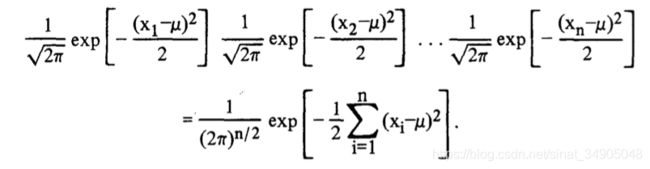
两边取自然对数,我们有
L ( μ ) = − n 2 l n ( 2 π ) − 1 2 ∑ i = 1 n ( x i − μ ) 2 L(\mu)=-\frac{n}{2}ln(2\pi)-\frac{1}{2}\sum_{i=1}{n}(x_i-\mu)^2 L(μ)=−2nln(2π)−21i=1∑n(xi−μ)2
应用最大化条件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3vwfcsDM-1586708457781)(asserts/equationX_t2.png)]
这产生
∑ x i − n μ = 0 \sum x_i - n\mu =0 ∑xi−nμ=0
于是
μ M L = 1 n ∑ i = 1 n x i = x ‾ \mu_{ML}=\frac{1}{n}\sum_{i=1}^n x_i=\overline{x} μML=n1i=1∑nxi=x
因此, μ \mu μ的极大似然估计就是数学均值。
如果多于一个总体的参数被估计,其过程是类似的。假设在以前的例子中 μ \mu μ和 σ 2 \sigma^2 σ2都是未知的,那么我们的基本概率密度函数为
f ( x ; μ , σ 2 ) = 1 2 π σ e x p [ − ( x − μ ) 2 2 σ 2 ] f(x;\mu,\sigma^2)=\frac{1}{\sqrt{2\pi}\sigma}exp[-\frac{(x-\mu)^2}{2\sigma^2}] f(x;μ,σ2)=2πσ1exp[−2σ2(x−μ)2]
似然函数为
f ( x 1 , μ , σ 2 ) . . . f ( x n ; μ , σ 2 ) = 1 ( 2 π σ 2 ) n / 2 e x p [ − ∑ i = 1 n ( x i − μ ) 2 2 σ 2 ] f(x_1,\mu,\sigma^2)...f(x_n;\mu,\sigma^2)=\frac{1}{(2\pi\sigma^2)^{n/2}}exp[-\sum_{i=1}{n}\frac{(x_i-\mu)^2}{2\sigma^2}] f(x1,μ,σ2)...f(xn;μ,σ2)=(2πσ2)n/21exp[−i=1∑n2σ2(xi−μ)2]
取自然对数,我们有
L ( μ , σ 2 ) = − n 2 l n ( 2 π ) − n 2 l n σ 2 − 1 2 s i g m a 2 ∑ i = 1 n ( x i − μ ) 2 L(\mu,\sigma^2)=-\frac{n}{2}ln(2\pi)-\frac{n}{2}ln\sigma^2-\frac{1}{2sigma^2}\sum_{i=1}{n}(x_i-\mu)^2 L(μ,σ2)=−2nln(2π)−2nlnσ2−2sigma21i=1∑n(xi−μ)2
我们得到 ∂ L / ∂ μ \partial L/\partial \mu ∂L/∂μ和 ∂ L / [ ∂ ( σ 2 ) ] \partial L/ [\partial(\sigma^2)] ∂L/[∂(σ2)]并将结果等于0,第一个操作得到和以前相同的结果,也就是
μ M L = 1 n ∑ i = 1 n x i = x ‾ \mu_ML=\frac{1}{n}\sum_{i=1}{n}x_i=\overline{x} μML=n1i=1∑nxi=x。
第二个操作得到
σ M 2 L = 1 n ∑ i = 1 n ( x i − x ‾ 2 ) \sigma^2_ML=\frac{1}{n}\sum_{i=1}{n}(x_i-\overline{x}^2) σM2L=n1i=1∑n(xi−x2)
这是一个 σ 2 \sigma^2 σ2的有偏估计,其偏差可以通过将 σ M 2 L \sigma^2_ML σM2L与数量n/(n-1)相乘来消除。那么
σ u n b i a s e d 2 = 1 n − 1 ∑ i = 1 n ( x i − x ‾ ) 2 \sigma^2_{unbiased}=\frac{1}{n-1}\sum_{i=1}{n}(x_i-\overline{x})^2 σunbiased2=n−11i=1∑n(xi−x)2
如果样本的大小n比较大( n ≥ 30 n\geq 30 n≥30),那么 σ M L 2 \sigma^2_{ML} σML2和 σ u n b i a s e d 2 \sigma^2_{unbiased} σunbiased2是没什么明显的差别的。方差的估计值通常用 s 2 s^2 s2来表示。
作为最后一个例子,让我们返回指数分布并找到 θ \theta θ的ML估计,也就是平均生命。//TODO:这里有点问题,ML到底如何翻译比较好?
假设我们n个部件实验中发生了n次失效,那么
f ( t 1 ; θ ) . . . f ( t n ; θ ) = θ − n e x p [ − 1 θ ∑ i = 1 n t i ] f(t_1;\theta)...f(t_n;\theta)=\theta^{-n}exp[-\frac{1}{\theta}\sum_{i=1}^{n}t_i] f(t1;θ)...f(tn;θ)=θ−nexp[−θ1i=1∑nti]
且
L ( θ ) = − n l n θ − 1 θ ∑ i = 1 n t i L(\theta)=-nln\theta - \frac{1}{\theta}\sum_{i=1}^{n}t_i L(θ)=−nlnθ−θ1i=1∑nti
因此
d L d θ = − n θ + 1 θ 2 ∑ i = 1 n t i = 0 \frac{dL}{d\theta} = -\frac{n}{\theta}+\frac{1}{\theta^2}\sum_{i=1}{n}t_i=0 dθdL=−θn+θ21i=1∑nti=0
并且
1 θ ∑ i = 1 n t i = n \frac{1}{\theta}\sum_{i=1}^{n}t_i=n θ1i=1∑nti=n
于是
θ M L = 1 n ∑ i = 1 n t i \theta_{ML}=\frac{1}{n}\sum_{i=1}^n t_i θML=n1i=1∑nti
又一次是简单数学平均。
10.15 区间估计(Interval Estimators)
从上一节,我们学习到,基于从总体中随机抽样,如何进行总体参数的点估计。如果我们愿意,我们也可以采用一种不同的方法。这涉及到一个如下的断言(assertion)
P [ ( θ ^ l o w e r < θ < θ ^ u p p e r ) ] = η P[(\hat{\theta}_{lower} < \theta < \hat{\theta}_{upper})] = \eta P[(θ^lower<θ<θ^upper)]=η
这里 θ \theta θ是一个未知的总体参数, θ ^ l o w e r \hat{\theta}_{lower} θ^lower和 θ ^ u p p e r \hat{\theta}_{upper} θ^upper是随机抽样的估计量, η \eta η是一个概率值,像是0.99,0.95什么的。假设 η = 0.95 \eta=0.95 η=0.95,我们是指如下的区间
( θ L < θ < θ U ) (\theta_L<\theta<\theta_U) (θL<θ<θU)
对于置信区间为95%情况下的 θ ^ l o w e r \hat{\theta}_{lower} θ^lower和 θ ^ u p p e r \hat{\theta}_{upper} θ^upper。在这个例子中,我们允许5%的概率(风险)我们的断言是错误的。
为了阐明置信区间的概念,我们用几何的方法来说明。假设我们从总体中连续的抽样 ( x 1 , x 2 ) (x_1,x_2) (x1,x2),它有个参数是 θ \theta θ,我们对 θ \theta θ设置了一个置信区间。我们在对应的纵坐标 θ \theta θ和横坐标 x 1 , x 2 x_1,x_2 x1,x2中设置了三维的空间(参考X-9)。总体参数 θ \theta θ的实际数值已被标记在了纵坐标轴上,一个横向的平面穿过了这个点。现在我们从我们95%置信区间中计算的值 θ U , θ L \theta_U,\theta_L θU,θL中随机抽样 ( x 1 , x 2 ) (x_1,x_2) (x1,x2)。 θ U \theta_U θU和 θ L \theta_L θL所定义的区间被画在图中。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dDr3xUKv-1586708457782)(asserts/figureX-9.png)]

下一步我们进行第二次抽样 ( x 1 ′ , x 2 ′ ) (x_1',x_2') (x1′,x2′),据此我们在95%置信区间中计算出 θ U ′ , θ L ′ \theta '_U,\theta_L' θU′,θL′。这个区间被标注在图中。第三次抽样 ( x 1 ′ ′ , x 2 ′ ′ ) (x_1'',x_2'') (x1′′,x2′′)得到 θ U ′ ′ , θ L ′ ′ \theta_U'',\theta_L '' θU′′,θL′′,等等。在这种方式下,我们能生成一个大的置信区间族。这些置信区间仅仅依赖于采样的值 ( x 1 , x 2 ) ( x 1 ′ , x 2 ′ ) . . (x_1,x_2)(x_1',x_2').. (x1,x2)(x1′,x2′)..,因此我们能在不知道 θ \theta θ的真实值的情况下计算这些区间。如果所有的置信区间都是在95%置信的基础上计算的,并且如果这些置信区间的族非常大,那么其中的95%将通过 θ \theta θ(包含 θ \theta θ)切割那个平面,而其中5%不会。
选择一个随机样本,并且从中计算置信区间的过程,就相当于从一个包含几千个置信区间的口袋中随机抓取一个。如果它们都是95%区间,我们选择一个包含 θ \theta θ的机会是95%。相反的,5%的机会我们不幸的选择了一个不包含 θ \theta θ的(就像图X-9中 ( θ U ′ ′ , θ L ′ ′ ) (\theta_U'',\theta_L'') (θU′′,θL′′)区间)。如果5%的风险感觉太高了,我们可以选择99%的区间,这个风险只有1%。如果我们选择更高的置信层次(更低的风险),如果我们持续增加置信层级,区间的长度将会增加直到100%置信,此时区间包含了每一个可能的 θ \theta θ的值(我确信在总量10000中有缺陷的物品的数量为0至10000之间)。因此,100%置信区间没什么意义。
现在我们看一个例子,学习怎么样从一个均值为 μ \mu μ,标准差为 σ \sigma σ的正态分布中计算出 θ L \theta_L θL和 θ U \theta_U θU。在这个例子中,我们假设我们想要求解 μ \mu μ并且已经知道 σ \sigma σ(基于以前的数据和知识)。如果每一个样本都来自正态分布,那么样本均值 X ‾ \overline{X} X是一个均值为 μ \mu μ标准差为 σ / n \sigma/\sqrt{n} σ/n的正态分布,这里n是样本大小。甚至如果每一个样本的值都不是取自正态分布,那么根据中心极限定理,对于一个非常大的n, X ‾ \overline{X} X也将约等同均值为 μ \mu μ,标准差为 σ / n \sigma/\sqrt{n} σ/n的正态分布。然后数量Z将是标准正态随机变量,这里
Z = X ‾ − μ σ / n Z=\frac{\overline{X}-\mu}{\sigma/\sqrt{n}} Z=σ/nX−μ
这里Z的分布已经被制表。因为Z的分布已经被制表,对于任意给定的概率 η \eta η,-w和w的值,这样
P [ − w < Z ≤ w ] = η P[-w < Z \leq w] = \eta P[−w<Z≤w]=η
例如,对于 η = 0.95 , w = 1.96 \eta = 0.95, w= 1.96 η=0.95,w=1.96。上式中取代Z,我们有
P [ − w ≤ X ‾ − μ σ / n ≤ w ] = η P[-w\leq\frac{\overline{X}-\mu}{\sigma/\sqrt{n}}\leq w]=\eta P[−w≤σ/nX−μ≤w]=η
这里w对于任意给定的 η \eta η是已知的。(例如,我们可以替代 η \eta η为0.95且w为1.96)
下面我们来专注于最后一个公式左边的不等式,并将它转化成如下的形式:
[ θ L < μ < θ U ] [\theta_L<\mu<\theta_U] [θL<μ<θU]
各项都乘以因子 σ / n \sigma/\sqrt{n} σ/n,将不等式转换成
[ − w σ n < X ‾ − μ < + w σ n ] [-w\frac{\sigma}{\sqrt{n}}<\overline{X}-\mu<+w\frac{\sigma}{\sqrt{n}}] [−wnσ<X−μ<+wnσ]
每一项减去 X ‾ \overline{X} X
[ − w σ n − X ‾ < − μ < w σ n − X ‾ ] [-w\frac{\sigma}{\sqrt{n}}-\overline{X}<-\mu
下一步我们将每一项乘以-1,注意此操作要将不等式反向。
[ w σ n + X ‾ > μ > − w σ n + X ‾ ] [w\frac{\sigma}{\sqrt{n}}+\overline{X}>\mu>-w\frac{\sigma}{\sqrt{n}}+\overline{X}] [wnσ+X>μ>−wnσ+X]
我们可以写成如下的形式
[ X ‾ − w σ n < μ < X ‾ + w σ n ] [\overline{X}-w\frac{\sigma}{\sqrt{n}}<\mu<\overline{X}+w\frac{\sigma}{\sqrt{n}}] [X−wnσ<μ<X+wnσ]
该不等式得出了 μ \mu μ的置信区间,在总体均值的情况下,那么
θ L = x ‾ − w σ n θ U = x ‾ + w σ n \theta_L=\overline{x}-w\frac{\sigma}{\sqrt{n}} \\ \theta_U=\overline{x}+w\frac{\sigma}{\sqrt{n}} θL=x−wnσθU=x+wnσ
如果给定了置信系数 η \eta η, x ‾ , n , w \overline{x},n,w x,n,w是已知的。 σ \sigma σ的值假设也已经知道。如果我们不知道 σ \sigma σ的值,从先前的正态分布描述中,我们可以通过采样来估计 σ \sigma σ,从而获得数量s。现在我们可以形成标准值t,其中
t = x ‾ − μ s / n t=\frac{\overline{x}-\mu}{s/\sqrt{n}} t=