腾讯&上交&浙大提出PyramidCLIP,进行层次内语义对齐和跨层次关系对齐,Zero-Shot效果优于CLIP!...
关注公众号,发现CV技术之美
本篇文章分享论文『PyramidCLIP: Hierarchical Feature Alignment for Vision-language Model Pretraining』,由腾讯&上交&浙大(沈春华)提出PyramidCLIP,进行层次内语义对齐和跨层次关系对齐,ImageNet上Zero-Shot效果优于CLIP!
详细信息如下:

论文链接:https://arxiv.org/abs/2204.14095
01
摘要
大规模视觉语言预训练在下游任务中取得了可喜的成果。现有的方法高度依赖于这样一个假设,即从互联网上抓取的图像-文本对是完全一对一对应的。然而,在实际场景中,这一假设很难成立:通过对图像的关联元数据进行爬取获得的文本描述通常存在语义不匹配和相互兼容性问题。
为了解决这些问题,作者引入了金字塔CLIP(PyramidCLIP),它构建了一个具有不同语义层次的输入金字塔,并通过层次内语义对齐(intra-level semantics alignment)和跨层次关系对齐(cross-level relation alignment)以层次的形式对齐视觉元素和语言元素。此外,作者还通过soften负样本(未配对样本)的损失来调整目标函数,以削弱预训练阶段的严格约束,从而降低模型过度约束的风险。
在三个下游任务上的实验,包括zero-shot图像分类、zero-shot图像文本检索和图像目标检测,验证了所提出的金字塔CLIP的有效性。特别是,在1500万图像-文本对的预训练数据量相同的情况下,基于ResNet-50/ViT-B32/ViT-B16的PyramidCLIP在ImageNet上的Zero-Shot分类top-1精度,比CLIP分别高出19.2%/18.5%/19.6%。
02
Motivation
最近,视觉语言预训练(VLP)取得了巨大的成功,其目的是通过对从web上获取的大规模图像-文本对模型进行预训练来提高下游视觉语言任务的准确性,而无需任何手动标注。主流VLP方法大致可分为两种范式,单流和双流。与单流模式相比,双流模式将图像编码器和文本编码器解耦,并分别提取图像和文本的特征,使双流模式对下游应用程序更加友好。
由于性能和效率的优势,双流模式占主导地位。CLIP对从互联网上收集的400M图像-文本对进行对比图像语言预训练,取得了惊人的效果。后来,DeCLIP和FILIP等方法通过在图像模态和文本模态中引入自监督,并在ViT patch token上引入更细粒度的对齐,从而改进了CLIP。

尽管现有的类CLIP方法在下游任务中取得了非常有希望的结果,但它们强烈依赖于图像-文本对具有高质量的假设:图像和文本具有良好的匹配性。理想情况下,匹配的图文对是完美的一对一对应,并且与其他未配对样本无相关性。然而,在事实中,如上图所示,这一假设并不容易满足。
首先,视觉模态和语言模态之间的语义不匹配通常存在于图像-文本对中,例如,(a)标题冗余:文本描述了太多冗余和细粒度的细节,而图像需要更简洁的标题;(b) 图像冗余:与文本相对应的感兴趣区域(ROI)只是图像的一个子区域;(c)Cast Deficiency:文本缺少对图像中突出对象的描述,而视觉建模需要考虑实例之间的关系。(d)相互兼容性通常发生在对之间,即对具有或多或少的局部相似性。
例如,(d)的图像/文本可以部分对应于(a)的文本/图像。然而,现有方法直接将其他对视为负样本,而不考虑相关性,这可能导致模型过度拟合。
为了解决上述问题,作者在本文中提出了PyramidCLIP,它以层次结构的形式更精确地对齐图像和文本。PyramidCLIP在双流网络的两侧构造了一个具有不同语义级别的输入金字塔,即图像中的全局图像,局部图像区域以及图像中显著实例的特征,用于视觉建模; 用于语言建模的原始标题和文本摘要。
然后,作者通过层次内语义对齐和跨层次关系对齐来对比视觉元素和语言元素,分别解决 (a)(b) 和 (c) 的问题。具体而言,对于内部语义对齐,由于图像和文本摘要的全局区域都包含全局语义信息,而局部区域和原始标题都包含更细粒度的语义信息,因此它们被视为两对正样本。对于跨层次关系对齐,为了避免视觉编码器对对象关系的建模被场景语义建模所淹没,作者显式地将实例关系与语言元素对齐。此外,对于相互兼容性问题,作者在对比过程中软化了负的未配对样本的损失项,以减轻严格的约束,减轻了某些局部相似性的负面影响。
大量实验证明了本文提出的PyramidCLIP的有效性。为了公平比较,当使用YFCC1M数据集进行训练时,使用ResNet-50/ViT-B32/ViT-B16作为图像编码器,使用Transformer作为文本编码器,本文的模型在ImageNet上实现了最先进的(SoTA)zero-shot分类,即44.7%/41.4%/47.2%的top-1精度。相比之下,CLIP baseline为22.5%/22.9%/27.6%。此外,当扩展到更大规模的数据集时,在128M图像-文本对上仅训练8个epoch的PyramidCLIP的结果与在400M数据集上训练32个epoch的CLIP的结果非常接近,这显著提高了CLIP的训练和数据效率。
本文的主要贡献总结如下:
提出了一种用于视觉语言模型预训练的更精确的图像-文本对齐PyramidCLIP,它在视觉编码器和语言编码器的两侧有效地构建一个输入金字塔,然后通过层次内语义对齐和跨层次关系对齐来对齐视觉元素和语言元素。
在对比过程中,作者软化了负样本的损失项,以减轻严格的约束,从而避免模型过于复杂,减轻了局部相似性造成的负面影响。
大量实验证明了PyramidCLIP的有效性。在预训练数据量相同的情况下,PyramidCLIP可以获得SoTA结果,并且显著优于CLIP。
03
方法
3.1 Overall Architecture
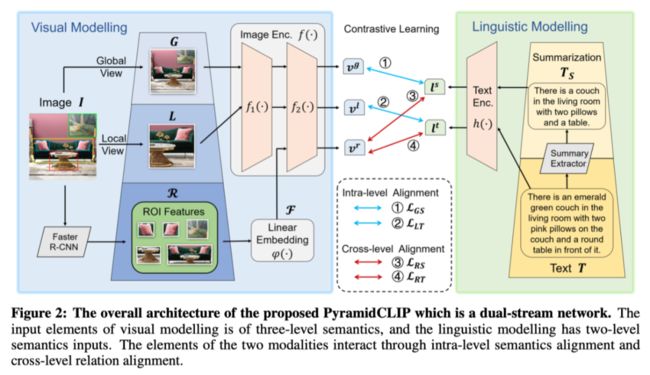
上图显示了PyramidCLIP的整个框架。PyramidCLIP是一种双流网络,包括文本编码器h和图像编码器f=f 2◦ f 1,其中f 1和f2分别表示图像编码器的前部和后部。每个编码器由一个线性投影模块和一个归一化操作符组成,最后将最终CLS token投影到统一维度,然后对其进行归一化,在相同的嵌入空间中获得相应的视觉或语言表示向量。
在训练过程中,对于每个图像-文本对,通过不同比率的随机裁剪将图像I转换为两个视图,即局部视图L和全局视图G,并将文本T输入摘要提取器,以生成具有更高语义的文本摘要。图像全局视图G和文本摘要都捕获了更多的全局上下文信息,而图像局部视图L和原始文本T包含了更多的详细信息。
因此,G和被视为一对正样本,而L和T被视为另一对正样本,表示为(G,)和(L,T)。然后将这两对输入到双流编码器,以提取全局和局部表示对和,其中,和。最后,通过对比学习损失1和2将和分别拉到一起(见上图),同一batch中的其他样本作为负样本处理。作者将这种对比过程称为层次内语义对齐。
此外,为了明确地建模图像中显著对象之间的关系,通过预训练的目标检测器提取图像I中M个检测到的显著对象的ROI特征序列。然后,使用线性嵌入模块将ROI特征序列转换为与图像编码器前部f 1的输出相同的维度。序列依次馈入后部f 2,后部f 2包含一个或多个多头自注意(MHSA)层,以自适应捕获这些显著实例之间的关系,生成最终表示向量,即。为了避免视觉模型的关系建模被上下文语义建模所淹没,削弱推理能力,作者将和作为另两个正对,并且通过对比学习损失3和4,ROI嵌入和相应语言嵌入之间的距离缩小,这称为跨级别关系对齐。
3.2 Intra-level Semantics Alignment
现在介绍层次内语义对齐的详细信息。如上所述,CLIP等双流视觉语言对比学习方法强烈依赖于图像-文本对具有良好的一对一对应质量。然而,图像和文本标题之间的语义不匹配常常发生在自动获取的数据中。因此,作者在双流网络的两侧构造一个具有多级语义的输入金字塔,然后在同一语义层次内对齐图像和文本。具体而言,图像I通过两种不同比率的随机crop转换为全局视图G和局部视图L。对于文本标题,除了原始标题T之外,还使用预训练的文本摘要提取器提取语义更紧凑的文本摘要。
Coarse-grained Global Contrast
作者将生成全局视图G的随机裁剪比设置为[0.9,1],它基本上包含了原始图像中的所有信息。文本摘要压缩了原始标题T,删除了标题T中的一些冗余和过于详细的信息。G和都捕获全局信息,可以用作成对的正样本。通过对比学习,g和的投影嵌入和拉近了距离。
Fine-grained Local Contrast
由于全局视图G与上述文本摘要的对齐相对粗糙,因此在很大程度上丢弃了细粒度信息。直观地说,图像子区域可以与标题的某些描述对齐。为此,作者引入细粒度局部对比度。作者将用于生成局部视图L的随机裁剪比率设置为[0.5,1],它关注图像I的子区域。原始标题T包含许多详细描述,因此更适合将其视为L的正样本。然后,L和T的投影嵌入和也通过对比损失合并在一起。
3.3 Cross-level Relation Alignment
为了进一步提高对齐精度,作者引入了图像中显著对象的ROI特征序列,以提供更多的监督。具体地说,给定一幅具有M个显著对象的图像I,作者使用预训练的对象检测器Faster R-CNN来提取每个对象区域的视觉语义为,其中m表示第M个对象,是2048维特征向量,是4维归一化位置向量,表示左上角和右下角的坐标。
通过concat和,可以得到2052维位置敏感ROI特征向量,形成ROI特征序列。然后使用嵌入模块中的projector被转换为,其中d表示图像编码器中MHSA层的潜在尺寸。在前面附加一个随机初始化的d维class token,得到,进一步馈入图像编码器的后部,以计算归一化ROI关系嵌入,即,。
为了增强文本编码器对概念关系建模的能力,同时避免削弱视觉编码器的推理能力,和被用作另两个正对,同时最小化和之间的距离以及和之间的距离。由于视觉模态使用的实例级输入是非常细粒度的,而语言模态使用的输入是完整的句子(文本摘要和原始标题),因此作者将此训练过程称为跨层次关系对齐。
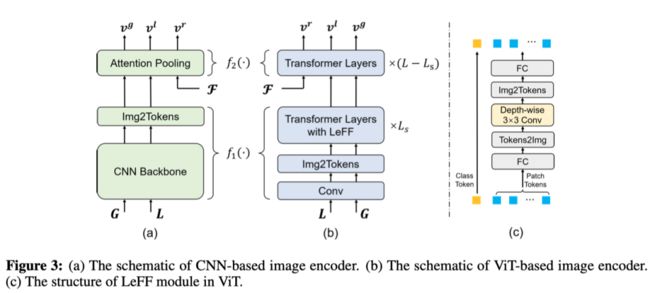
在视觉模型为卷积神经网络(CNN)的情况下,传统的池化层被注意力池化所取代,而注意力池化实际上是一个MHSA层。因此,嵌入的ROI特征序列F被输入到注意池化层,即f2,它表示最终的注意池化层,如上图(a)所示。对于基于transformer的视觉模型(ViT),序列F可以直接输入到transformer层。考虑到F已经编码了高级视觉语义,作者将其输入到ViT编码器的后部f2中,如上图(b)。
此外,标准ViT可能无法充分利用局部上下文信息,这限制了基于ViT的图像编码器的视觉表示能力。作者将深度方向的卷积合并到ViT结构的前馈模块中,称为局部增强前馈模块(LeFF),改善了patch级的局部感知和交互。
LeFF的结构如上图(c)所示。首先,通过线性投影层将patch token投影到更高的维度并进行reshape。接下来,使用3×3深度方向的卷积来捕获局部信息。然后将特征映射映射到token序列,并重新投影到初始维度。而CLS token在过程中是不变的,并与局部增强的patch token连接,生成最终输出。如上图(b)所示,LeFF仅应用于基于ViT的图像编码器的前部f 1,因为它显然不适合嵌入的ROI特征序列。
3.4 Softened Objective Function
对于一个batch中的N个图像文本对,其中i表示第i对,通过双流编码器获得相同维度的归一化嵌入向量。在此公式中,图像编码器分别从全局裁剪图像G、局部裁剪图像L和ROI特征序列生成,而文本编码器分别从文本摘要和原始文本T生成。
然后,作者使用该向量组构造了四个监督信号,用于batch内对比学习,这些监督信号可以分别用
402 Payment Required
来计算。本文的四个对比损失旨在从不同的语义层次实现视觉表征和语言表征之间的对齐。以的第一个损失项为例。对于第i对,归一化视觉与语言相似度和语言与视觉相似度
402 Payment Required
可通过以下公式计算:
式中,τ是初始化为0.07的可学习温度参数,函数sim(·)进行点积以测量相似性得分。
在实践中,通常使用交叉熵来优化模型。这种hard targets假定未配对的图像和文本之间绝对没有相似性。然而,在大batch中,未配对的图像和文本可能或多或少具有局部相似性,即图像中的一些局部区域可能与其他未配对文本中的一些单词或阶段相匹配。为了解决这个问题以更好地泛化,作者使用标签平滑来软化hard targets。第i对对应的软化目标 和可以写为:

其中α是在本文的实验中设置为0.2的平滑超参数。那么损失项可以表示为:

其他三个损失项可以类似地计算。因此,PyramidCLIP的总体目标函数为:

其中,在本文的实验中,损失权重λ、µ和γ均设置为0.25。
04
实验

上表列出了本文使用的所有预训练数据集以及相应的图像-文本对数。


为了公平比较,作者在YFCC1M-V1上进行了实验,结果如上表所示。可以看出,当两种方法都在YFCC15M-V1上进行预训练时,本文的方法明显超过了CLIP的结果。
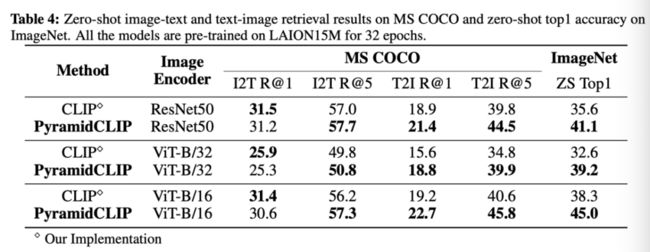
由于不同数据集的分布可能差异很大,作者不仅在常用的YFCC15M数据集上进行了实验,还从LAION400M中抽取了1500万个图像-文本对进行公平比较。结果如上表所示,可以看出,无论使用何种视觉编码器,PyramidCLIP仍然比CLIP好很多。

在本节中,作者在一个更大的数据集上验证了本文的方法的有效性,即128M图像-文本对,ImageNet Zero-shot分类精度结果如上表所示。

作者研究了ViT前部Transformer层数的影响,结果如上图所示,可以发现,将设置为9可获得最佳结果,因此在本文的实验中=9。

作者进一步验证了PyramidCLIP中每个组件的有效性,结果如上表所示。值得注意的是,表示原始CLIP的损失,实际上是图像全局视图与原始文本之间的对比丢失。此外,还可以看到,本文提出的所有模型组件,都可以单独带来显著收益。

为了验证本文的模型能够更好地利用图像中对象之间的关系,作者在目标检测任务中验证了本文的模型,结果如上表所示。
05
总结
在本文中,作者提出了一种称为PyramidCLIP的分层预训练方法,以提高视觉和语言模态之间的一致性。通过在双流网络的两侧显式构造金字塔语义输入,它解决了网络爬取网数据不完全一一对应的问题。作者还表明,软化的内部语义对齐和跨级别关系对齐可以在两种模态之间进行有益的相互作用。PyramidCLIP在三个下游任务上实现了SOTA的结果,显示了其优越性。
参考资料
[1]https://arxiv.org/abs/2204.14095

END
欢迎加入「视觉语言」交流群备注:VL
