深度聚类综述及论文整理
A Survey of Clustering With Deep Learning: From the Perspective of Network Architecture
(2018 c94)
一、基本概念
聚类的目的:
基于一些相似性度量将类似数据分类为一个聚类。
传统的聚类方法:
基于分区的方法,基于密度的方法,分层方法
传统聚类的劣势:
使用的相似性度量方法效率低下,传统聚类方法在高维数据上的性能较差,在大规模数据集上具有较高的计算复杂度。
解决手段:
降维和特征转换,将原始数据映射到新的特征空间中,使得生成数据更易被现有分类器分离。 数据转换方法包括线性变换(例如主成分分析(PCA))和非线性变换(例如核方法和谱方法)。
评估指标:
无监督聚类精度unsupervised clustering accuracy (ACC):
标准化互信息Normalized Mutual Information(NMI) :
损失:
网络损失Ln:
用于学习可行的特征并避免琐碎的解决方案,可以是AE的重建损失,VAE的变异损失或GAN的对抗损失。
聚类损失Lc则鼓励特征点变得更具区分性。
二、深度聚类及相关文献
(一)AE-BASED DEEP CLUSTERING (特征与应用脱节)
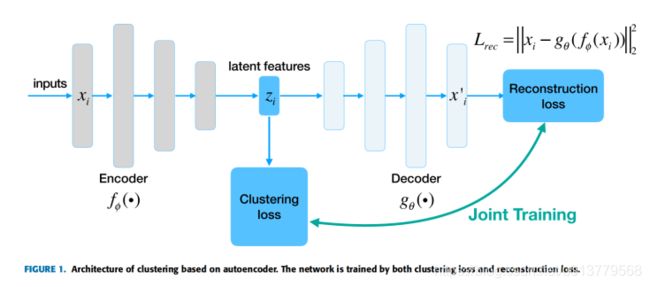
自动编码器(AE)是无监督表示学习中重要算法之一。训练映射,确保在编码器层和数据层之间的重建损失最小。由于隐藏层的维数通常比数据层小,因此它可以帮助提取数据的最显着特征。AE主要用于在监督学习中为参数找到更好的初始化,也可将其与无监督聚类结合。AE可以看作由两部分组成:将原始数据x映射为表示h的编码器,以及产生重建的解码器。其中φ和θ分别表示编码器和解码器的参数。重建的表示r必须与x尽可能相似。
当两个变量的距离度量为均方误差时,给定一组数据样本{xi},则其优化目标如下:
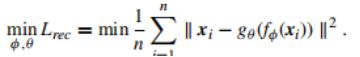
1、Deep Clustering Network (DCN):13
Towards K-means-friendly spaces: Simultaneous deep learning and clustering(2016 c243)
Code1:https://github.com/boyangumn/DCN-New
Code2:https://github.com/sarsbug/DCN_keras
DCN结合了自动编码器和k-means算法。DCN预先训练一个自动编码器,而后将优化重建损失和k均值损失。与其他方法相比,DCN的目标很简单,并且计算复杂度较低。
2、Deep Embedding Network (DEN):31
Deep embedding network for clustering(2014 c77)
DEN首先利用自动编码器从原始数据中学习简化表示。为了保留原始数据的局部结构属性,应用了局部保留约束。此外,它还合并了组稀疏性约束,以对角化表示的亲和力。连同重建损失,一起优化了这三个损失,以对网络进行微调,以实现面向集群的表现。最后利用k-means来对表示进行聚类。
3、Deep Subspace Clustering Networks (DSC-Nets):37
Deep subspace clustering networks(2017 c138)
DSC-Nets引入了一种新颖的自动编码器架构,以学习显式的非线性映射。作者引入了一种新颖的自表达层,该层是一个完全连接的层,没有偏置和非线性激活函数,并插入了编码器和解码器之间的连接点。该层旨在对从子空间的并集中提取的数据的自表达特性进行编码。其优化目标是子空间聚类损失和重建损失。在几个小规模数据集上具有优越的性能,但运算量大,因此无法应用于大规模数据集。
4、Deep Multi-Manifold Clustering (DMC):41
Unsupervised multi-manifold clustering by learning deep representation(2017 c29)
DMC是一种基于深度学习的多流形聚类(MMC)框架(?)。
5、Deep Embedded Regularized Clustering (DEPICT):14
Deep clustering via joint convolutional autoencoder embedding and relative entropy
Minimization(2017 c173)
DEPICT由堆叠在多层卷积自动编码器顶部的softmax层组成。
6、Deep Continuous Clustering (DCC):42
Deep continuous clustering(2018 c21)
DCC旨在解决深度聚类的两个限制。 由于大多数深度聚类算法均基于经典的基于中心,基于散度或分层,因此它们具有一些固有的局限性。一方面,需要先验地设置聚类数。另一方面,这些方法的优化过程涉及目标的离散重新配置,需要交替更新聚类参数和网络参数。 DCC使用连续聚类(RCC),该公式具有明确的连续目标,并且不需要聚类数的先验信息。
(二)CDNN-BASED DEEP CLUSTERING
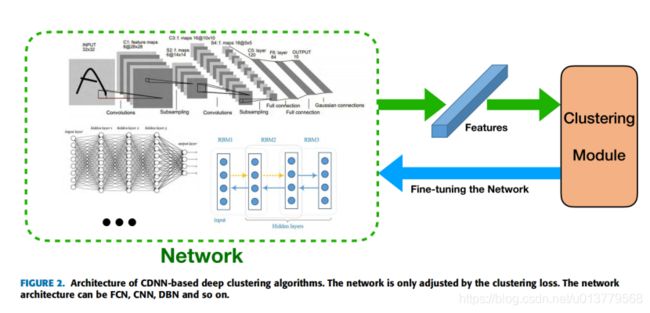
基于CDNN的算法仅使用聚类损失训练网络,其中网络可以是FCN,CNN或DBN。
由于没有重建损失,当数据点简单地映射到紧密的聚类时,基于CDNN的算法就有获得损坏的特征空间的风险,导致聚类损失的值很小但无意义。因此,聚类损失的设置和网络初始化很重要。因此,根据网络初始化的方式将基于CDNN的深度聚类算法分为三类,无监督的预训练,有监督的预训练和随机初始化(无预训练)。
(a)UNSUPERVISED PRE-TRAINED NETWORK
受限玻尔兹曼机和自动编码器已应用于基于CDNN的聚类。首先以无监督的方式训练RBM或自动编码器,然后通过聚类损失对网络进行微调。
1、Deep Nonparametric Clustering (DNC):30
Deep learning with nonparametric clustering(2015 c43)
DNC利用DBN的无监督特征学习进行聚类分析。它首先训练一个DBN,以将原始训练数据映射到嵌入中。然后,它运行非参数最大余量聚类(NMMC)算法,以获取所有训练数据的聚类数和标签数。之后,需要进行微调改善DBN顶层的参数。实验结果显示其优于经典聚类算法。
2、Deep Embedded Clustering (DEC):11
Unsupervised deep embedding for clustering analysis(2016 c777)
DEC使用自动编码器作为网络体系结构,并使用聚类分配强化损失作为规范。首先通过重建损失训练自动编码器,丢弃解码器部分。编码器网络提取的特征用作聚类模块的输入。 之后,使用聚类分配强化损失对网络进行微调。同时,通过最小化软标签的分布和辅助目标分布之间的KL散度来迭代改善聚类。结果表示该算法取得了良好的效果,并成为新的深度聚类算法性能的参考。
3、Discriminatively Boosted Clustering (DBC):12
Discriminatively boosted image clustering with fully convolutional auto-encoders
(2018 c80)
DBC与DEC具有几乎相同的体系结构,唯一的改进是它使用了卷积自动编码器。由于使用了卷积网络,它在图像数据集上的性能优于DEC。
(b)SUPERVISED PRE-TRAINED NETWORK
尽管无监督的预训练可以更好地初始化网络,但是从复杂的图像数据中提取可行的特征仍然具有挑战性。实验结果表明,从经过深化的CNN提取的特征经过大规模,多样的标记数据集训练后,再结合经典的聚类算法,可以胜任最新的图像聚类方法。为此,当聚类目标是复杂的图像数据时,可以使用最流行的网络架构,例如VGG,ResNet或Inception模型。
4、Clustering Convolutional Neural Network (CCNN):17
CNN-based joint clustering and representation learning with feature drift compensation
for large-scale image data(2017 c49)
CCNN提出了一个基于CNN的框架来迭代解决聚类和表示学习。它首先随机选择k个样本,并使用在ImageNet数据集上经过预训练的初始模型来提取其特征作为初始聚类质心。 在每个步骤中,执行小批量k均值以更新样本和聚类质心的分配,同时使用随机梯度下降法更新建议的CNN的参数。Mini-batch的k均值显着降低了计算和存储成本,使CCNN可以适应大规模数据集。
(c)NON-PRE-TRAINED NETWORK
5、Information Maximizing Self-Augmented Training(IMSAT):49
Learning discrete representations via information maximizing self-augmented
training(2017 c118)
IMSAT是一种无监督的离散表示学习算法,其任务是将数据映射为离散的表示函数。它结合了FCN和正则化的信息最大化(RIM),后者利用概率分类器,从而使输入和聚类分配之间的互信息最大化。同时,作者提出了一种灵活且有用的正则化目标,称为自我增强训练(SAT),这种数据增强技术显着提高了标准深度RIM的性能。
6、Joint Unsupervised Learning (JULE):16
Joint unsupervised learning of deep representations and image clusters(2016 c324)
JULE被用来学习特征表示和对图像进行聚类。CNN用于表示学习,层次聚类用于聚类。 它在循环过程中迭代地优化目标。分层图像聚类在前向中执行,而特征表示则在后向中学习。在前向传递中,图像的表示被视为初始样本,然后基于图像的深度表示从无向亲和矩阵生成标签信息。 此后,根据预定义的损耗度量将两个聚类合并。在后向过程中,网络参数被迭代更新,以通过优化已经合并的聚类来获得更好的特征表示。在实验中,该方法在图像数据集上显示了出色的结果,并表明所学习的表示可以在不同的数据集之间进行传递。 然而,当数据集很大时,由于需要构建无向亲和力矩阵,因此计算成本和内存复杂性非常高,并且由于它是一个密集的矩阵,因此几乎无法优化成本。
7、Deep Adaptive Image Clustering (DAC):51
Deep adaptive image clustering(2017 c110)
DAC是一种基于single-stage卷积网络的图像聚类方法。该方法基于以下基本假设:成对图像之间的关系是二进制的,其优化目标是二进制成对分类问题。图像由卷积神经网络提取的标签特征表示,而成对相似性则由标签特征之间的余弦距离来衡量。此外,DAC引入了一个约束条件,以使学习到的标签特征趋向于成为one-hot矢量。 此外,由于ground turth的相似性未知,它采用了自适应学习算法,这是一种交替迭代的方法来优化模型。在每次迭代中,基于固定网络选择具有估计相似性的成对图像,然后通过选择的标记样本对网络进行训练。
(三)VAE-BASED DEEP CLUSTERING
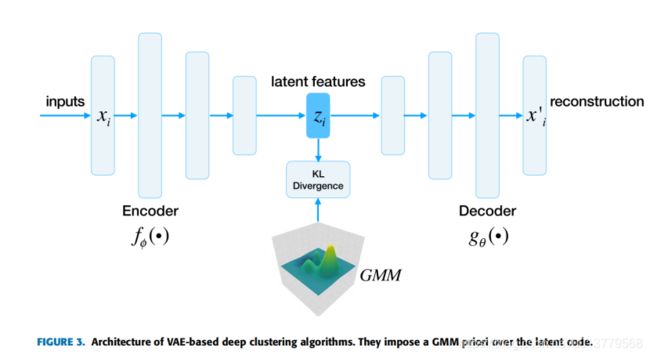
VAE可被视为AE的生成变体,VAE将变分贝叶斯方法与神经网络的灵活性和可伸缩性结合在一起。它引入了神经网络以适应条件后验,因此可以通过随机梯度下降和标准反向传播优化变分推理目标。它使用变分下界的重新参数化来产生下界的简单可微分的无偏估计量。该估计器可用于几乎任何具有连续潜在变量的模型中的有效近似后验推断。从数学上讲,它旨在最小化数据集X的边际似然的(变化)下界,目标函数表述为:
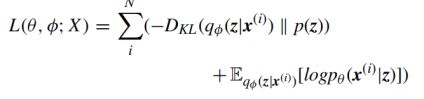
p(z)是潜在变量的先验。qφ(z | x(i))是难以处理的真实后验pφ(z | x(i))的变分近似,而pθ(x(i)| z)是似然函数。 从编码理论的角度来看,不可观测变量z可以解释为一个潜在表示,因此qφ(z | x)是一个概率编码器,而pθ(x | z)是一个概率解码器。总而言之,标准自动编码器与VAE之间的最大区别是VAE在潜在表示z上强加了概率先验分布。在常规VAE中,先验分布p(z)通常是各向同性的高斯分布。但是在聚类背景下,我们应该选择一个可以描述聚类结构的分布。如图3所示,现有算法选择混合使用高斯作为先验。换句话说,他们假设观察到的数据是从混合的高斯生成的,推断数据点的类别等效于推断数据点是从哪一种潜势分布模式生成的。在最大化evidence下界之后,可以通过学习的GMM模型来推断聚类分配。除了输出聚类结果之外,这种算法还可以生成图像,但是它们通常具有很高的计算复杂度。
1、Variational Deep Embedding (VaDE):15
Variational deep embedding: An unsupervised and generative approach to clustering
(2016 c197)
VaDE [15]考虑生成模型p(x,z, c) = p(x|z)p(z|c)p©,在此模型中,观察到的样本x是通过以下过程生成的:
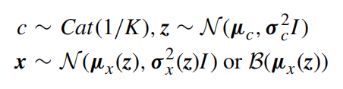
其中Cat(·)是分类分布,K是预定义的聚类数,µ和σ是与聚类c或由给定向量参数化的高斯分布的均值和方差。
N(·)和B(·)是分别由µ,σ和µ参数化的多元高斯分布和伯努利分布。调整VaDE实例以最大化给定样本的可能性。VaDE的对数似然可表示为:
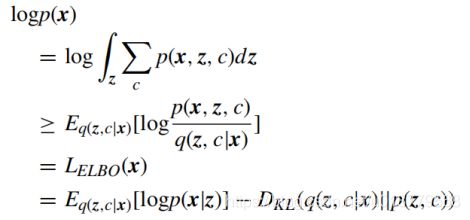
其中LELBO是证据下界(ELBO),q(z, c|x)是逼近真实后验p(z, c|x).的变化后验。公式6中的第一项是重构损失(网络损失Ln),第二项是从高斯混合(MoG)先验p(z, c)到变分后验Kullback-Leibler发散q(z, c|x),,可以考虑为聚类损失Lc。在下限最大化之后,可以直接从MoG之前推断聚类分配。
2、Gaussian Mixture VAE (GMVAE):55
Deep unsupervised clustering with Gaussian mixture variational autoencoders(2016 c211)
GMVAE [55]提出了类似的表述。 认为生成模型p(x,z, n, c) = p(x|z)pβ(z|c, n)p (n)p©。在此模型中,观察样本x的生成过程如下:
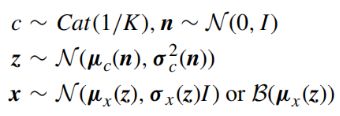
(四)GAN-BASED DEEP CLUSTERING
生成对抗网络(GAN)是近年来流行的另一种深度生成模型。GAN在两个神经网络(生成网络G和判别网络D)之间建立了最小-最大对抗博弈。生成网络试图将样本z从先前分布p(z)映射到数据空间,而判别网络试图根据数据分布计算输入是真实样本的概率,而不是生成网络生成的样本。目标可以表述为:
SGD优化生成器G和鉴别器D可以交替使用。GAN提供了一种对抗性的解决方案,可以将数据的分布或其表示与任意先验分布进行匹配。基于GAN的深度聚类算法具有GAN相同的问题,例如难以收敛和模式崩溃(mode collapse)。
1、Deep Adversarial Clustering (DAC):56
Deep adversarial Gaussian mixture auto-encoder for clustering(2017 c5)
DAC是专为聚类的生成模型。
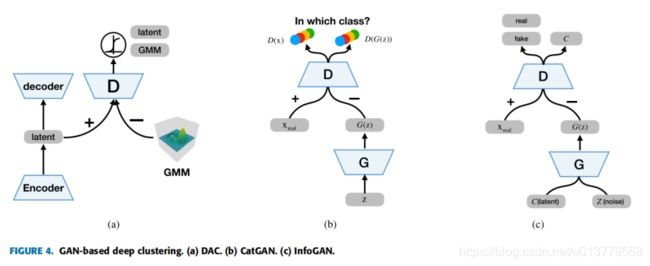
它将对抗性自动编码器(AAE)应用于聚类。AAE与VAE相似,因为VAE使用KL散度惩罚将潜在分布表示为先验分布,而AAE使用对抗训练程序将潜在表达的聚合后验与先前分布进行匹配。受VaDE成功的启发,Harchaoui等人将潜在表示的聚合后验与高斯混合分布进行匹配。网络架构如图4(a)所示。它的优化目标包括三个项:传统的自动编码器重建目标,高斯混合模型似然性和对抗性目标,其中重建目标可以视为网络损失,其他两个项是聚类损失。
2、Categorial Generative Adversarial Network(CatGAN):58
Unsupervised and semi-supervised learning with categorical generative adversarial
networks(2015 c478)
CatGAN将GAN框架归纳为多个类。如图4(b)所示,它考虑了无监督地从数据集中学习判别式分类器D的问题,该分类器D将数据点分类为优先选择的类别数,而不是仅两个类别(假或实数)。CatGAN引入了一种基于GAN框架的新的两人游戏:无需D来预测x属于真实数据集的概率,而是强制D将所有数据点分类为k个类,同时不确定由G生成的样本的类分配。另一方面,它要求G生成恰好属于k类中的一个的样本,而不是生成属于数据集的样本。数学上,CatGAN的目标是最大化H[p(c|x, D)]和H[p(c|D)],并最小化H[p(c|G(z), D)],,其中H [ ·]表示经验熵,x是真实样本,x是随机噪声,c是类别标签。LD所指的鉴别器的目标函数,LG所指的生成器的目标函数可以定义如下:
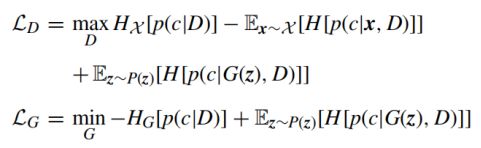
3、Information Maximizing Generative Adversarial Network (InfoGAN):59
Interpretable representation learning by information maximizing generative adversarial
Nets(2016 c2074)
InfoGAN是一种无监督的方法,可以学习解开表示disentangled representations,也可以用于聚类。它可以解开离散和连续的潜在因素latent factors,,扩展到复杂的数据集。
InfoGAN的想法是使GAN的固定小变量噪声变量和观测值之间的互信息最大化,这具体来说,如图4(c)所示,它将输入噪声矢量分解为两部分:不可压缩噪声z和潜码c,因此生成器的形式变为G(z,c)。 为了避免琐碎的代码,它使用信息理论正则化来确保潜码c和生成器分布G(z,c)之间的相互信息应该很高。InfoGAN的优化目标成为以下信息规范化的minimax游戏:
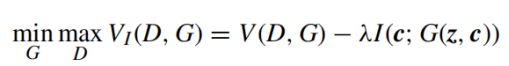
其中V(D,G)表示标准GAN的对象,而I(c; G(z, c))是信息理论正则化。
当选择用一个具有k个值的分类代码和几个连续的代码对潜在代码建模时,它具有将数据点聚类为k个聚类的功能。