(二十三)论文阅读 | 目标检测之DETR
简介

本文所介绍的论文是前段时间比较火的一篇关于目标检测的文章,它能够获得广大关注的主要原因是将 N L P {\rm NLP} NLP领域内广泛使用的 T r a n s f o r m e r {\rm Transformer} Transformer应用于 C V {\rm CV} CV领域,并取得了不错的结果。同时,它也简化了目标检测中常用到的 N M S {\rm NMS} NMS和 A n c h o r {\rm Anchor} Anchor等机制。实验结果为在 M S C O C O {\rm MS\ COCO} MS COCO数据集上获得了与同期 F a s t e r {\rm Faster} Faster- R C N N {\rm RCNN} RCNN相当的结果。论文原文 源码
在进行下面的部分前,我们首先来看一下有关 T r a n s f o r m e r {\rm Transformer} Transformer的内容。 T r a n s f o r m e r {\rm Transformer} Transformer来自于这篇文章,该论文将注意力机制发挥到了极致。简单来说,注意力机制就是使网络具有筛选信息的能力,即为输入信息赋予不同的权重。我们首先给出 T r a n s f o r m e r {\rm Transformer} Transformer的结构:
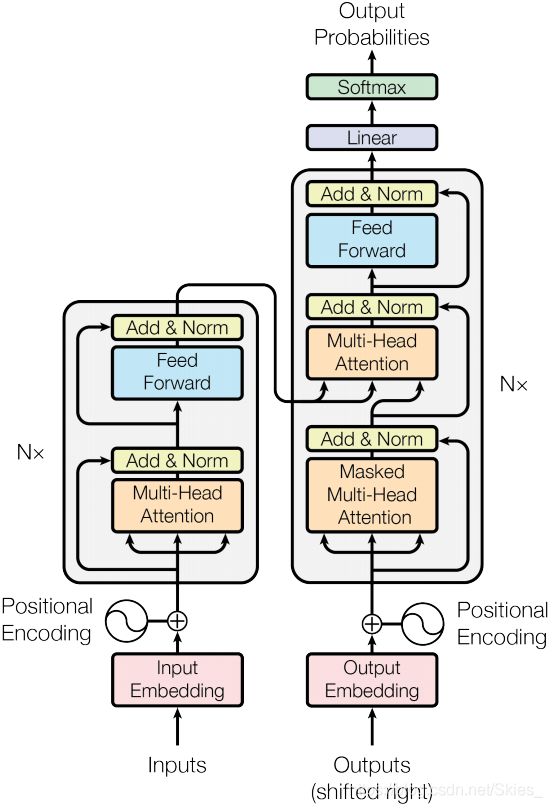
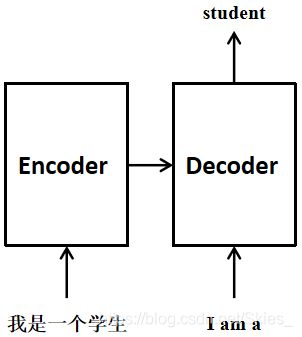
如上图, T r a n s f o r m e r {\rm Transformer} Transformer是一个编解码的格式。简单来说,在深度学习中,编码是指将输入信息抽象为特征,然后在解码过程将特征转化与输入有相同特征空间的输出。编解码器通常使用 C N N {\rm CNN} CNN或 R N N {\rm RNN} RNN实现。大多的语义分割模型就是一个编解码的过程,由于语义分割分割模型的输出特征图大小通常与输入图像一致,模型整体会经历一个先下采样、后上采样的过程。上图的左半部分用 N × {\rm N×} N×框出来的部分是一个编码器,右半部分用 N × {\rm N×} N×框出来的部分是一个解码器。在编码器中,第一部分是一个多头注意力模块,它的主要功能是平行地计算接受输入信息,并通过注意力机制为每个输入通道赋予不同的权重。第二部分是一个逐点全连接前馈模块,通过注意力机制进一步处理输入信息,并最后传递给解码器。两个部分均有一个残差连接,然后接一个标准化层。在解码器中,为了保证对上一次输出结果的上下文处理,在多头注意力模块的基础上使用一个掩膜。第二部分和第三部分同编码器的内容,只是接受的输入不同。在 N L P {\rm NLP} NLP中, T r a n s f o r m e r {\rm Transformer} Transformer的输入输出均是序列数据,模型通过对输入序列不断编码解码,依次得到对应的输出序列。如下图是文本翻译的例子:
上文只给出了 T r a n s f o r m e r {\rm Transformer} Transformer的简略信息,具体内容可参考相关专业文献。
0. Abstract
论文提出一种新的思路,将目标检测视为一个集合预测问题。该方法简化了目标检测流程,省去了手工设计的如 N M S {\rm NMS} NMS和先验框等操作。 D E T R {\rm DETR} DETR使用基于集合的全局损失函数,通过二分匹配和 T r a n s f o r m e r {\rm Transformer} Transformer的编解码结构得到检测结果。给定一个固定的目标查询集合, D E T R {\rm DETR} DETR通过目标对象及图像中的上下文信息,并行输出检测结果。最后, D E T R {\rm DETR} DETR可以获得与同期 F a s t e r {\rm Faster} Faster- R C N N {\rm RCNN} RCNN相当的结果。
论文贡献:(一)提出将 T r a n s f o r m e r {\rm Transformer} Transformer引用于目标检测的方法,并且得到了预期的结果,相当于为以后的目标检测提供一种新的方法论;(二)论文使用的模型结构非常简洁,不添加任何额外的 T r i c k s {\rm Tricks} Tricks就能获得与 F a s t e r {\rm Faster} Faster- R C N N {\rm RCNN} RCNN相当的结果;(三)主要为我们提供了一种思路,提出一种将深度学习两大领域( N L P {\rm NLP} NLP和 C V {\rm CV} CV)进行结合的有效方法。
1. Introduction
目标检测的目的是为图像中每个感兴趣目标预测一组边界框及相应类别。然后,当前大多目标检测方法通过回归和分类获得最终的检测结果。但作者指出,模型性能会严重受到后处理的影响。比如在处理近似重叠的目标时,先验框的设置并不能同时满足二者的检测需求。论文提出的方法简化了目标检测流程,该方法已经在诸如机器翻译和语义识别上大获成功。前人也有将其运用于目标检测中,但都是通过添加大量的先验知识或并没有取得如期的结果。
D E T R {\rm DETR} DETR将检测视为集合预测问题,简化了目标检测的整体流程。它主要采用了 T r a n s f o r m e r {\rm Transformer} Transformer的编解码结构,它在序列预测任务上大获成功。 T r a n s f o r m e r {\rm Transformer} Transformer中的自注意力机制显示地界定了序列中元素间的相互作用,因此可以用于约束集合的预测结果。
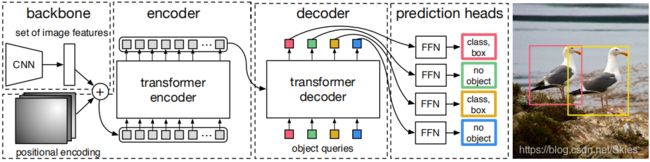
如上图是 D E T R {\rm DETR} DETR的检测流程,它一次性预测多个目标,并通过损失函数唯一地匹配预测结果和标注信息。 D E T R {\rm DETR} DETR不需要添加其他的特殊层,整个结构仅由 T r a n s f o r m e r {\rm Transformer} Transformer和 R e s N e t {\rm ResNet} ResNet组成。同时,在最后的二分匹配过程我们可以看到,产生的预测结果中不包含感兴趣目标类别时,它与空匹配。
与其他的集合预测问题相比, D E T R {\rm DETR} DETR的一大优势是将解码器同二分匹配损失函数结合,从而可以并行处理。该损失函数将预测结果唯一地与标注信息匹配,因而可以实现并行预测。
D E T R {\rm DETR} DETR在 C O C O {\rm COCO} COCO数据集上验证了其成功性,并与同期的 F a s t e r {\rm Faster} Faster- R C N N {\rm RCNN} RCNN相对比,获得了更佳的结果。但同时,尽管 D E T R {\rm DETR} DETR在大目标或中等目标上的检测结果较好,它对小目标的检测不具有鲁棒性。作者提出的相关解决办法是在 D E T R {\rm DETR} DETR中引入 F P N {\rm FPN} FPN以提升小目标的检测结果。
2. Related Work
2.1 Set Prediction
在深度学习中,没有特定的结构用于直接集合预测。最典型的集合预测任务当属多标签分类问题,但这类方法不可以直接迁移到目标检测中(目标检测中还需要对目标进行定位)。这类任务中首要问题是重复检测,当前目标检测方法使用的是非极大值抑制。但集合预测不需要后处理,它通过全局推理来预测元素之间的关系。同时,可以使用全连接网络预测固定大小的集合,但同时会带来庞大的计算量。一种可能的解决办法是使用自递归序列模型,如循环神经网络。在这种情况下,损失函数应该对预测目标保持不变,一种解决办法是使用匈牙利算法设计损失函数来唯一匹配预测结果和标注信息。与以往方法不同的是,论文没有采用自回归模型,而是使用了带并行编码器的 T r a n s f o r m e r {\rm Transformer} Transformer模型。
2.2 Transformers and Parallel Decoding
图 2 2 2展示了 T r a n s f o r m e r {\rm Transformer} Transformer的结构,注意力机制可以聚合输入信息。 T r a n s f o r m e r {\rm Transformer} Transformer引入自注意力机制,类似于非局部神经网络,它扫描序列中的每个元素并通过序列的整体信息来更新元素。基于注意力机制的模型的一大优势是可以进行全局推理且不会占据较大内存。 T r a n s f o r m e r {\rm Transformer} Transformer模型在文本翻译、语音识别等领域已大获成功。
同早期的序列模型一样, T r a n s f o r m e r {\rm Transformer} Transformer首先使用自回归模型逐个生成元素。但由于推理成本的限制,以并行的方式产生序列没能得到发展。作者提出的思路是将 T r a n s f o r m e r {\rm Transformer} Transformer同并行解码结合,在计算成本和集合预测所需的全局推理之间进行适当的权衡。
2.3 Object Detection
相关工作部分主要介绍了前人基于集合预测的目标检测方法,前文已经提到,大多数工作都要大量的人为的先验信息,这在一定程度上限制了网络的学习能力。
3. The DETR Model
D E T R {\rm DETR} DETR的两个关键是:利用损失函数完成预测内容和标注信息的唯一匹配以及预测一组目标及其之间的关系。如下图:
3.1 Object Detection Set Prediction Loss
首先, D E T R {\rm DETR} DETR产生一组固定的 N N N个预测结果( N N N远大于图像中的目标数)。接下来的关键是如何设计损失使得预测的结果同标注信息匹配。论文中的做法是:令 y y y表示标注信息, y ^ = { y ^ i } i = 1 n \hat{y}=\{\hat{y}_i\}_{i=1}^n y^={y^i}i=1n表示预测结果。我们将标注信息的集合填充为同预测信息的集合一样大( N > y N>y N>y,相当于将表示标注信息的集合的类别值填充为空、坐标值填充为随机量)。然后,为了找到这两个集合内元素的一一对应,定义如下: σ ^ = arg min σ ∈ N ∑ i N L m a t c h ( y i , y ^ σ ( i ) ) (1) \hat{\sigma}=\mathop{\arg\min}\limits_{\sigma\in N}\sum_{i}^{N}L_{match}(y_i,\hat{y}_{\sigma(i)})\tag{1} σ^=σ∈Nargmini∑NLmatch(yi,y^σ(i))(1)
对于第 i i i个标注信息 y i = ( c i , b i ) y_i=(c_i,b_i) yi=(ci,bi), c i c_i ci表示类别(可能为空)、 b i b_i bi是表示边界框的四维向量(中心点坐标和宽高)。对于预测信息, c i = p ^ σ ( i ) ( c i ) c_i=\hat{p}_{\sigma(i)}(c_i) ci=p^σ(i)(ci)、 b i = b ^ σ ( i ) b_i=\hat{b}_{\sigma(i)} bi=b^σ(i)。则 L m a t c h L_{match} Lmatch的定义如下: L m a t c h = − 1 { c i ≠ ∅ } p ^ σ ( i ) ( c i ) + 1 { c i ≠ ∅ } L b o x ( b i , b ^ σ ( i ) ) (2) L_{match}=-{\mathbb 1}_{\{c_i\ne\varnothing\}}\hat{p}_{\sigma(i)}(c_i)+{\mathbb 1}_{\{c_i\ne\varnothing\}}L_{box}(b_i,\hat{b}_{\sigma(i)})\tag{2} Lmatch=−1{ci=∅}p^σ(i)(ci)+1{ci=∅}Lbox(bi,b^σ(i))(2)
最后,整体的损失函数定义如下(这里,匈牙利算法可以为初始状态提供一个较佳的二分匹配,匈牙利算法的内容可以参考这里): L H u n g a r i a n ( y , y ^ ) = ∑ i = 1 N [ − l o g p ^ σ ^ ( i ) ( c i ) + 1 { c i ≠ ∅ } L b o x ( b i , b ^ σ ^ ( i ) ) ] (3) L_{Hungarian}(y,\hat{y})=\sum_{i=1}^{N}[-{\rm log}\hat{p}_{\hat{\sigma}(i)}(c_i)+1_{\{c_i\ne\varnothing\}}L_{box}(b_i,\hat{b}_{\hat{\sigma}}(i))]\tag{3} LHungarian(y,y^)=i=1∑N[−logp^σ^(i)(ci)+1{ci=∅}Lbox(bi,b^σ^(i))](3)
其中, σ ^ {\hat{\sigma}} σ^通过等式 ( 1 ) (1) (1)得到。考虑到在匹配时存在类别的不平衡( c i = ∅ c_i=\varnothing ci=∅),在实际计算时改变了对数部分的损失权重(类似于做到 F a s t e r {\rm Faster} Faster- R C N N {\rm RCNN} RCNN中正负样本比为 1 : 3 {\rm 1:3} 1:3)。同时,上述第一项中由于某些标注信息集合内的 c i = ∅ c_i=\varnothing ci=∅,所以该部分的分类损失为定值;而回归损失通过指示函数可以计算得到为零。
对于回归损失项,以前的目标检测算法的回归目标大都是预测值相对于标注信息的偏移,而文中使用的是直接回归的方式。 D E T R {\rm DETR} DETR的回归损失结合 l 1 l_1 l1损失和 G I o U {\rm GIoU} GIoU损失。其定义如下: L b o x ( b i , b ^ σ ^ ( i ) ) = λ i o u L i o u ( b i , b ^ σ ( i ) ) + λ L 1 ∣ ∣ b i − b ^ σ ( i ) ∣ ∣ 1 (4) L_{box}(b_i,\hat{b}_{\hat{\sigma}}(i))=\lambda_{\rm iou}L_{\rm iou}(b_i,\hat{b}_{\sigma(i)})+\lambda_{\rm L1}||b_i-\hat{b}_{\sigma(i)}||_1\tag{4} Lbox(bi,b^σ^(i))=λiouLiou(bi,b^σ(i))+λL1∣∣bi−b^σ(i)∣∣1(4)
其中, λ ∗ \lambda_* λ∗是超参数。
3.2 DETR Architecture
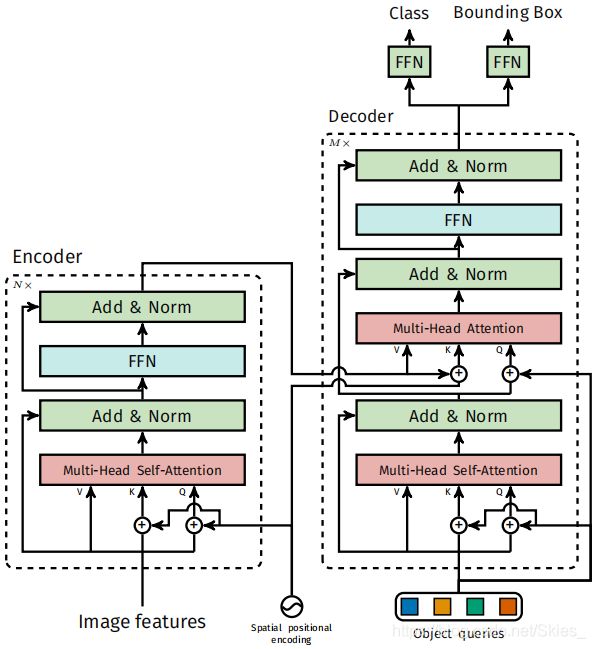
如图 5 5 5所示, D E T R {\rm DETR} DETR包含以下部分:提取特征的 C N N {\rm CNN} CNN部分, T r a n s f o r m e r {\rm Transformer} Transformer的编解码结构,用于检测的前馈网络 F F N {\rm FFN} FFN。 D E T R {\rm DETR} DETR的结构较灵活,能以极小代价迁移到任何带有 C N N {\rm CNN} CNN和 T r a n s f o r m e r {\rm Transformer} Transformer结构的模型中。
在提取特征部分,令输入图像为 x i m g ∈ R 3 × H 0 × W 0 x_{img}\in{\mathbb R}^{3×H_0×W_0} ximg∈R3×H0×W0,经 C N N {\rm CNN} CNN得到的特征图为 f ∈ R C × H × W f\in{\mathbb R}^{C×H×W} f∈RC×H×W。特征图的通道数为 2048 2048 2048,宽和高分别为 W 0 / 32 , H 0 / 32 W_0/32,H_0/32 W0/32,H0/32。
在输入 T r a n s f o r m e r {\rm Transformer} Transformer前,首先使用 1 × 1 1×1 1×1卷积将通道数由 C C C减小为 d d d,得到特征图 z 0 ∈ R d × H × W z_0\in{\mathbb R}^{d×H×W} z0∈Rd×H×W。由于编码器通常采用序列作为输入,首先将特征图的形状转化为 d × H W d×HW d×HW,然后加一个位置编码共同作为编码器的输入(由于在这里, C N N {\rm CNN} CNN没有提取图像中目标的位置信息,这里在输入编码器前加入一个可学习的位置信息,即位置编码。位置编码的概念来自 N L P {\rm NLP} NLP,是 T r a n s f o r m e r {\rm Transformer} Transformer中为了表征序列中各元素之间的位置信息,相关的内容可以参考源码的定义或相关资料)。
在解码器阶段,我们看到解码器的输入编码的输入外,还有一个名为目标查询的输入,这和 T r a n s f o r m e r {\rm Transformer} Transformer的结构相对应,这表示 N N N个论文中所预测目标。最后通过 F F N {\rm FFN} FFN产生边界框的坐标和类别信息。(每个预测目标单独使用一个 F F N {\rm FFN} FFN,通过并行处理,因此权重是共享的)通过编解码器的注意力机制,模型可以通过图像的全局信息来推理出预测内容和标注信息对。这就使得整个模型具有检测的功能。
上面提到的 F F N {\rm FFN} FFN其实是一个带有 R e L U {\rm ReLU} ReLU激活函数、 d d d个隐藏层单元的三层感知机。 F F N {\rm FFN} FFN预测边界框的归一化信息,并通过 s o f t m a x {\rm softmax} softmax层预测类别信息。由于模型得到的固定大小 N N N(大于图像中目标数)的预测结果,那些不带有类别的结果就类似于预测结果为背景。最后,用于本文的结构其实是这样的:
下面给出源码中给出的定义的部分:
class DETR(nn.Module):
def __init__(self, backbone, transformer, num_classes, num_queries, aux_loss=False):
super().__init__()
# 文中使用COCO数据集,定义N=100
self.num_queries = num_queries
# transformer
self.transformer = transformer
# 隐藏层单元数量
hidden_dim = transformer.d_model
# 由全连接得到分类embedding
self.class_embed = nn.Linear(hidden_dim, num_classes + 1)
# 由MLP得到边界框embedding
self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3)
# 目标查询embedding
self.query_embed = nn.Embedding(num_queries, hidden_dim)
# CNN得到特征后通过1×1卷积降维
self.input_proj = nn.Conv2d(backbone.num_channels, hidden_dim, kernel_size=1)
# backbone
self.backbone = backbone
# 辅助的解码器部分的损失
self.aux_loss = aux_loss
def forward(self, samples: NestedTensor):
# 通过CNN得到特征
features, pos = self.backbone(samples)
src, mask = features[-1].decompose()
# 将相关内容送入transformer
hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0]
# 分别产生分类结果和回归结果
outputs_class = self.class_embed(hs)
outputs_coord = self.bbox_embed(hs).sigmoid()
# 得到最终输出
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
if self.aux_loss:
out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)
return out
可以看到,上述代码的流程同图 5 5 5中的内容一致。
4. Experiments
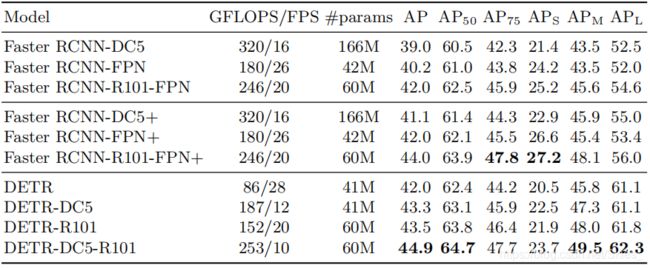

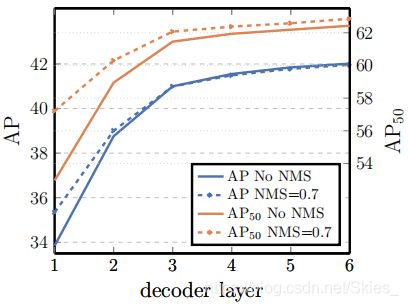
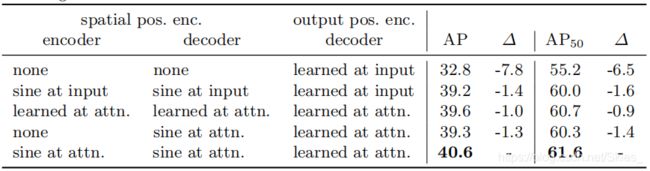

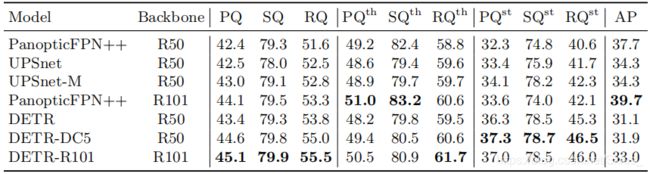
由上图我们可以看到,由于 l 1 l_1 l1损失无法满足多尺度目标的检测( l 1 l_1 l1针对不同尺度的目标的回归方式采样绝对值,而不能有效反应不同尺度目标与标注目标的重叠情况),所以仅使用 l 1 l_1 l1时效果较差。最后,作者还重新设计了检测头,将 D E T R {\rm DETR} DETR用于实例分割。下图展示了相关实力分割方法的实验结果对比:
5. Conclusion
由全文可以看到,将 T r a n s f o r m e r {\rm Transformer} Transformer应用于目标检测中同样能取得不错的结果。同时我们要看到,论文中使用的 D E T R {\rm DETR} DETR仅是普通 C N N {\rm CNN} CNN、 T r a n s f o r m e r {\rm Transformer} Transformer和 F F N {\rm FFN} FFN的结合,类似于目标检测中的主干网络、网络颈以及网络头,期间不添加其他的操作。论文的关键是将特征输入 T r a n s f o r m e r {\rm Transformer} Transformer后依旧要保持目标的位置信息以及最后通过合适的方法将预测结果同标注信息匹配。总的来说,这是当前目标检测领域内比较新的一种思路。同时在论文中,作者也提出为原始模型中加入 F P N {\rm FPN} FPN以改善小目标的检测结果。最后,由于本人对 N L P {\rm NLP} NLP了解甚少,相关内容可参考专业文献。
参考
- Carion N, Massa F, Synnaeve G, et al. End-to-End Object Detection with Transformers[J]. arXiv preprint arXiv:2005.12872, 2020.