Community detection based on the Matthew effect
贡献:提出了一种基于马太效应的群落检测新方法CDME来揭示网络中的群落结构。
优点:实现了高质量的社区分区。此外,CDME算法不需要参数设置或网络结构的先验知识。重要的是,由于CDME的时间复杂度较低,它可以用于识别大规模网络中的社区结构。
基本思想
什么是马太效应:在现实世界中,只有少数人拥有大部分的资源,而这些优势吸引了更多的人加入他们。
实例(玩具网络):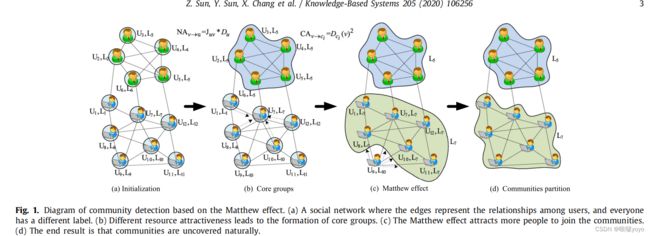
第一阶段,每个人都有自己的资源和一个独立的群体,如图1(a).所示
第二阶段,资源更多的人吸引邻居加入并形成最初的核心群体。例如,由于用户U7拥有更多的资源,从而吸引U1、U8、U10和U12加入其组,如图1(b)所示
第三阶段,由于马太效应,越来越多的人被吸引加入核心团体。例如,用户U9被一个标签为L7的组所吸引,如图1(c).所示
最后,每个人都被吸引到不同的社区,社区结构自然暴露,如图1(d).所示
CDME算法在复杂网络中的社区检测中理想的特性
新的观点:我们从一个新的角度来考虑社区检测的问题:马太效应,它以一种自然的方式揭示了一个网络中的社区结构。
高性能:与几种具有代表性的社区检测方法相比,CDME算法已被证明更有效,并且可以在合成网络和真实网络中找到高质量的社区。(cf.图中。表3和表4,以及表6和表7)。这是因为CDME方法不仅考虑了节点到节点的影响,而且还考虑了社区对它的影响。
无参数:CDME方法不需要依赖于先验知识和参数设置的算法,而是不需要参数设置,并且社区结构是基于马修原理自动揭示的。
可伸缩性:由于局部交互模型,CDME只需要计算相邻节点的吸引力,这导致了O(n·k2)的时间复杂度较低。k的值通常都很小。因此,CDME算法可以应用于大规模网络。
基于图形分区的方法
参数表

准备工作
定义1(Jaccard相似度系数[44])。给定一个无向网络G =(V,E),定义节点u和v的Jaccard相似系数为

其中,Γu = N (u)∪{u}。它是节点u的一组邻居,由节点u及其直接连接的节点组成。N (u)表示u的邻居节点。
(用于比较有限样本集之间的相似性与差异性。Jaccard系数值越大,样本相似度越高。)
(在现实世界中,人们都有自己的资源和爱好。具有相同爱好的人更有可能相互吸引,形成一个社区。) 为了描述节点之间的吸引力,我们使用节点的度和节点之间的相似性来表示节点之间的吸引力。
定义2(节点吸引点)。给定一个无向网络G =(V,E),节点u对v的吸引力定义为
其中Juv表示节点u和节点v之间的Jaccard相似系数,Du表示节点u的度。
同样地,社区对网络中的节点也很有吸引力。(例如,一个著名的足球俱乐部吸引了许多足球运动员加入这个球队。)在这里,我们使用社区内节点的连通性来描述社区对节点的吸引力。
定义3(社区吸引力)给定无向网络G =(V,E),一个社区对节点v的吸引力定义为
![]()
其中Dci (v)表示从一个节点v到一个社区ci的连通性程度,它描述了一个节点与一个社区的距离。根据从一个节点到不同社区的边数,有两种情况,一种情况是边数不同,另一种情况是边数相同。在形式上,我们对Dci (v)的定义如下:
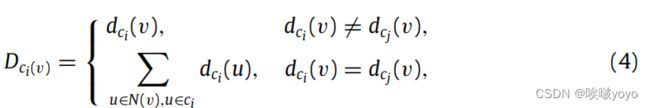
其中,dci (v)是社区ci中节点v的内部度。当存在一个节点到不同社区的边数相同时,节点v到社区ci的连通性等于节点v的邻居节点中属于社区ci的点到社区ci的连通性之和。
社区吸引力例子

对于节点6、dci (6) = 2和dcj (6) = 1,我们可以得到dci (6) =不等于dcj (6)、dci (6) = 2和dcj (6) = 1。因此,CA6→ci=4和CA6→cj=1,以及节点6可以加入社区ci,具有更大的社区吸引力。对于节点13,因为dci(13)= dcj(13),所以我们需要考虑间接邻居对节点13的影响。根据等式的第二部分(4),我们可以计算出两个群落对节点13的社区吸引力分别为CA13→ci=16和CA13→cj=9。因此,社区ci对节点13具有更大的吸引力。
马修效应模型
首先,每个节点作为一个单独的组,每个节点都有自己的资源。接下来,由于共同的兴趣爱好,一些节点被其他节点吸引形成核心组。然后,由于马太效应,越来越多的节点被吸引到加入核心组中来。最后,每个节点都被吸引到不同的社区中。
(1)初始化:(在现实世界中,一个人拥有的朋友越多,他或她可能拥有的资源就越多。)我们使用一个节点的度来描述它所拥有的资源。一开始,每个节点都有自己的资源,每个节点都被视为一个独立的社区。
(2)核心组:(在现实生活中,人们在一个社区中扮演着不同的角色,拥有不同的资源。这个人越重要,他或她就越有可能吸引人们加入这个社区。)网络中的每个节点也有自己的资源来吸引其他节点。我们使用 节点吸引力 来描述节点之间的吸引(cf。Eq (2)).由于节点的吸引力,每个节点都吸引其邻居加入它的社区。换句话说,每个节点根据来选择吸引力最强的邻居节点。
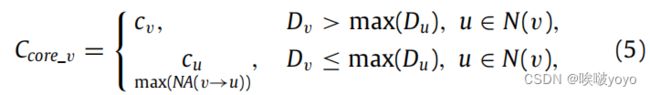
其中,Ccore_v表示节点v所属的核心组,Dv为节点v的度。如果节点v与邻居节点相比,节点v的度最大,则节点v仍然属于原始组cv。相反,如果一个邻居节点的度大于节点v,则节点v选择节点吸引力最大的邻居u(NA(v→u))并加入节点u所属核心组。通过一轮迭代,拥有更多资源的节点更有可能吸引他们的邻居加入他们的社区,并形成许多核心组。
(3)马太效应:在得到核心分组后,会有越来越多的节点被吸引到不同的核心分组中

其中Ci为节点v的邻域社区,CAv→ci表示社区Ci对节点v的吸引力。(在现实世界中,团队越好,它就会吸引到更多的关注和参与。)类似地,一个节点自然会选择最有吸引力的社区来加入。当一个节点加入一个社区时,这个社区的结构可能会改变,它的吸引力也可能会改变。
因此,我们迭代地引入马太效应。在每次迭代中,每个节点都会更新其社区标签。
最后,受网络拓扑结构的驱动,直到节点所属的社区不会改变,网络结构达到了一个平衡状态。然后,该网络的社区结构也被自然地揭示出来。
CDME算法
评价标准

模块度Q——复杂网络社区划分评价标准_wangyibo0201的博客-CSDN博客_模块度
NMI(Normalized Mutual Information) 归一化互信息,NMI衡量的是预测的社区与真实社区的接近程度。其定义如下

其中,I(X;Y)为X(真实群落)和Y(预测群落)之间的互信息,H (X)表示X的熵。NMI的值范围为0到1。NMI = 1表明,预测的社区与真实社区完全匹配。相比之下,NMI = 0表明,预测的群落完全独立于真实社区。
互信息是信息论里一种有用的信息度量,它可以看成是一个随机变量中包含的关于另一个随机变量的信息量,简明的说就是,表示两个事件集合的相关性。
调整兰德系数(Adjusted rand index) ARI 它度量两个集群之间的相似性。其定义如下
兰德系数(Rand index,RI)需要给定实际类别信息 C,假设 K 是聚类结果,a 表示在 C 与 K 中都是同类别的元素对数,b 表示在 C与 K 中都不是同类别元素的个数,则兰德指数为
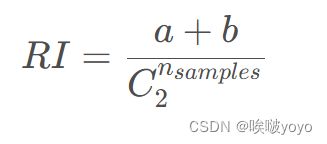
其中,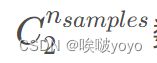 数据集中可以组成的总元素对数,RI 取值范围为[0, 1],值越大意味着聚类结果与真实情况越吻合。
数据集中可以组成的总元素对数,RI 取值范围为[0, 1],值越大意味着聚类结果与真实情况越吻合。
对于随机结果,RI 并不能保证分数接近零。为了实现 “在聚类结果随机产生的情况下,指标应该接近零”,调整兰德系数(Adjusted rand index, ARI)被提出

Y和X分别是聚类结果和标签
调整兰德系数(Adjusted rand index) ARI 取值范围为 [-1,1],值越大意味着聚类结果与真实情况越吻合。从广义的角度来讲,ARI 衡量的是两个数据分布的吻合程度。
优点:
对任意数量的聚类中心和样本数,随机聚类的 ARI 都非常接近于 0;
取值在 [-1, 1] 之间,负数代表结果不好,越接近于 1 越好;
可用于聚类算法之间的比较。
缺点:ARI需要真实标签
聚类纯度

cluster1中三角形最多,把cluster1看作是三角形的簇,那么这里面三角形一共有5个
cluster2中圆形最多,把cluster2看作是圆形的簇,那么这里面圆形一共有4个
cluster2中正方形最多,把cluster3看作是正方形的簇,那么这里面正方形一共有3个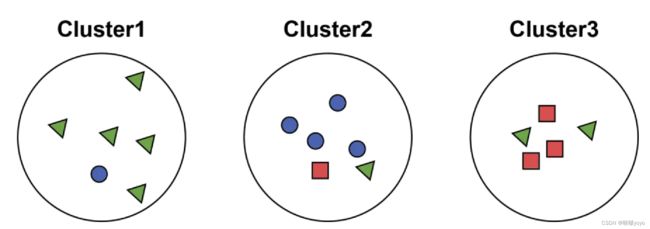
结论
在本研究中,我们提出了一种新的、功能强大的算法CDME来自动揭示复杂网络中的社区结构。首先,我们给出了节点吸引力的广义定义,它可以用来捕获核心组。然后,我们仔细研究了网络中节点之间的动态模型,并提出了一种新的马太效应模型,该模型将网络视为一个社会系统,模拟了节点之间的交互。进一步,我们设计了一个基于马修效应模型的社区检测算法来模拟该过程。最后,我们将CDME与几种具有代表性的社区检测方法与合成网络进行了比较。大量的实验表明,CDME在高质量的大小网络中检测社区的效果较好,优于评价中考虑的比较算法。关于未来的工作方向,我们计划将其扩展到动态网络和超大网络上的CDME。
在本研究中,我们提出了算法CDME来揭示复杂网络中的社区结构。首先,我们给出了节点吸引力的广义定义,它可以用来求得核心组。然后,我们仔细研究了网络中节点之间的动态模型,设计了一个基于马修效应模型的社区检测算法来模拟该过程。算法具备的良好性能如下:首先,该算法比上述其他算法具有更高的效率和更好的社区检测质量;其次,该算法不需要设置参数,更简单、方便;第三,算法的时间复杂度小,可以应用于大规模网络;其次,该算法源自自然,符合自然规律,更接近真实网络,可以更好地应用于社区检测。