Shader学习笔记:投影矩阵及其应用
好久好久没有更新博客了,去年考完研以后直接摆了好几个月,刚刚开始学习又遇到了一些很受挫的事情,之后写了一大堆草稿也该好好总结一下之前做过的东西了,重新写博客当然就从一些理论上的东西开始写才行,这篇博客主要讲述投影矩阵的推导以及投影矩阵的一些简单需求。首先我们假设一个矩阵ProjectionMatrix,它的值都是未知数:

而我们假设相机空间的某一个点的坐标可以表示为:
![]()
从相机空间到投影空间的工序
对于相机空间的一个点而言,它要转移到投影空间去仅有两步:
- 将该点投影到近裁剪平面
- 使其值的范围线性映射到[-1,1]范围内
设视锥体的近裁剪矩形边长的数据有:X轴正方向值为r,负方向值为l,Y轴正方向值为t,负方向值为b,Z轴近裁剪平面值为n远裁剪平面为f。那么近裁剪矩形的四个顶点为:
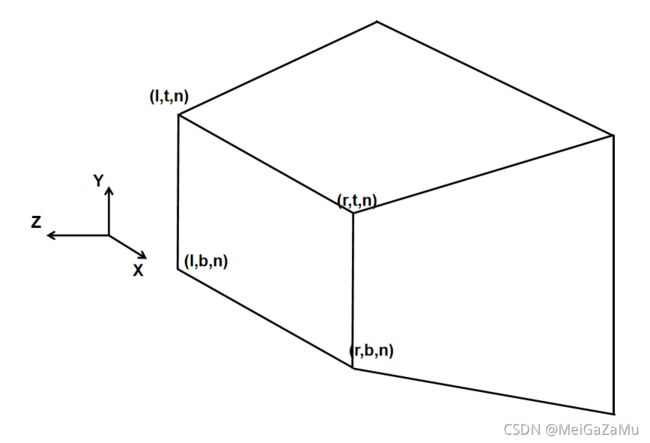
那么,对于相机空间的的每个点,XYZ轴分量映射的关系是:
- X从[l, r]映射到[-1,1]
- Y从[t, b]映射到[-1,1]
- Z从[n, f]映射到[-1,1]
所以对于一个相机空间坐标而言,只需要这两步就可以将其转换到NDC空间,如下图(之前水面的文章使用过这张图)所示,这是一个相机空间的点A:

相机空间XY轴分量的投影计算
首先我们将它投影到近裁剪平面上,为了便于计算,我们先只看XZ平面的情况,如下图,设近裁剪平面为的值为n,远裁剪面的值为f,在XZ平面有一点P(X,Z),它在近平面的投影为P′(X′,-n),如图:
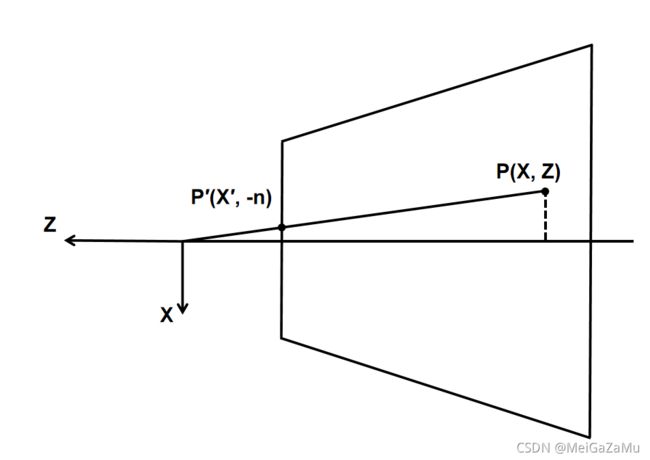
根据相似三角形,我们可以知道P与P′轴的分量关系,并且进而可以推知X与X′的关系:

同理可知在YZ平面中Y与Y′的关系:
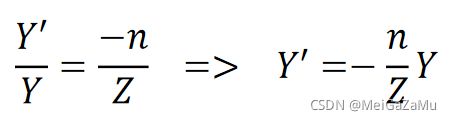
从上文的式子可以看出,X′与Y′都与点的相机空间Z分量有关,在相机空间的点乘以矩阵的时候,可以想办法将相机空间Z分量保留下来,以用于在后续处理中得到正确结果。那么,ProjectionMatrix的最后一行可以设置为:
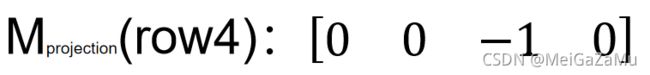
当一个坐标值乘以这一行以后,得到的一定是相机空间坐标Z分量的负数,也可以说乘以矩阵后的W分量一定是-Zview。
线性映射
将某一个取值范围的值转移到另一个取值范围中去,它们的线性映射关系可以用以下方式得到公式。例如处于[Amin,Amax]的坐标转移到[Bmin,Bmax]中,它们的线性映射关系有:
设[Amin,Amax]到[Bmin,Bmax]的线性关系为:F(X)=aX+b。且由于线性映射,两个对应的端点都是一一对应的,有如下关系:
进而可知:
将两个式子联立那么我们可以得到a的表达式:
将a带回上面的联立公式,我们也可以知道b的值:
我们将a和b的值带回F(X)可以知道其线性映射函数的样子:
然后化简可以得到两个区间之间的映射函数:
只要我们知道两个区间的范围,使用该函数就可以非常简单的将其映射到另一个区间去,这个公式也是下文中常用的公式。

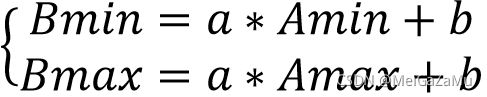
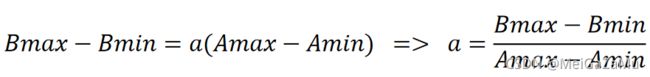
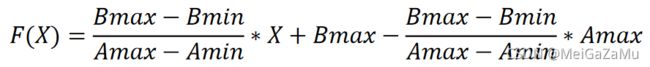
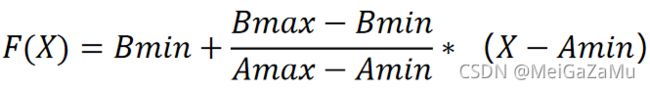
既然已经得出了映射的函数,我们将相机空间的XY分量投影到裁剪空间。
对于X′而言,将其从[l,r]映射到[-1,1],将这些值代入到上文中的Amax、Amin、Bmax、Bmin,代入并化简可得投影空间中的Xproj与相机空间近裁剪平面的X′的关系:
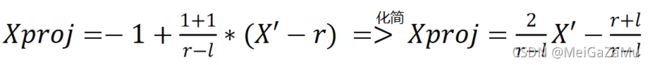
在上文中我们也推导出了X′与相机空间真正的X轴分量关系,有:
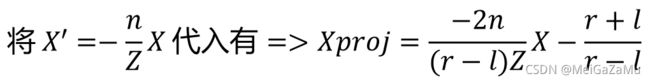
将这个式子通分,可以得到投影空间Xproj与相机空间的X分量和Z分量的关系:

同理,我们也可以得到投影空间Yproj的值与相机空间Y分量和Z分量的关系,只需要简单地把r和l替换成t与b:
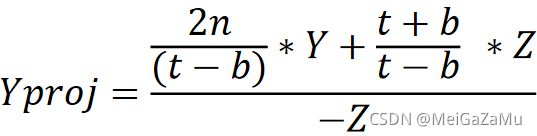
这里对应了上文中为什么我们要将-z保留起来了,它可以不参与矩阵乘法的计算,完全可以等到乘完矩阵再单独处理 ,那么我们只看Xproj和Yproj的分子,除去X(或Y)分量和Z分量,剩下的都是视锥体的参数,我们把这些参数抽出来构成投影矩阵计算Xproj和Yproj的前两行,可以很轻易的得出:
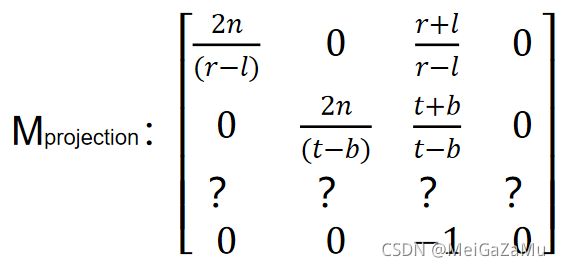
这样我们前三行都得出来了,这个矩阵只要左乘以相机空间坐标[X,Y,Z,1],就能得到正确的投影空间的XY值。而对于Z轴的变换则需要单独计算。
相机空间Z轴分量的投影计算
XY轴都很简单地能得出结果,但是对于Z轴而言就有一些变化了,这里的说法取材自《3D游戏与计算机图形学中的数学方法》,对于一个屏幕上的像素,其都一一对应了相机空间三角形面片里的一个点。如果按照XY分量的线性关系,Z和Zproj理论上应该是线性的。但是我们知道,屏幕上的每个像素的间距必须是一致的,相机根据这些距离一致的像素点采样到的三角形面片的点却不能一一对应,所以如果仍然使用XY的线性关系去推导投影空间中Z的值就会出现偏差。
既然相机空间的Z与Zproj不是线性的,就要根据图像推导的Zproj与相机空间的值的关系(这里不讨论n的符号):
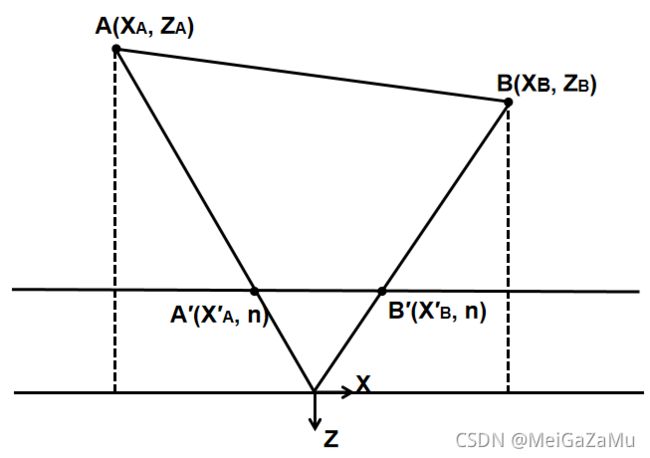
如图即为XZ平面中有一条直线AB被映射到了近裁剪平面上,这个直线的方程为aX+bZ=c。如果C==0,则直线过相机原点不会被映射到,所以这个直线的C不等于0。根据上文的推导,XA′与XB′的值和关系有:

我们将XA和XB代入回直线方程,可以知道:ZA和ZB与XA′和XB′之间的关系:
![]()
对于近裁剪平面上的XA′和XB′而言,线段真正的变成屏幕上的像素需要一步步插值才能着色,我们假设这个线段在近裁剪平面插值系数为s,那么存在一个近裁剪平面上的线段插值后的X′,如图所示:
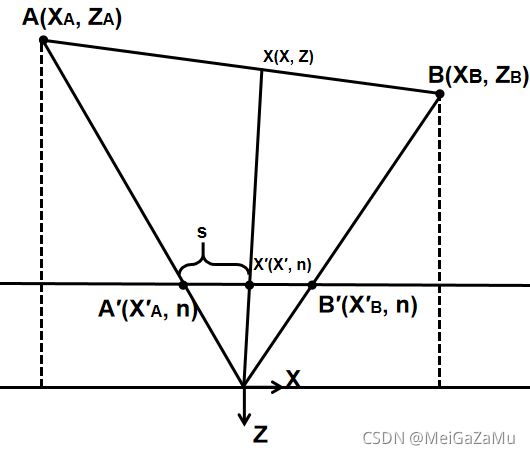
X′与XA′和XB′有线性插值关系,且根据上面的推导X′和其对应相机空间线段上的Z分量也有关系,它们分别是:
![]()
既然我们知道X′,又知道Z的与X,将上面两个式子联立,有,可以得到公式:

化简可得,相机空间线段上投影前的Z与ZA和ZB的插值公式:
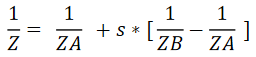
从这个公式中我们可以看出,对于相机空间的一个点来说,其坐标Z分量的倒数在投影之后与近裁剪面的插值系数与相机空间线段端点Z轴倒数构成线性插值,那么根据这个倒数的关系我们可以定义相机空间的Z轴分量从[-f,-n]到[-1,1]映射函数为:
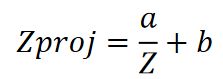
我们已知两个端点的值,和上文计算Xproj和Yproj一样带进去,可以得出a,b的值:

那么我们就得出了相机空间的Z轴映射到[-1,1]的Zproj的式子:
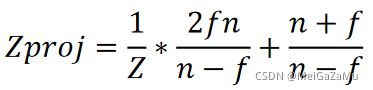
为了和上文中的XY轴规划整齐,我们将相机空间Z作为总分母,写成一个规范的样子有:
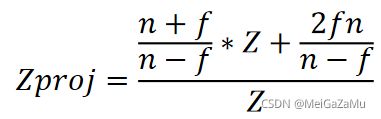
这个公式的分子就是投影矩阵的第三行了,即有[0,0,n+f/n-f,2fn/n-f]*[x,y,z,1]就能得到上文中的分子,然后Z再如图XY轴分量一样进行其次除法就能得到正确的投影空间Z轴分量了。我们可以很轻松地写出完整的投影矩阵:

如果视锥体的是根据相机空间的XYZ轴对称的话,我们可以知道有:r=-l,t=-b。投影矩阵就能简化,有:
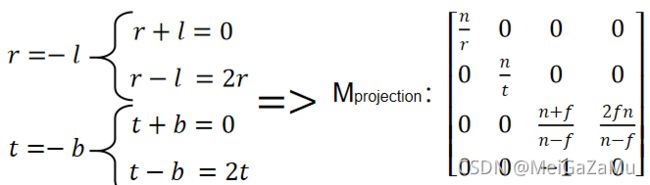
当然在实际操作中的矩阵是上文中的转换形式,这是因为在实际中不会使用视锥体的长宽的r、l、t、b等值,取代这些值进行计算的是相机的FOV(Field of view,即相机视锥体竖直方向上的开角)、和相机的纵横比aspect,我们用这两个值来表示上文中的矩阵。
如下图,表示视锥体的YZ的切面,假设视锥体的竖直方向的开角为α,视锥体近裁剪平面搞高为h:
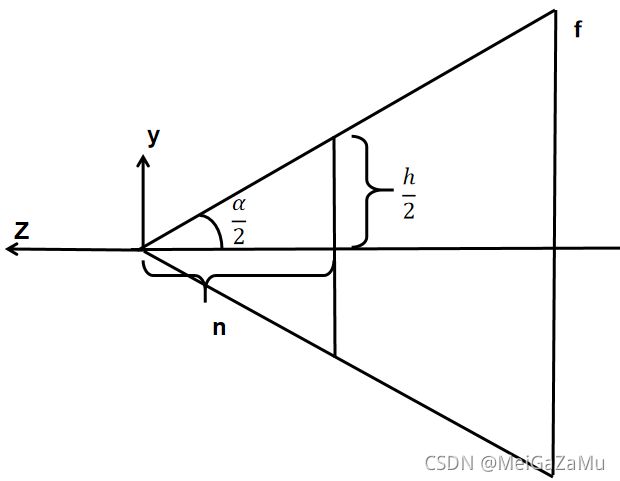
从这个切面我们可以得出一些值之间的关系,比较凑巧的是,h/2正好就是上文矩阵中的t,所以cot α/2正好就是投影矩阵第一行第一列的值
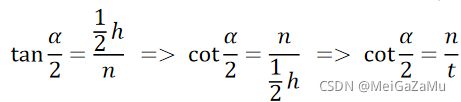
用同样的方法来看视锥体XZ的切面,假设视锥体横向的开角为β,视锥体近裁剪平面宽为w:
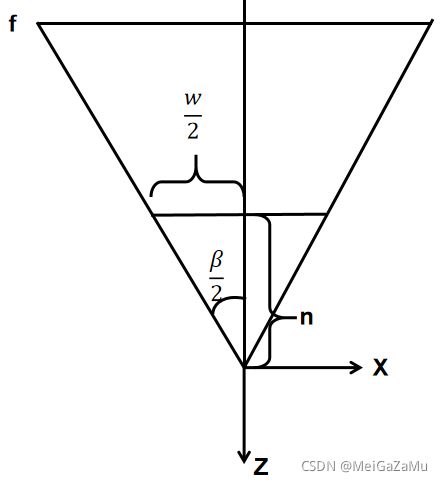
和上面的一样,我们可以得出β角和视锥体参数的关系:
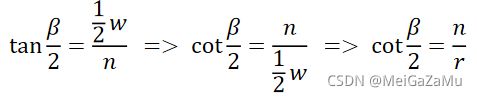
这样我们投影矩阵就可以改写成:
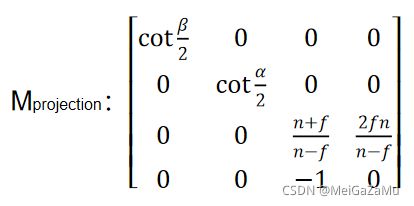
此时,我们假设一个视锥体的纵横比aspect,它为视锥体近裁剪平面宽度w和高度h的比值,如果进一步稍微探索一下aspect,就可以用它可以用来表示竖向夹角α和横向夹角β的关系:
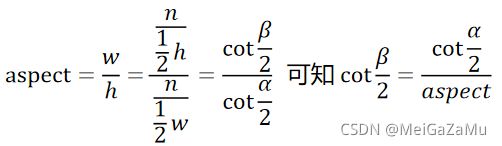
那么投影矩阵最终可以写成:
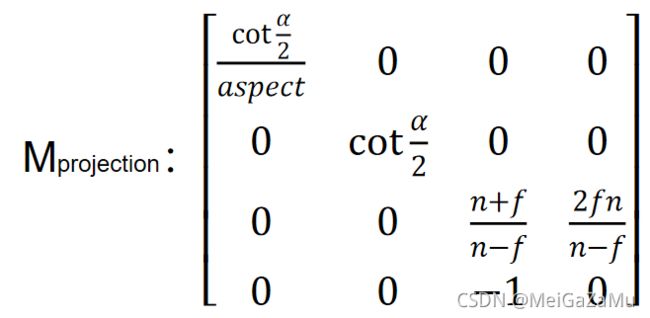
这个写法就是矩阵的一般写法,例如unity中,常见的参数FOV即为上图中的α,也给定了纵横比的值aspect,无论是在Shader或者是C#中都能方便地调用他们,这样我们就没有必要知道具体的视锥体近裁剪平面的参数,而是知道一个比例和竖直方向的开角,再加上近远裁剪平面的距离就行。
当我们相机空间的点经过左乘以该矩阵,再经过透视除法(即统一除以投影坐标的W分量),就可以得到NDC空间坐标了,然后再映射到[0,1]范围内投影乘以屏幕像素的值,最后的XY就是每个点的屏幕坐标了,而Z就保存到深度图里以供采样。
投影矩阵的运用
一般在写Shader时,我们每次使用投影矩阵都是Unity提供的,所以投影矩阵写了这么多,在代码中也只有一行而已,但是,在平常的操作中有很多地方有涉及到了投影矩阵。
深度采样
在Shader中深度采样是一个很常用的操作,但是我们在采样时都是靠着UnityCG中的函数来得到depth的,相机空间的Z分量在上文中的投影变换——齐次除法——映射到[0,1]后,其值为:
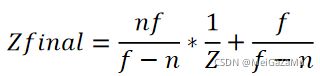
当我们使用屏幕坐标采样深度图时,得到的值就是这个Zfinal,但是这是被“加工”了很多工序的值,我们需要使用视锥体的参数来倒推出相机空间的Z分量。这些操作被整合在了LinearEyeDepth和Linear01Depth两个函数里:
// Z buffer to linear 0..1 depth
inline float Linear01Depth( float z )
{
return 1.0 / (_ZBufferParams.x * z + _ZBufferParams.y);
}
// Z buffer to linear depth
inline float LinearEyeDepth( float z )
{
return 1.0 / (_ZBufferParams.z * z + _ZBufferParams.w);
}
这里使用了_ZBufferParams中的操作进行还原,它的四个参数分别是:
将这些值代入到上文中的函数中,可以得到:
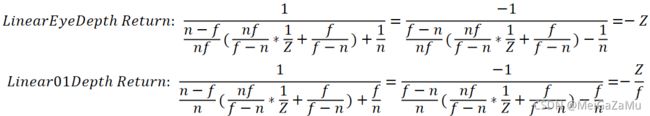
由于坐标系的不同,相机空间的Z轴负值才是真正的深度,那么LinearEyeDepth返回的值是正确的,而相机空间Z轴值处于[-f,0]范围内,则-Z/f 就能得到[0,1]范围内的深度。
Reverse_Z操作
对于相机空间的Z轴分量而言,其有用的值处于[near,far](不考虑负号)以内,对于Z而且,其值是线性的(距离越远值就越大),但在投影插值的时候,使用的是1/Z,这时就会因为float精度问题出现精度的异常现象:当相机空间Z轴分量以1/Z的形式存储在深度图的时候,由于浮点数的特性,可能会产生一些错误,产生Z-Fighting问题。其本质为,1/Z使得过密的精度在near处造成浪费而在far处过于稀疏而造成精度不正确。为了解决这个问题,在一些平台会修改投影矩阵,使得Z轴本来由[near,far]映射到[0,1]而改为映射到[1,0],以使得从深度图中还原出来的深度在[near,far]中精度更好,在这里不过多叙述float的精度问题,仅仅是理解一下平台做了哪些操作,具体的原因与细节可以看这篇文章。
对于矩阵而言,仅仅只是一些符号的变化,经过齐次除法后:

在平时的代码书写中,如果发现定义了UNITY_REVERSED_Z,可以直接用1减去从深度图中采样到的值以得到正确的屏幕空间深度:

相对的,如果是开启了Reverse_Z的_ZBufferParams也会有所修改,其值为:
根据翻转后的_ZBufferParams也能使翻转后的屏幕空间Z分量转移回相机空间,有:
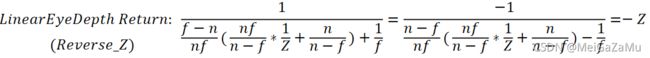
根据上文中的方程,在代码应用深度的时候我们需要注意:
- 随着像素深度由近到远,视角空间Zview的值由小到大(这一点很符合直觉),如果是01范围内的Zview,则离摄像机最近的深度为0,最远的(例如背景)的深度为1.
- 随着像素深度由近到远,裁剪空间Zclip的值由大到小(因为Zview是分母)。最远的像素的Zclip值接近于0但不等于0,这是因为Zclip加上了一个近裁剪值和远裁剪值的系数。
透视插值问题
在SSR中,为了步进精度,有时需要将相机空间射线映射到屏幕空间,然后在屏幕空间中推导该像素在相机空间的深度值,这个时候需要重新梳理一下屏幕空间与相机空间的深度关系。对于一个相机空间上的线段,我们假设它在相机空间的线段上的插值为t,如下图:
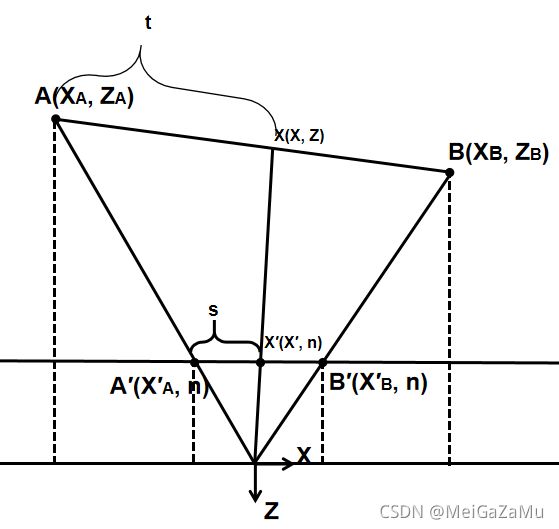
从这个图像中的值有如下的关系:
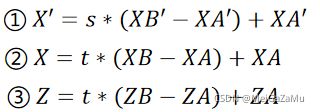
且由于相似三角形的关系,有:
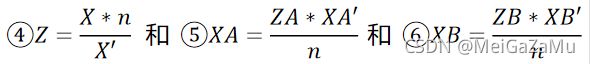
我们将上面①②④⑤⑥四个式子联立可以得出:
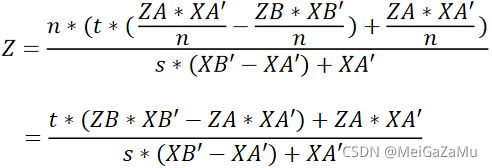
同时,我们代入③式,此时有:
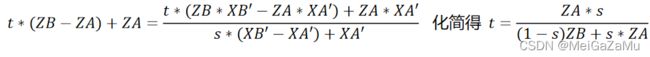
这里的化简计算起来比较复杂,需要将ZA减到右边通分,然后将ZB-ZA移到右边通分硬算才能求出来,但是最终我们能得到相机空间插值t与投影空间插值s的关系,这个关系厘清了透视插值系数的关系。同时可以往回推,可以推导出相机空间插值的深度关系,即上文中出现了很多次的式子:
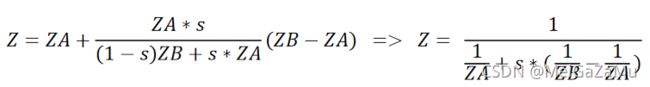
如果要计算X点在XY轴上的插值,可以同样的从上图中观察出有X点和X′点有相似三角形的比例关系:

同时,我们也知道,X′近裁剪平面是用s与XA′和XB′进行插值的,而XA′与XB′与相机空间的线段端点的XA和XB有相似三角形的比例关系:
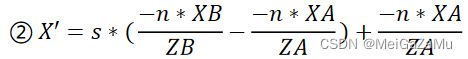
将①②式联立,我们可以得到相机空间插值点X轴分量与端点关系:

我们将上式稍微扩展一下,对于屏幕空间的一个像素而言,若在片元着色器没有指定,它的属性都将由三角形的端点插值而来, 这些属性不仅包括该值坐标,也包括颜色。我们假设线段一个端点的属性为I,属性I由近裁剪平面插值系数和两端点的属性I和对应Z轴分量插值而来:
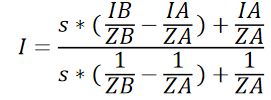
在屏幕空间的SSR中,如果要在屏幕空间步进,则需要将线段分为(1/线段的像素长度)段,然后逐像素步进,每次步进后都需要使用该次步进深度和像素对应的深度图中比较来判断击中。在这套逻辑中,上文的公式是最重要的一环。
上文中的公式也可以根据线性插值的原理进行扩展,对于一个直线而言,插值的比例s等价于直线插值点的轴分量的总轴长的比例,有:
我们将该式子与上面的Z轴分量插值的的式子联立,也可以求出来插值点X分量的值:
这里的逻辑取材于这篇博客,但是这个化简我求不出来,一化开就太复杂了,我觉得自己是哪里出了问题,可能是我的理解,或者是我的脑子,总之我先记录在这里。


世界空间重建问题
在后处理里经常需要依仗深度来还原屏幕上一个像素的世界坐标,其本质就是NDC坐标乘以逆投影矩阵和逆相机矩阵来获得世界坐标:
float depth=tex2D(_CameraDepthTexture,i.uv);
float4 worldPos=mul(_InverseViewProjMatirx,float4(srcPos*2-1,depth*2-1,1));
worldPos.xyz/=worldPos.w;这个时候往往有一个除以W的操作,我当时死活没看懂,这里也记录一下。
我们在上文中可以看到,由于在相机空间中点在乘以投影矩阵后要符合每个轴插值公式,所以必须保证在相机空间坐标的W分量为1。而且,由于世界空间坐标变换到相机空间不会改变W分量的值,我们求出来的世界空间的w分量为1才是正确的,根据这个前提我们假设求出来的像素世界空间w分量为1为已知定值,有以下操作。
首先我们知道,NDC坐标是裁剪坐标进行了透视除法的结果:
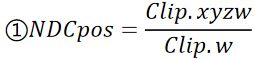
世界坐标为裁剪坐标乘以逆相机投影矩阵得来:
![]()
①②式联立可得③式,有:

对于一个点的世界空间坐标来说,其W分量即为上文式子的w分量,同时我们需要保证它为1,用这个方式可以将Clip.w表示出来:

将④与③联立,可以得出:

这个方法可以看成是如果我们不能知道坐标的裁剪w分量的一种折中方法,由于在投影空间后维度发生了变化,后处理的时候不能推估出该像素的相机空间分量,也就是裁剪空间W分量的值,转而使用这种trick来获得W分量的值。所以在使用逆矩阵倒推X的值的时候,不要忘记了除以W。
附录:重建世界空间的代码
这一段主要引用了这篇博客,写得超级详细,我本来想再认真写一遍的,但是没有找到好的切入点,为了方便以后能快速取用这些代码,我加了一些自己容易忘记的注释记录在这个地方。
使用矩阵重建
Shader "Hidden/ReBuildWorldMatrix" { Properties { _MainTex ("Texture", 2D) = "white" {} } SubShader { // No culling or depth Cull Off ZWrite Off ZTest Always Pass { CGPROGRAM #pragma vertex vert #pragma fragment frag #include "UnityCG.cginc" sampler2D _MainTex; sampler2D _CameraDepthTexture; float4x4 _InverseViewProjMatirx; struct appdata { float4 vertex : POSITION; float2 uv : TEXCOORD0; }; struct v2f { float2 uv : TEXCOORD0; float4 vertex : SV_POSITION; }; float4 getWorldSpacePosition1(float2 srcPos, float depth) { float4 worldPos=mul(_InverseViewProjMatirx,float4(srcPos*2-1,depth*2-1,1)); //这里由于深度值是采样得到的裁剪空间深度,所以映射到[-1,1]是必须的 worldPos.xyz/=worldPos.w; return worldPos; } v2f vert (appdata v) { v2f o; o.vertex = UnityObjectToClipPos(v.vertex); o.uv = v.uv; return o; } fixed4 frag (v2f i) : SV_Target { float depth=tex2D(_CameraDepthTexture,i.uv); #if defined(UNITY_REVERSED_Z) depth = 1 - depth; #endif float3 worldPos=getWorldSpacePosition1(i.uv,depth).xyz; return fixed4(worldPos,1); } ENDCG } } }C#代码有:
Matrix4x4 getMatrix = myCamera.projectionMatrix * myCamera.worldToCameraMatrix; ReBuildWorldMatrixMaterial.SetMatrix("_InverseViewProjMatirx", getMatrix.inverse); Graphics.Blit(src,dst,ReBuildWorldMatrixMaterial);这里有两点需要注意:
- 不要忘记可能存在Reverse_Z的定义,在采样深度图之后可以做一下判断。
- depth如果不进行反向映射的话可能会影响值的正确性。
同时还存在利用宏SAMPLE_DEPTH_TEXTURE的写法,可以这么写:
Shader "Hidden/ReBuildWorldMatrix" { Properties { _MainTex ("Texture", 2D) = "white" {} } SubShader { // No culling or depth Cull Off ZWrite Off ZTest Always Pass { CGPROGRAM #pragma vertex vert #pragma fragment frag #include "UnityCG.cginc" sampler2D _MainTex; float4 _MainTex_TexelSize; sampler2D _CameraDepthTexture; float4x4 _InverseProjectorMatrix; float4x4 _InverseViewMatirx; struct appdata { float4 vertex : POSITION; float2 uv : TEXCOORD0; }; struct v2f { float2 uv : TEXCOORD0; float4 vertex : SV_POSITION; }; float4 getWorldSpacePosition(float2 srcPos, float depth) { float4 viewPos=mul(_InverseProjectorMatrix,float4(srcPos*2-1,depth,1)); viewPos.xyz/=viewPos.w; //观察空间转入世界空间 float4 worldPos=mul(_InverseViewMatirx,float4(viewPos.xyz,1)); return worldPos; } v2f vert (appdata v) { v2f o; o.vertex = UnityObjectToClipPos(v.vertex); o.uv = v.uv; return o; } fixed4 frag (v2f i) : SV_Target { float depth=SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture,i.uv); float3 worldPos=getWorldSpacePosition(i.uv,depth).xyz; return fixed4(worldPos,1); } ENDCG } } }同时在外部传入:
Matrix4x4 projectionMatrix = GL.GetGPUProjectionMatrix(Camera.current.projectionMatrix, false); ReBuildWorldMatrixMaterial.SetMatrix("_InverseProjectorMatrix", projectionMatrix.inverse); ReBuildWorldMatrixMaterial.SetMatrix("_InverseViewMatirx",Camera.current.worldToCameraMatrix.inverse);同时要注意SAMPLE_DEPTH_TEXTURE和UNITY_SAMPLE_DEPTH的区别,UNITY_SAMPLE_DEPTH即为tex2D与LinearEyeDepth函数的组合拳,而SAMPLE_DEPTH_TEXTURE为tex2D的多平台宏,内部操作与tex2D一致。
使用视锥体重建
视锥体重建的本质是在Shader外使用相机参数推估出相机视锥体的四个顶点方向,在Shader中,对屏幕坐标判定其靠近哪个视锥体顶点向量就等于哪个向量的值。通过片元着色器对其插值后得到具体每个像素的世界空间向量,然后再手动从原点出发沿着该方向前进视角空间线性深度来获得具体的世界空间值。
Shader "Custom/ReBuildWorld" { Properties { _MainTex("Texture",2D)="whtie"{} } CGINCLUDE #include "UnityCG.cginc" sampler2D _CameraDepthTexture; float4x4 _ViewPointMatrix; struct VertexToFragment { float4 pos:SV_POSITION; float2 uv:TEXCOORD0; float4 rayDir:TEXCOORD1; //float3 worldPositin:TEXCOORD2; }; VertexToFragment vertexFunc(appdata_base v) { VertexToFragment VToF; VToF.pos=UnityObjectToClipPos(v.vertex); VToF.uv=v.texcoord.xy; //VToF.worldPositin=mul(unity_ObjectToWorld,v.vertex); //需要认识到的是,在后处理中是只有摄像机空间及其以后的坐标的 //所以,当在后处理shader中输出世界空间或者模型空间参数都只能在屏幕上输出2维顺滑的颜色而不是根据坐标而变化的颜色值 //按照矩阵的数据,有如下规则: //0左上 1右上 2:左下 3:右下 int index=0; if(VToF.uv.x<0.5&&VToF.uv.y>0.5) { //左上 index=0; } else if(VToF.uv.x>0.5&&VToF.uv.y>0.5) { //右上 index=1; } else if(VToF.uv.x<0.5&&VToF.uv.y<0.5) { //左下 index=2; } else if(VToF.uv.x>0.5&&VToF.uv.y<0.5) { //右下 index=3; } //这里有个细节需要注意,由于这是应用于后处理的代码,在采样时, //其参照的纹理坐标可以视为屏幕坐标,而不是某个具体纹理的坐标, //所以我们可以根据其值的大小判断其处于屏幕的哪个范围之中 VToF.rayDir=_ViewPointMatrix[index]; //获得世界空间下摄像机到像素的向量 return VToF; } fixed4 FragmentFunc(VertexToFragment VToF):SV_TARGET { float depthTexture=tex2D(_CameraDepthTexture,VToF.uv); float depthValue=LinearEyeDepth(depthTexture); float3 worldPos=_WorldSpaceCameraPos+depthValue*normalize(VToF.rayDir.xyz); //这里是很典型的,点的位置=射线源+射线长度*射线方向 return float4(worldPos,1); } ENDCG SubShader { pass { ZTest Always Cull Off ZWrite Off CGPROGRAM #pragma vertex vertexFunc #pragma fragment FragmentFunc ENDCG } } }在C#代码中手动算出相机原点视锥体四个角的向量:
Matrix4x4 getCameraFrustum() { Matrix4x4 viewPoint = Matrix4x4.identity; float aspect = myCamera.aspect; //相机纵横比 float far = myCamera.farClipPlane; //相机与远裁剪平面的距离 Vector3 right = myCamera.transform.right; //相机的本地坐标的右边 Vector3 up = myCamera.transform.up; //相机本地向上坐标 Vector3 forward = myCamera.transform.forward; //相机本地前向坐标 float height = Mathf.Tan(myCamera.fieldOfView * 0.5f * Mathf.Rad2Deg); //算出开角的半值的tan结果(注意这里进行了一次弧度与角度的转换) Vector3 ToRight = right * far * height * aspect; //注意涉及侧面的时候要注意纵横比的问题,因为我们理论是算的垂直的纵向向量,在转成横向的时候要计算纵横比 //注意,这里实际上计算的还是纵向的Y轴的长度,因为我们乘以了视锥体纵横比才使得它变成了X轴长度 Vector3 ToUp = up * far * height; //摄像机到远裁剪平面Y轴的偏移向量 Vector3 ToForward = forward * far; //设定摄像机到远裁剪平面的Z轴距离 //构建与暗裁剪平面四个角的坐标 Vector3 TL = ToForward - ToRight + ToUp; //左上角点的坐标 Vector3 TR = ToForward + ToRight + ToUp; //右上角点的坐标 Vector3 BL = ToForward - ToRight - ToUp; //左下角点的坐标 Vector3 BR = ToForward + ToRight - ToUp; //右下角点的坐标 viewPoint.SetRow(0, TL); viewPoint.SetRow(1, TR); viewPoint.SetRow(2, BL); viewPoint.SetRow(3, BR); return viewPoint; } void OnRenderImage(RenderTexture src, RenderTexture dst) { Matrix4x4 getViewPoint_WorldSpace = getCameraFrustum(); ReBuildWorldProjectionMaterial.SetMatrix("_ViewPointMatrix", getViewPoint_WorldSpace); Graphics.Blit(src, dst, ReBuildWorldProjectionMaterial); }