论文解读《基于伪标签自训练的局部对比损失半监督医学图像分割》
论文解读《Local contrastive loss with pseudo-label based self-training for semi-supervised medical image segmentation》
代码: 代码链接
论文:论文地址
摘要:
一、 半监督/自监督学习利用未标记的数据和有限的标签来解决这一限制。
最近的自监督学习方法使用对比损失从无标记的图像中学习良好的全局层次表示,并在流行的自然图像数据集(如ImageNet)上实现高性能的分类任务。在像素级的预测任务中,如分割,学习良好的局部表示和全局表示是至关重要的。
然而,现有的基于局部对比损失的方法对学习良好的局部表示的影响仍然有限,因为相似和不同的局部区域是基于随机增量和空间邻近性定义的;由于在半/自监督设置中缺乏大规模的专家标注,所以没有基于局部区域的语义标签。
二、
(1) 局部对比损失( local contrastive loss)
(2)通过利用从伪标签和有限的标签图像中获得的语义标签信息
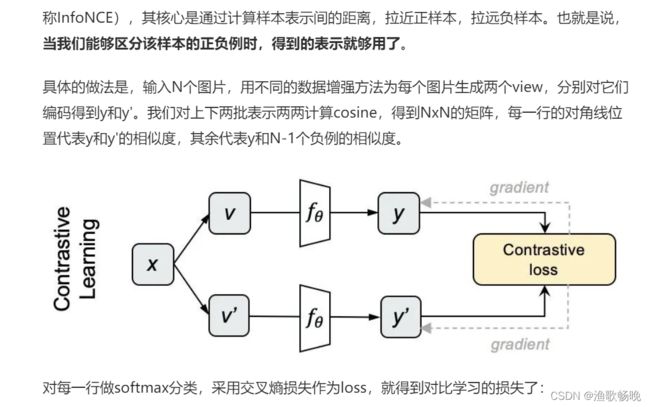
局部对比损失:全局对比度损失会激励同类的图像表征靠近,不同类的图片表征远离。对于需要图像级别表示的下游任务(例如对象分类),此策略很有用。 但涉及像素级预测(例如图像分割)的下游任务可能另外需要独特的局部表征来区分相邻区域。
于是,提出了解码器提取有局部表征,让同一张图片不同位置的表征不一致(局部表征有区别),同类型的图片局部表征一致。
这种损失函数可以很好的表达成对样本的匹配程度,也能够很好用于训练提取特征的模型。
Contrastive Methods(对比式方法) 这类方法则是通过将数据分别与正例样本和负例样本在特征空间进行对比,来学习样本的特征表示。
三、
(3)伪标签的自训练( pseudo-label based self-training)
(4)优化有标签集和无标签集
(jointly optimizing the proposed contrastive loss on both labeled and unlabeled sets) 上的 对比损失( contrastive loss)
(5) 有标签集上的 分割损失(segmentation loss) 来训练网络。
自训练: 自我训练就是通过一系列的步骤,用已有的有标签的数据(labelled data),去对剩下的还未标记的数据打标签。从而使得训练数据(training data)更多。
对比度损失: 主要是用在降维中,即本来相似的样本,在经过降维(特征提取)后,在特征空间中,两个样本仍旧相似;而原本不相似的样本,在经过降维后,在特征空间中,两个样本仍旧不相似。
这种损失函数可以很好的表达成对样本的匹配程度,也能够很好用于训练提取特征的模型。
(6) 在心脏和前列腺的三个公共医学数据集上评估,并获得高分割性能。
一、
1.1 介绍: 在医学成像中,获取如此大的标记数据集用于分割是费时且昂贵的,因为标注需要由临床专家完成。为了减少对大型标记数据集的需求。
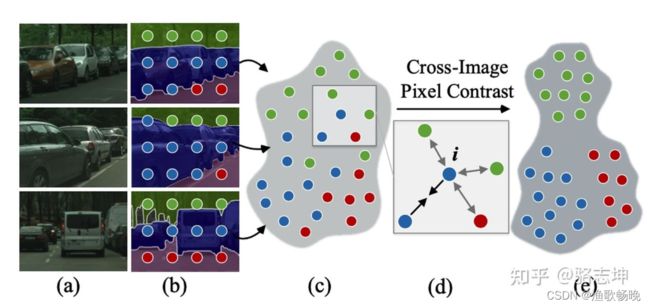
语义分割: 算法的本质是通过深度神经网络将图像像素映射到一个高度非线性的特征空间。
现有算法大多只关注于 局部上下文信息(单个图像内、像素之间的位置和语义依赖性),
忽略了训练数据集的全局上下文信息(跨图像的、像素之间的语义相关性)。
1) 强判别 能力:在该特征空间中,每个像素的特征应具有较强的分类能力(strong categorization ability of individual pixel embeddings);
2) 高度结构化:同类像素的特征应高度紧致(intra-class compactness),不同类像素的特征尽量分散(inter-class dispersion)
1.2 目的:
(1) 在半监督学习方法方面,突出的工作是在使用有限的标记示例的同时,从无标记示例中提取有用的信息。一些流行的半监督学习策略包括使用伪标签自训练、熵最小化、一致性正则化和数据增强。
(2) 基于对比学习的方法在许多自然和医学图像数据集上产生了用于分类和分割任务的高精度模型。对比学习的目标是相似图像的潜在表征应该是相似的,同时它们也应该与不同图像的潜在表征不同。优化过程中 ,正确定义相似和不相似图像是获得更好表征的关键。
(3) 良好的局部图像特征的无监督学习可以像全局特征一样至关重要。
没有语义标签的情况下很难定义相似/不相似的局部区域,因此局部对比学习方法的性能相对于全局方法来说相当有限。
(4) 端到端的训练框架实现分割( end-to-end joint training framework),在该框架中,设计使用未标记数据的伪标签,而不是来自无监督方法的替代标签(surrogate labels),并实现高分割精度。
1.3 贡献:
(1) 端到端半监督方法,无标记数据集和有限标记集伪标记的对比损失。
提出的对比损失促使了属于同一目标的像素的相似表示语义标签,并让它们与来自不同类的像素的表示不同。无标签集的标签是由伪标签估计赋值的,伪标签估计是通过一个初始网络训练的有限数量的标签图像。
伪标签在训练期间迭代更新。使用局部对比损失来训练网络。
(2) 之前基于标签的对比损失进行预训练(pre-training with label-based contrastive loss),然后使用分割损失进行微调,这两个步骤都是全监督。
(3) 定义的局部损失目标在分割任务所需的数据集 上增强目标语义类的类内相似性和类间可分性,而之前的无监督局部对比损失方法只能在图像中实现这一点。
(4) 与最先进的自监督和半监督进行比较。结果表明,该方法实现了最佳性能。
二、方法:
2.1 类内亲和和类间可分性。
(1) 本工作的目标是通过利用语义标签信息来学习具有类内亲和和类间可分性
(discriminative pixellevel representations with intra-class affinity and inter-class separability)。
(2)
XL定义标签集,用(XL, yl)定义它的图像标签对。
XU为对(XU, yˆu)的集合。
整个数据集被定义为X = XL∪XU。
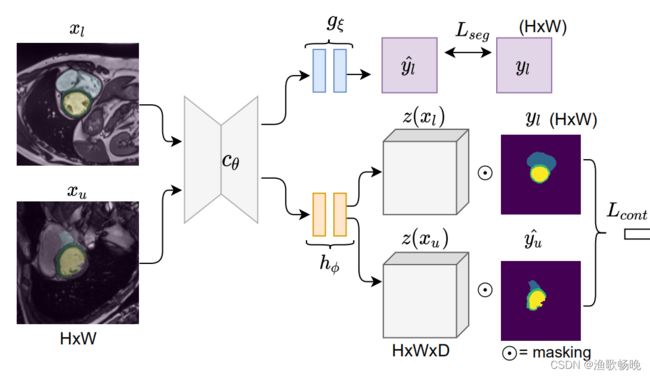
1) cθ是编码器-解码器主干网络:
2) gξ是分割的小网络,
3) hφ是对比损失训练的小网络。

本文提出的半监督分割算法包括两个优化步骤:
1) 有限的标记集XL来最小化分割损失Lseg,从而训练网络 cθ和gξ
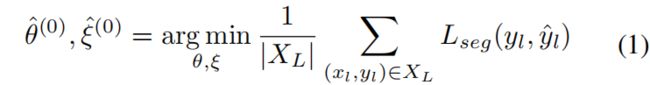
在优化的第二步中,X = XL∪XU,监督分割损失 Lseg和 局部对比损失 Lcont对网络cθ、gξ和hφ进行联合训练。

Lcont–局部对比损失。
在特征空间中通过利用整个数据集的对比损失,同时使用标记集的标准标签和未标记集的伪标签估计来实现更好的分类分离。
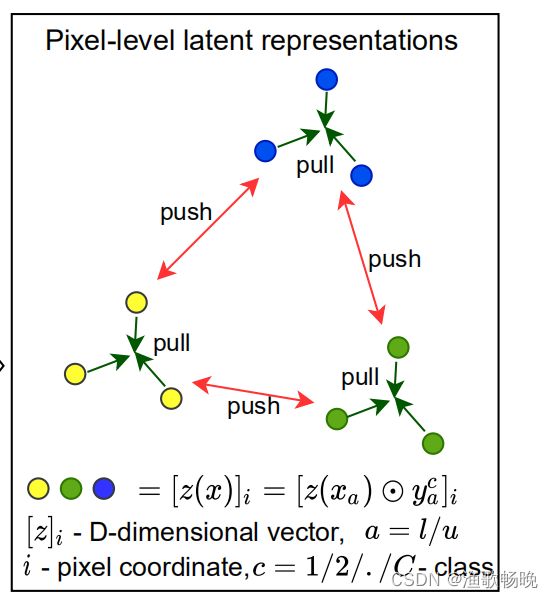
图像x 经过 公共网络(cθ)和对比分支(Hφ) 后的特征图表示为 z(x) = hφ(cθ(x)),其维数为H X W X D,其中H, W与输入图像维数相同,D为通道数。表示属于图像x的前景类c的像素坐标集为Sc(x)。
三、实验
3.1 数据集
(a) ACDC数据集:包含100个用1.5T和3T扫描仪获取的短轴MR-cine T1 3D心脏解剖体积。专家标注提供了三种结构:右心室、心肌和左心室。它是2017年MICCAI ACDC挑战赛的一部分。
(b)前列腺数据集:包含48个前列腺t2加权MRI 3D体积。给出了前列腺外周区和中心腺体两种结构的专家注释。它在2019年MICCAI医学十项全能挑战赛中举办。
© MMWHS数据集:包含20个T1 MRI 3D心脏解剖体积,专家标注了7个结构:左心室、左心房、心肌、升主动脉、肺动脉、右心室和右心房。它在STACOM和MICCAI 2017挑战赛中举办。
3.2 预处理
使用ITK工具包中的N4偏差校正对所有图像进行偏差校正。在此之后,我们对所有数据集应用以下预处理步骤:(i)每个3D体(x)使用min-max归一化:(xx1)/(x99 9x1)其中x1和x99表示x中的第1百分位和第99百分位。(ii)接下来,我们分别使用双线性和最近邻插值将所有2D图像及其对应的标签重新采样到固定的平面内分辨率rf中。这之后是裁剪或零填充到一个固定的图像尺寸df。该决议(rf)和图像尺寸(df)数据集是:(一)交直流:射频= 1.367×1.367平方毫米和df = 192×192,和(b)前列腺癌:射频= 0.6×0.6平方毫米和df = 192×192,和© MMWHS:射频= 1.5×1.5平方毫米和df = 160×160。
3.3 网络结构
(1) UNet的体系结构,cθ表示的通用编码器和解码器
(2) 在解码器的最后一层,两个网络:分割网络(gξ),对比学习(hφ)
编码器由6个卷积块组成,每个块由两个3个3的卷积和一个2个2的最大池层组成,步幅为2。
解码器由5个卷积块组成,每个块由一个因子为2的上采样层组成,通过跳跃连接从编码器的相应层连接,然后是两个3X3卷积。
分割任务网络(gξ)由三个3X3卷积组成,后面是一个softmax层输出分割掩码,用于dice loss。
对比任务网络(hφ)由两个1X1卷积层组成,输出维数为H X W X D的特征映射 f,用于局部对比损耗计算。
分割任务和对比损失计算除最后一层外,其余各层均有批量归一化层和ReLU激活层。
3.4 评价
利用**Dice相似系数(DSC)**评价分割性能。对于所有的实验,我们报告了在测试集|Xts|中,在6次不同的运行中,在没有背景的情况下,所有结构的平均DSC。对于每次运行,我们通过从可用的数据集中随机抽样来构造不同的XL和Xval集。
四、结果分析
在表一中,展示了基线的结果、文献中已有的半监督方法、本文提出的方法和并行对比学习的结果。

4.1 基线和半监督方法对比
从表1中,与基线相比,对于所有数据集,半监督方法的性能有显著提升。
4.2 方法介绍
(1) 自训练方法(self-training methods)在分割损失中使用伪标签相比,
(2) 对比度损失( contrastive loss) 中使用伪标签效果更好。
在有限标签情况下,最初的伪标签估计是错误的,如果用于分割损失优化,则性能会恶化。
假设仅在对比损失时使用伪标签,而不在分割损失时使用伪标签作为正则化,防止错误的伪标签掩码信息传播到分割任务特定层中。
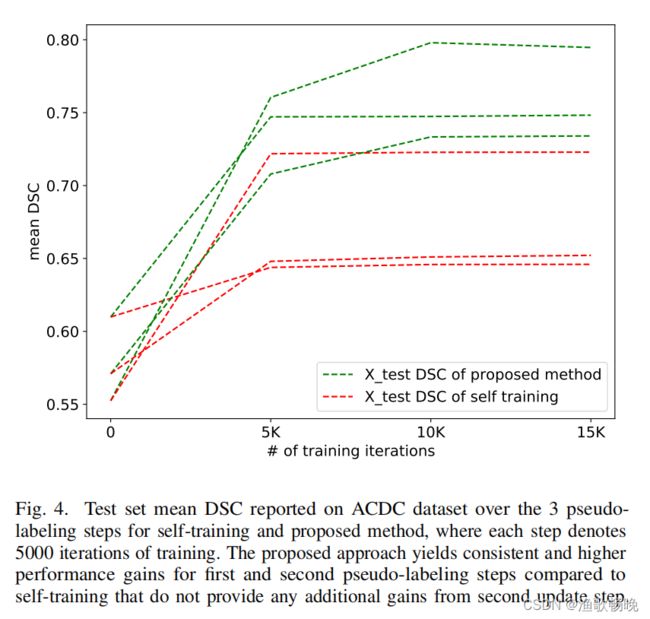
重新估计伪标签,改进训练结果,如图4所示。

(图4) 测试集是指自训练和所提出方法的3个伪标记步骤在ACDC数据集上所报告的DSC(Dice’s similarity coefficient——Dice相似系数),每一步表示训练的5000次迭代。与自我训练相比,所提出的方法在第一个和第二个伪标记步骤中获得一致和更高的性能收益,而第二个更新步骤不提供任何额外的收益。
4.3 可视化的结果提出的方法
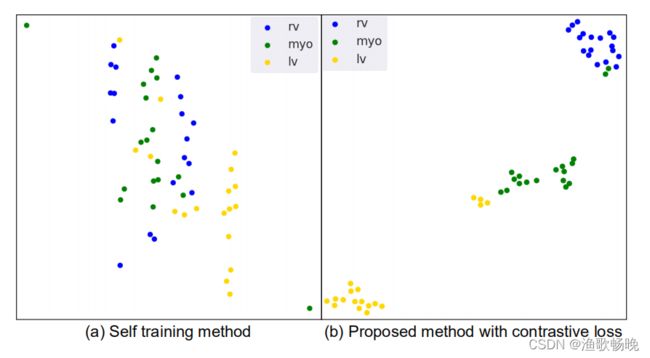
图3 对一些随机采样的未标记图像(右心室(rv)、心肌(myo)、左心室(lv)三种结构的ACDC(右心室(rv)、心肌(myo)、左心室(lv))图进行了分析:
(a)自训练(self-training)
(b)提出的带有局部对比损失的方法。
DSC(Dice’s similarity coefficient——Dice相似系数)
dice loss来自 dice coefficient,是一种用于评估两个样本的相似性的度量函数,取
值范围在0到1之间,取值越大表示越相似。
五 结论
在医学图像分割中,基于深度学习的高性能模型具有很大的挑战性,因为需要大量的注释。
使用许多未标记的图像和有限的标签来产生高分割图像。
联合训练框架,其中像素级的对比损失定义在无标签图像的伪标签和有标签的图像上(pixel-wise contrastive loss is defined over pseudo-labels of unlabeled images and limited labeled images),
传统的分割损失( segmentation loss) 仅应用在有标签的集合上。
(1)基于分割损失的方法(如自我训练)相比,通过提出的对比损失( contrastive loss),得到了更好的分割类的 内部紧凑性和类间可分性(intra-class compactness and inter-class separability)。
(2) 在三个MRI数据集上对所提出的方法进行了广泛的评估,有限的标注下获得了较高的分割性能。与目前最先进的半监督学习方法和并行对比学习方法相比,获得了更高的性能增益 (SOTA)。
(3) 在分割损失中只使用标记集(the labeled set)。