深度学习03-CNN 应用
说明:本系列是七月算法深度学习课程的学习笔记
文章目录
- 1 概述
- 2 图片识别+定位
- 3 物体监测
-
- 3.1 选择性搜索
- 3.2 R-CNN
- 3.3 Fast R-CNN
- 3.4 Faster R-CNN
- 4 语义分割
-
- 4.1 滑窗处理
- 4.2全卷积神经网络
- 5 代码
1 概述
CNN主要任务包含物体识别+定位、物体识别、图像分割。
图片识别:图片分类,假设图片中是一个主要对象。
图片识别+定位:可以用矩形框,画出图片中的物体。
物体识别:实际情况中一个图片是包含多个对象的。用矩形框标出所有物体。
图像分割:在物体识别的基础上,检测出物体边缘。
2 图片识别+定位
图片识别:输入:图片;输出:类别标签;评价标准:准确率
图片定位:输入:图片;输出:物体边界框(x,y,w,h);评价标准:交并准则
(x,y)是左上角的点,w是宽度,h是高度
交并准则:两个矩形交的面积/两个矩形并的面积,值需要>=0.5才可以用
图片识别是分类问题,使用交叉熵损失。
图片定位是回归类问题,使用 L2 distance (欧氏距离)损失函数。
图片分类问题是在知名模型上fine-tune。

在知名模型的尾部,可以接在全连接层之后,也可以接在全连接层之前。分类问题加一个分类头,定义一个交叉熵损失函数;回归类问题接一个回归头,定义一个欧式距离损失函数。
思路1:看做回归问题
能否对物体做进一步定位?
例如定位猫的2只眼睛,2只耳朵,1个鼻子。上一个问题中是一个物体,有4个数字。现在的问题有5个物体,那就会有20个数字。预估一个长度为20的向量。这里的前提是:物体的结构是相同的。遇到只有一只猫的眼睛就出错了。
进一步可以识别人的姿势。类似火柴拼成的人。每个关键是一个坐标,做一个回归。论文:Toshev and Szegedy,“DeepPose: Human Pose Estimation via Deep Neural Networks”, CVPR 2014
思路2:图窗+识别与整合
取不同大小的框,
让框出现在不同的位置
对取得的内容做分类判定得分,
对取得的内容做回归(框)判定得分,
按照得分高低对结果框做抽取和合并。
克服问题:参数多,计算慢
1 用卷积核替换全连接层:参数可复用。
感知眼。卷积层不同位置的点相当于只能看到第一层的不同区域。
这样就不用上面方法中把不同位置的图片抠出来,送到神经网络做计算。
2 降低参数量

论文:Sermanet et al,“ntegrated Recognition,Localization and Detection using Convolutional Networks”,ICLR2014
3 物体监测
其实不知道有多个物体

在上面的步骤中有滑窗,每次滑窗,做一次类别识别,判断是否是一种动物,也可以。
问题:框的位置不同,大小不同,比例不同,导致计算量大
解决方法1:边缘策略
3.1 选择性搜索
类似于聚类,基于同样的物体像素基本相同,自下而上融合成区域。
将区域扩展为框。
论文:Uijilings et al,“Selective Search for Object Recognition”,IJCV 2013
框的选择算法如下表。

3.2 R-CNN

步骤1:输入层是图片,用候选框选择算法选择大概2000个候选框,对每个候选框缩放为同样的尺寸,作为入参,交给卷积层。

在一个知名模型上做fine-tune。根据自己的模型修改参数。例如有20个分类,再加一个背景分类,表示不属于任何类型。
步骤2:用图框候选算法选择图框,抠出图框。缩放为同样的尺寸。这一步是在CPU上计算的。
步骤3:卷积层,学习参数和特征

以上一步的图框作为输入,用CNN做前向运算,取第5个池化层做特征,将特征保存到硬盘上。
步骤4:做SVM分类
将上面的特征用SVM做分类。
步骤5:bbox regression

将上面的特征做回归,与标准答案相比。判断候选框是不是要上下左右移动。
论文:Girschick et al, “Rich feature hierarchies for accurate object detection and semantic segmentation”, CVPR 2014
3.3 Fast R-CNN
1 2000个候选框过神经网络抽取特征,花费时间多。
利用卷积层的透视眼,实现共享图窗计算,从而加速。
不再分为2000个子图,而是利用卷积层的透视眼,某一层卷积层的一个点是可以对应到原图的一部分区域的,通过共享参数的方式减少计算量。

2 做成端对端的系统

3 不同大小的图怎么接全连接层

RIP Region of Interest Pooling方式处理
如果得到的矩阵大小是500x300,但是最后想要的结果是100x100,先把图片分成很多个格子,使用max-pool做池化,变成想要的大小。
一般来说候选框不会小于目标大小。
3.4 Faster R-CNN
Region Proposal(候选图窗)一定要另外独立做吗?
候选图窗选择是在CPU上做的。

region proposal network
选择中心点为中心滑窗 3x3,1:2,2:1,1:1,按照这样的比例,选择候选图窗。
选择中心点的方法是超参数,自己选择。可以是将原始图片分为几个区块,以每个区块的中心作为中心。
论文:Ren et al, “Faster R-CNN: Towards Real-Time Object
Detection with Region Proposal Networks”, NIPS 2015
one-stage vs two-stage
faster-rnn是两段式的。第一阶段先找到候选框,第二阶段判断候选框内有没有物体以及边界情况
yolo/ssd是一段式的。把原图画成不同的格子,以格子中心点为中心,取不同比例的框,通过神经网络获得值:(dx,dy,dy,dw,confidence)以及class。前面4个是微调参数,confidence表示是否是物体,class表示是哪种物体。
4 语义分割
语义分割是对每个像素做分类。4.1 滑窗处理
参数多
4.2全卷积神经网络

CxHxW C是类别的数量
输入是 3xHxW,输出是HxW,输出每个像素的分类
HxW可能很大。
训练数据是把边框标出来。

先做下采样,再做上采样。
怎么做上采样?
专业名称transpose convolution。
例如一个2x2的区域,步长是2,那输出就是4x4,每次增加1列。

例如粉色区域=3,步长=2,pad=1,一个格子扩为9个格子。每个格子填充3a(a为系数)。

例如蓝色区域=2,系数为b,那么蓝色框线内每个单元格都为2b。两次交叉的3个方格值=3a+2b。
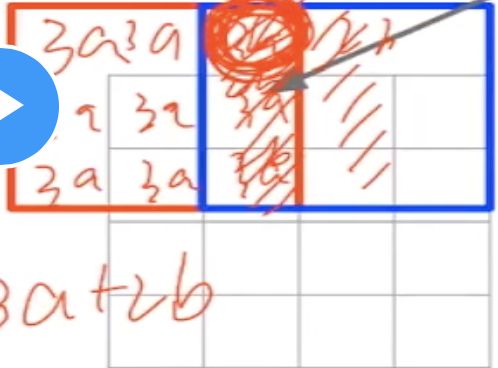
逆卷积就是这样不断还原。
5 代码
tensorFlow object detection https://github.com/tensorflow/models/tree/master/research/object_detection
可以使用TensorFlow做物体识别,从install开始。
faster-rnn https://github.com/rbgirshick/py-faster-rcnn
发现物体检测那块其实写的云里雾里,找了一篇博客写的不错,记录下来。
最后总结一下各大算法的步骤:
RCNN
1.在图像中确定约1000-2000个候选框 (使用选择性搜索Selective Search)
2.每个候选框内图像块缩放至相同大小,并输入到CNN内进行特征提取
3.对候选框中提取出的特征,使用分类器判别是否属于一个特定类
4.对于属于某一类别的候选框,用回归器进一步调整其位置
Fast R-CNN
1.在图像中确定约1000-2000个候选框 (使用选择性搜索Selective Search)
2.对整张图片输进CNN,得到feature map
3.找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层
4.对候选框中提取出的特征,使用分类器判别是否属于一个特定类
5.对于属于某一类别的候选框,用回归器进一步调整其位置
Faster R-CNN
1.对整张图片输进CNN,得到feature map
2.卷积特征输入到RPN,得到候选框的特征信息
3.对候选框中提取出的特征,使用分类器判别是否属于一个特定类
4.对于属于某一类别的候选框,用回归器进一步调整其位置
(CSDN博主「丿回到火星去」的原创文章,原文链接:https://blog.csdn.net/H_hei/article/details/87298097)