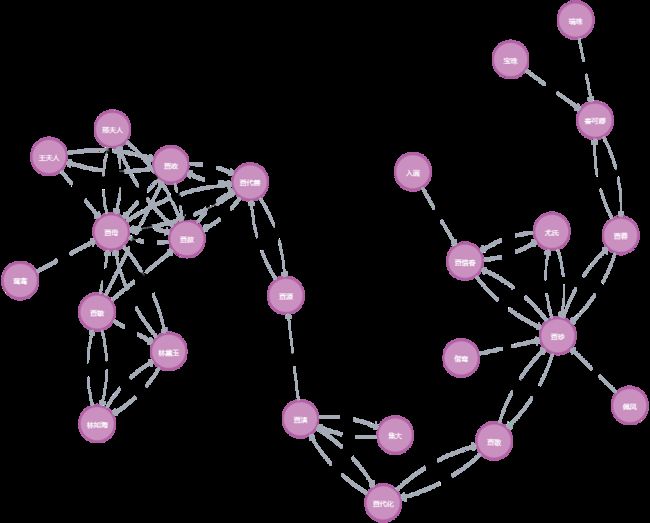
基于deepke构建红楼梦知识图谱
红楼梦,中国古典四大名著之首,清代作家创作的章回体长篇小说,又名《石头记》《金玉缘》。此书分为120回“程本”和80回“脂本”两种版本系统。新版通行本前八十回据脂本汇校,后四十回据程本汇校,署名“曹雪芹著,无名氏续,程伟元、高鹗整理”。
红楼梦中人物众多,而且人物关系复杂,常规方法梳理起来复杂而且杂乱,非常适合基于知识图谱技术构建红楼梦人物关系。
构建知识图谱,需要进行本体构建—信息抽取——知识融合。
在红楼梦中,主要需要解决人物关系。所以本体只需要人物与人物关系,其它本体暂不考虑。
信息抽取是其中难点。由于现有很多语言处理是基于现代语言进行建模的,而 红楼梦是文言文小说,所以现有语言模型可能会不太适用,所以可以使用bert语言模型,进行二次建模来处理红楼梦实体抽取,关系抽取。其中选取deepke作为框架,利用其中ner与re作为技术手段进行建模。
DeepKE包含命名实体识别、关系抽取和属性抽取三个模块,分别是三个任务。每个模块都有自己的子模块。例如,关系抽取模块中有标准的、少样本、文档级和多模态子模块。每个子模块由三部分组成:一组可用作tokenizer的工具、数据加载器、训练和预测时使用编码的一种处理模块。
实体抽取
进入对于案例使用文件夹路径,cd DeepKE/example/ner/standard,然后配置该案例运行所需要的包。根据deepke文档中的案例,创建python3.8的环境:conda create -n deepke python=3.8,然后激活conda activate deepke。安装依赖包:pip install -r requirments.txt。
第二步:获取标准的样例数据,通过wget 120.27.214.45/Data/ner/standard/data.tar.gz下载,然后tar -xzvf data.tar.gz解压,数据集和参数可以分别在data文件夹和conf文件夹中自定义。Dataset需要输入的是txt文本类型数据,文件数据格式需符合以下要求:
当下茶果已撤,贾母命两个老嬷嬷带了黛玉去见两个母舅。
OOOOOOO,B-PER I-PER O O O O O O O B-PER I-PER O O O O OO
将对应的数据放到模型训练,执行python run.py即开始训练。
关系抽取
构建样本数据示例如下
"head","tail","relation","label"
"贾代善","贾源","son","子"
"娄氏","贾源","daughter_in_law_of_grandson","重孙媳妇"
"贾母","贾代善","wife","妻"
"老姨奶奶","贾代善","concubine","妾"
"贾敏","贾代善","daughter","女"
"嫣红","贾赦","concubine","妾"
"翠云","贾赦","concubine","妾"
"娇红","贾赦","concubine","妾"
"贾迎春","贾赦","daughter","女"
"赵姨娘","贾政","concubine","妾"
"周姨娘","贾政","concubine","妾"
导入到neo4j结果如下所示