图像分类中的深度学习网络汇总
深度学习在图片处理中的应用是从图像分类开始的,所以我们要先从图像分类中了解深度学习的应用情况。
本文根据阅读大量的资料和视频资源,简单地总结了图像分类中所有经典的深度学习神经网络。
1、LeNet
LeNet神经网络由深度学习三大巨头之一的Yan LeCun在1998提出,他同事也是卷积神经网络CNN父。LeNet主要用来进行手写字符的识别与分类。虽然LeNet早在20世纪90年代就已经提出了,但由于当时缺乏大规模的训练数据,计算机硬件的性能也较低,因此LeNet神经网络在处理复杂问题时效果并不理想。
LeNet网络结构

由上面的网络结构可以看出,网络通过一个输入Input,首先经过一个卷积层;再经过一个下采样层;再是一个卷积层;再是一个下采样层,最后是两个全连接层,经过一个softmax输出。可以说LeNet5是世界上第一个CNN网络。
项目地址:https://github.com/YouthJourney/Deep-Learning-For-Image-Process/tree/master/TensorFlow_Classification
2、AlexNet
AlexNet网络是2012年ISLVRC 2012竞赛的冠军网络,分类准确率由传统的70%+提升到80%+。它是由Hinton和他的学生Alex设计的。也是至此,深度学习开始迅速发展。
AlexNet网络结构
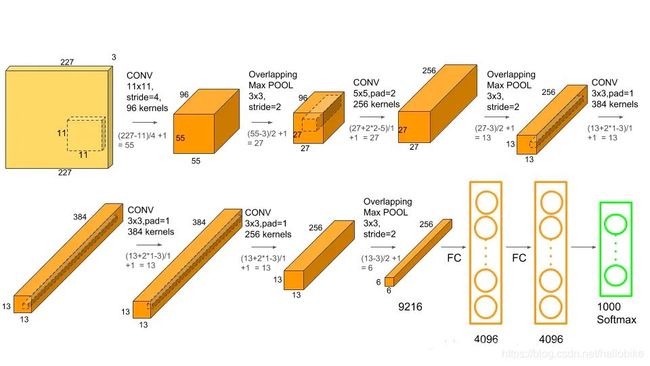
由上面的网络结构图可以清楚地看到AlexNet的整个网络结构由5个卷积层和3个全连接层组成,深度总共8层。
该网络的亮点在于:
(1)首次利用GPU进行网络加速训练。
(2)使用了ReLU激活函数,而不是传统的Sigmoid激活函数以及Tanh激活函数。
(3)使用了LRN局部响应归一化。对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
(4)在全连接层的前两层中使用了Dropout随机失活神经元操作,以减少过拟合。
项目地址:https://github.com/YouthJourney/Deep-Learning-For-Image-Process/tree/master/TensorFlow_Classification
3、VGGNet
VGG在2014年由牛津大学研究组VGG(Visual Geometry Group)提出,斩获该年ImageNet竞赛中定位任务第一名和分类任务第二名。有多种网络模型,比如VGG11、VGG13、VGG16、VGG19。
VGG16网络结构
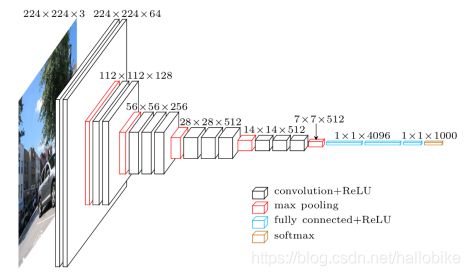
使用比较多的是VGG16网络结构,包括13个卷积层和3个全连接层。
网络中的亮点:通过堆叠多个3×3的卷积核来代替大尺度卷积核,它的原理在于感受野相同(减少所需参数,提高训练速度)。
项目地址:https://github.com/YouthJourney/Deep-Learning-For-Image-Process/tree/master/TensorFlow_Classification
4、GoogLeNet
GoogLeNet是在2014年由Google团队提出,斩获当年ImageNet竞赛中分类任务第一名。名称中的L大写是为了致敬LeNet。
GoogLeNet网络结构

通过网络结构图可以看出网络结构图使用了一系列的Inception结构,并添加了两个辅助输出器,还有局部响应归一化处理等
Inception结构
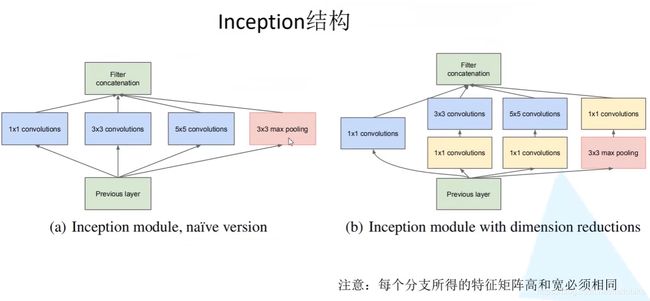
Inception结构是并行分支结构,输入特征矩阵传入Inception结构,每个分支会得到一个输出特征矩阵,再将这些特征矩阵按深度进行拼接得到一个输出特征矩阵。注意每个分支所得的特征矩阵高和宽必须相同。
网络中的亮点:
- 引入了Inception结构(便于融入不同尺度的特征信息)
- 使用1×1的卷积核进行降维以及映射处理
- 添加两个辅助分类器帮助训练
- 丢弃全连接层,使用平均池化层(大大减少模型参数量)
项目地址:https://github.com/YouthJourney/Deep-Learning-For-Image-Process/tree/master/TensorFlow_Classification
5、ResNet
ResNet在2015年由微软实验室提出,斩获当年ImageNet竞赛中分类任务第一名,目标检测第一名。获得COCO数据集中目标检测第一名,图像分割第一名。有多种网络模型,比如ResNet18,ResNet34,ResNet50,ResNet101,ResNet152。
ResNet34网络结构
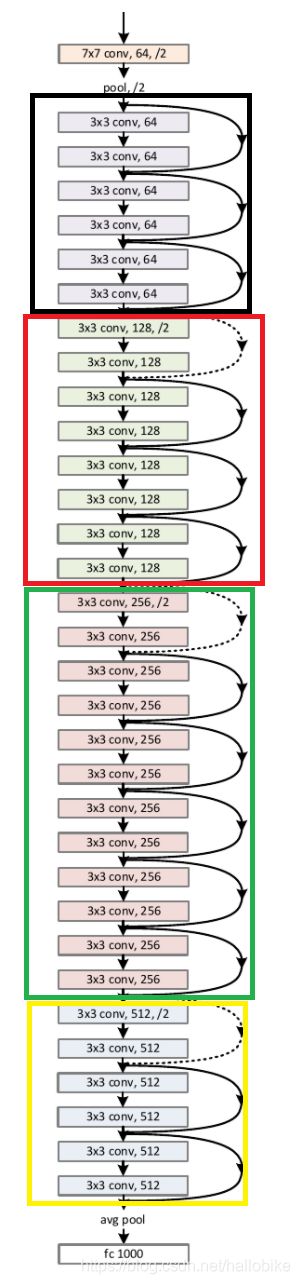
该网络由一系列残差结构组成,比如ResNet由4个残差结构组成。
网络中的亮点:
- 超深的网络结构(已经突破1000层)
- 提出Residual模块
- 使用Batch Normalization加速训练(丢弃Dropout)
残差结构
普通的网络中,如果不断增加网络层数,即使做了防止梯度消失和梯度爆炸的操作,依然会出现随着网络层数的增加得到的模型效果变差。因此引入了残差结构。

①实线残差结构,主分支输出特征矩阵和截近分支输出特征矩阵shape相同,可以相加。
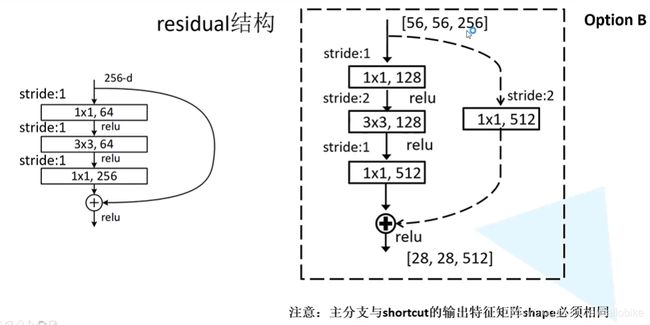
②虚线残差结构,为了使主分支输出特征矩阵与截近分支输出特征矩阵的shape相同,需要在截近分支加一个1×1的卷积对输入特征矩阵降维。
Batch Normalization
批标准化,目的是使我们的一批feature map满足均值为0,方差为1的分布规律。通过该方法可以加速网络的收敛并提升准确率。Batch Size尽可能设置大一点,设置小了话结果会很差,设置的越大求的均值和方差越接近整个训练集的均值和方差,得到的拟合结果越好。
项目地址:https://github.com/YouthJourney/Deep-Learning-For-Image-Process/tree/master/TensorFlow_Classification
6、MobileNet
MobileNet网络是由Google团队在2017年提出的,专注于移动端或者嵌入式设备中的轻量级CNN网络。相比传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量。(相比VGG16准确率减少了0.9%,但模型参数只有VGG的1/32)有三个版本:MobileNetV1、MobileNetV2、MobileNetV3。
MobileNetV1网络结构
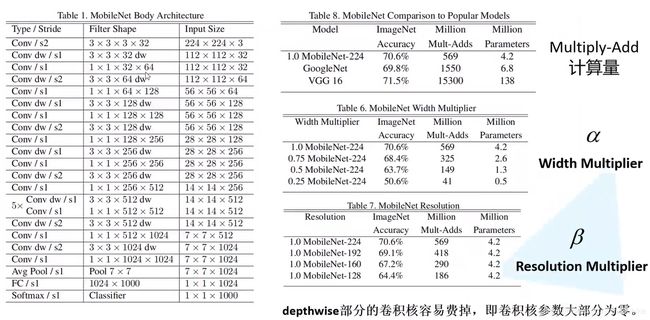
网络结构由大量DW卷积和PW卷积组成
网络中的亮点:
- Depthwise Convolution(大大减少运算量和参数数量)
- 增加超参数α、β。
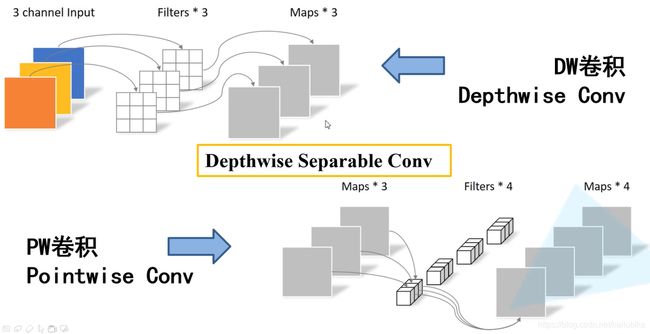
DW卷积和传统卷积的区别
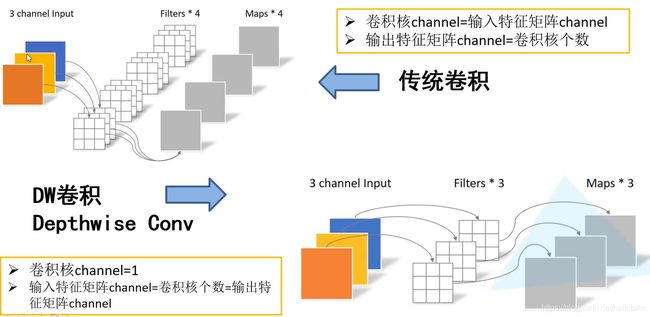
DW卷积和PW卷积的区别
MobileNet V2网络
MobileNet V2网络是由Google团队在2018年提出的,相比MobileNet V1网络,准确率更高,模型更小。
MobileNet V2网络结构
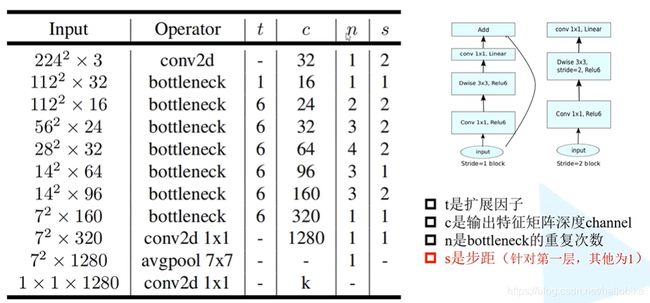
网络中的亮点:
- Inverted Residual(倒残差结构)
- Linear BottleNecks
倒残差结构与残差结构

MobileNet V3网络
MobileNet V3网络发表于2019年,V3版本结合了V1版本的深度可分离卷积、V2版本的Inverted Residual和Linear Bottleneck、SE模块(注意力机制)。利用NAS(神经结构搜索)来搜索网络的配置和参数。
MobileNet V3-Large网络结构
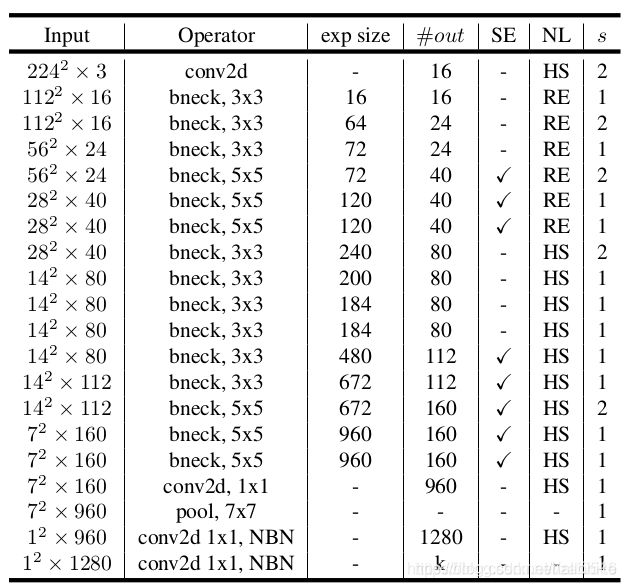
网络中的亮点:
- 更新Block(bneck)
- 使用NAS搜索参数(Neural Architecture Search)
- 重新设计耗时层结构
项目地址:https://github.com/YouthJourney/Deep-Learning-For-Image-Process/tree/master/TensorFlow_Classification
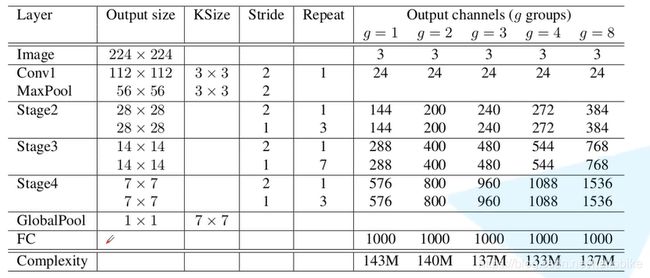
7、ShuffleNet
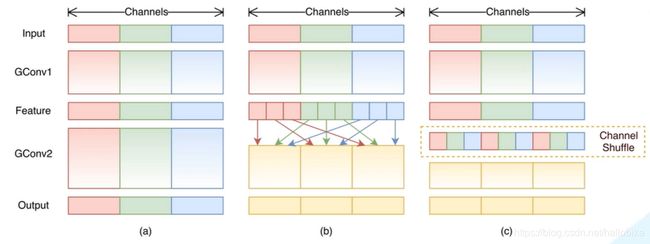
ShuffleNet网络是由旷视科技在2017年底提出的轻量级可用于移动设备的卷积神经网络。该网络的创新之处就在于使用PointWise Group Convolution还有Channel Shuffle,保证网络准确率的同时,大幅度降低了所需的计算资源。
ShuffleNet V1中的Channel Shuffle结构
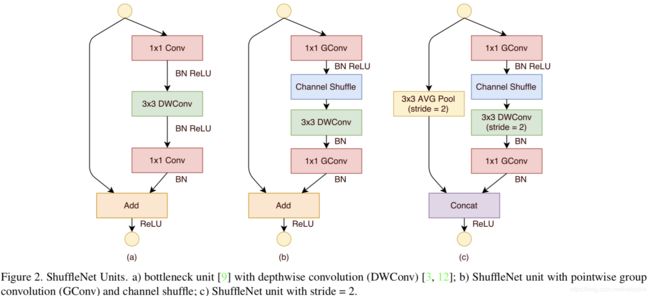
ShuffleNet V1中的Block结构
ShuffleNet V2
在ShuffleNet V2中提出了FLOPs不能作为衡量目标检测模型运行速度的标准,因为MAC(Memory access cost)也是影响模型运行速度的一大因素,论文中提出四点来说明此问题,并最终加以改进得到ShuffleNet V2的网络结构以及它的性能测试指标。
ShuffleNet V2网络结构
ShuffleNet V2中的Block结构

项目地址:https://github.com/YouthJourney/Deep-Learning-For-Image-Process/tree/master/TensorFlow_Classification
参考资料: https://space.bilibili.com/18161609/dynamic