365天深度学习训练营-第P3周:天气识别
>- ** 本文为[365天深度学习训练营](https://mp.weixin.qq.com/s/xLjALoOD8HPZcH563En8bQ) 中的学习记录博客**
>- ** 参考文章:[Pytorch实战 | 第P3周:彩色图片识别:天气识别](https://www.heywhale.com/mw/project/633567aadfae0249670d0990)**
>- ** 原作者:[K同学啊|接辅导、项目定制](https://mtyjkh.blog.csdn.net/)**
目录
一、前期准备
二、构造CNN和训练循环
三、有趣的Python小虫子bug
一、前期准备
本人Python使用的不熟练,所以本次实验其实主要还是学习Python库、torchvision的使用。
data_dir = './data/'
data_dir = pathlib.Path(data_dir)
'''
Path.glob(pattern),返回 Path 目录文件夹下所有与 pattern 匹配的文件,返回的是一个生成器类型
'''
data_paths = list(data_dir.glob('*'))
'''
PosixPath 和 WindowsPath 是 Path 的子类,分别用于操作 Unix(Mac OS X)风格的路径和 Windows 风格的路径
data_paths存放的就是三个WindowsPath类型的列表
’*‘通配符表示所有date_dir下面的文件
'''
classeNames = [str(path).split("\\")[1] for path in data_paths]
'''
split( )函数用来切割str字符串,返回一个ndarray类型的数据
split()[i] 函数用来获取str中第i个分隔符和第i+1个分隔符之间的内容,返回一个ndarray类型的数据
举例:
b="123 \n 456789 \t91011"
print(b.split("\n")[1].split('\t')[0])
#Out:[' 456789 ']
a= "123 \n456 \n789"
print(a.split())
#Out:['123', '456', '789']
classeNames = [str(path).split("\\") for path in data_paths]
#OUT [['data', 'cifar-10-batches-py'], ['data', 'cifar-10-python.tar.gz'], ['data', 'MNIST']]
classeNames = [str(path) for path in data_paths]
#OUT ['data\\cifar-10-batches-py', 'data\\cifar-10-python.tar.gz', 'data\\MNIST']
将data_paths下的每个WindowsPath子类转为为str类型
'''
#print(classeNames)data_dir = pathlib.Path(data_dir) data_paths = list(data_dir.glob('*')) ''' PosixPath 和 WindowsPath 是 Path 的子类,分别用于操作 Unix(Mac OS X)风格的路径和 Windows 风格的路径 data_paths存放的就是三个WindowsPath类型的列表 ’*‘通配符表示所有date_dir下面的文件 '''pathlib是Python中的一个文件包,主要用来处理文件夹
'''
split( )函数用来切割str字符串,返回一个ndarray类型的数据
split()[i] 函数用来获取str中第i个分隔符和第i+1个分隔符之间的内容,返回一个ndarray类型的数据
举例:
b="123 \n 456789 \t91011"
print(b.split("\n")[1].split('\t')[0])
#Out:[' 456789 ']
a= "123 \n456 \n789"
print(a.split())
#Out:['123', '456', '789']
classeNames = [str(path).split("\\") for path in data_paths]
#OUT [['data', 'cifar-10-batches-py'], ['data', 'cifar-10-python.tar.gz'], ['data', 'MNIST']]
classeNames = [str(path) for path in data_paths]
#OUT ['data\\cifar-10-batches-py', 'data\\cifar-10-python.tar.gz', 'data\\MNIST']
将data_paths下的每个WindowsPath子类转为为str类型
'''
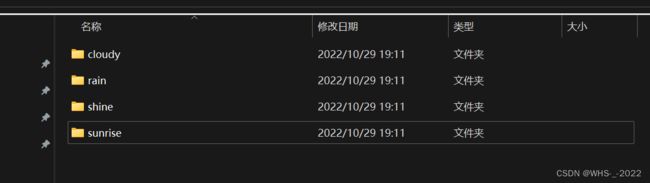
下一步是准备数据集,存在电脑中的文件格式如上图所示,我们可以用ImageFolder数据集来加载
# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
'''
torchvision主要是用于常见的一些图形变换,transforms.Compose是其中的一个接口函数
'''
total_data = datasets.ImageFolder(total_datadir,transform=train_transforms)
'''
A generic data loader where the images are arranged in this way by default:
root/dog/xxx.png
root/dog/xxy.png
root/dog/[...]/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/[...]/asd932_.png
既其默认你的数据集已经自觉按照要分配的类型分成了不同的文件夹,一种类型的文件夹下面只存放一种类型的图片
Dataset ImageFolder
Number of datapoints: 1125
Root location: ./data/
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=None)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
'''二、构造CNN和训练循环
rain_size = int(0.8 * len(total_data))
'''
total_data是ImageFolder类 Number of datapoints:1125
'''
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
# train_dataset, test_dataset
# train_size,test_size
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
import torch.nn.functional as F
class Network_bn(nn.Module):
def __init__(self):
super(Network_bn, self).__init__()
"""
nn.Conv2d()函数:
第一个参数(in_channels)是输入的channel数量
第二个参数(out_channels)是输出的channel数量
第三个参数(kernel_size)是卷积核大小
第四个参数(stride)是步长,默认为1
第五个参数(padding)是填充大小,默认为0
"""
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2,2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn5 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24*50*50, len(classeNames))
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool(x)
x = F.relu(self.bn4(self.conv4(x)))
x = F.relu(self.bn5(self.conv5(x)))
x = self.pool(x)
x = x.view(-1, 24*50*50)
x = self.fc1(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
#print("Using {} device".format(device))
model = Network_bn().to(device)
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-4 # 学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)
#训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小,一共60000张图片
num_batches = len(dataloader) # 批次数目,1875(60000/32)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小,一共10000张图片
num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
def main():
# for X, y in test_dl:
# print("Shape of X [N, C, H, W]: ", X.shape)
# print("Shape of y: ", y.shape, y.dtype)
# break
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))
print('Done')
warnings.filterwarnings("ignore") # 忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
if __name__ == '__main__':
main()
最终的训练结果

三、有趣的Python小虫子bug
在编写代码时,我出现了一个问题
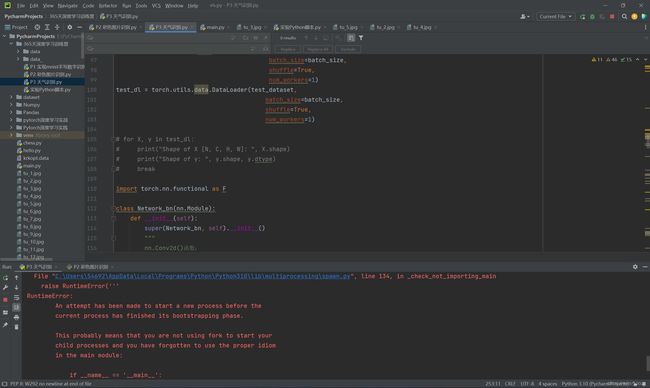
RuntimeError:
An attempt has been made to start a new process before the current process has finished its bootstrapping phase
然后我找到一篇文章可以解决这个问题,但是根本的原因因为我不了解Python语法所以没办法解决。如下是文章链接
RuntimeError: An attempt has been made to start a new process before the current process has finished its bootstrapping phase. - 晓风残月龙 - 博客园
或者将num_workers=0也可以解决问题
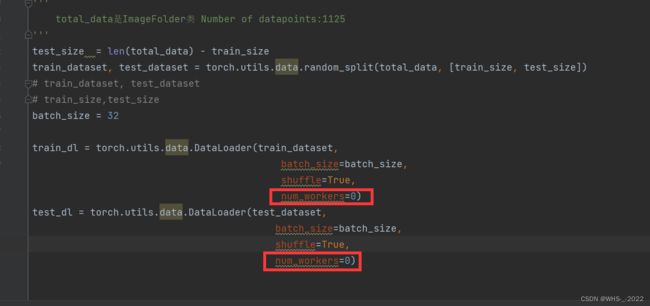
学习到的小技巧,shift+tab整体左移