VPGNet—用于车道线和道路标志检测和识别的消失点引导网络
用于车道线和道路标志检测和识别的消失点引导网络(VPGNet: Vanishing Point Guided Network for Lane and Road Marking Detection and Recognition)
前言:
这是ICCV 2017的一篇文章。通过消失点(vanishing point)去辅助处理车道线和道路标志的检测和识别。针对自动驾驶中雨天和黑夜的研究现状(截至2017年,并无公开的基准数据集),该文构建了带有消失点标记的4种场景数据集(no rain, rain, heavy rain, and night),17类车道线和道路标志,共20000余张图片。该文提出一种多任务的端到端网络,且该网络能够检测到未被明确看到的车道,且能够达到20fps的速度。
网络模型和数据集见:https://github.com/SeokjuLee/VPGNet(使用caffe框架)
效果见:https://www.youtube.com/watch?v=jnewRlt6UbI
图1展示了本文检测效果。

思路来源:
研究表明,驾驶员注视方向与道路方向高度相关,因此几何背景在车道定位中很重要。本文想要以类似人类的方式识别全局环境,利用一个消失点预测任务来嵌入几何上下文信息到所提出的网络。
数据集:
表1、表2分别展示了数据集的场景和类别信息。
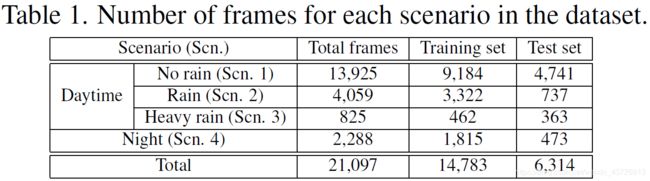

消失点标注:【EASY:一个清晰的场景(如笔直的道路);HARD:混乱的场景(如交通堵塞);NONE:消失点不存在的地方(如十字路口)】。直线和曲线车道都被用来预测消失点
**道路标志:**Other markings:南韩所特有的道路标志,或者无法被区分为一个特定的类别。
基于深度学习的通用目标检测方法(例R-CNN)对通用图片检测效果较好,但对于车道线检测效果不佳(因为车道线是小物体)。
单目相机采集数据。相机在车内,偶尔会拍到雨刷器的照片。
如果采用像素级标注,经过卷积和池化后,标注信息可能消失,因此该文将像素级注释投影到网格级掩码上(图像被划分为一个8×8的网格,网格单元将对应填充一个与原始标注图中同样的类标签)。消失点也同样被标注。***(将标注信息变得更粗了)***
图2展示了数据集中的标注信息的一个例子。
神经网络
本文提出一个数据层来诱导网格级注释,使得能够同时训练车道和道路标志。
框回归任务适用于斑点形状的物体(交通标志或车辆),但车道和道路标志不能用一个单独的边界框来表示。因此本文提出利用网格级掩码来替代回归(网格上的点回归到最近的网格单元,并由多标签分类任务组合来表示对象)。由此能够整合具有不同的特征和形状的车道和道路标志两个独立的目标。
对于后处理,lane类仅使用多标签任务的输出,road marking类同时使用网格框回归和多标签任务,消失点检测任务在训练车道和道路标志模式时推断一个全局几何上下文信息。
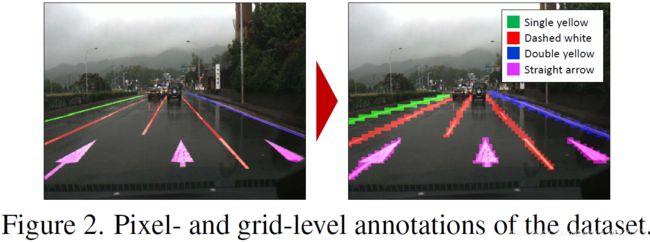
表3和图3展示了网络结构。

(grid box:车道线;object mask:道路标志边界框;multi-label:17类样本;VPP:消失点)
多任务学习,该网络可对车道和道路标志进行检测和分类,同时预测消失区域。
消失点预测(Vanishing Point Prediction Task,VPP)
人类可以从全局信息(如附近的道路结构或交通流量),直观地预测车道的位置。
**消失点:**平行的车道线在远处交汇的点。(本文定义:从图形的角度来看,是三维空间中的平行线收敛到二维平面上的一点;)。消失点可以用于提供场景的全局几何上下文,这对于推断车道和道路标记的位置很重要。我们将VPP模块与多任务网络相结合,训练车道线收敛到一点。
”使用softmax分类器对网络的空间输出进行矢量化,以预测VP的确切位置“方法不可行:在整个网络的输出空间向量化后,只选择其中一个点会导致定位不精确。
怎么去准确定位VP点?
- 利用回归损失(例L1,L2, hinge losses)直接计算从VP到像素的距离:难平衡与其他任务(目标检测/多标签分类)的损失。行不通。
- 采用交叉熵损失来平衡从每个检测任务传播的梯度:应用一种二值分类方法,直接分类背景和前景(即消失的区域,见图4a。(二进制掩码是在数据层通过绘制一个以我们标注的VP为中心的固定大小的圆来生成的)。背景和前景像素数量不平衡造成网络可能将每个像素推断为背景类,这样VPP便无法学习场景全局语义信息,容易过拟合。行不通。
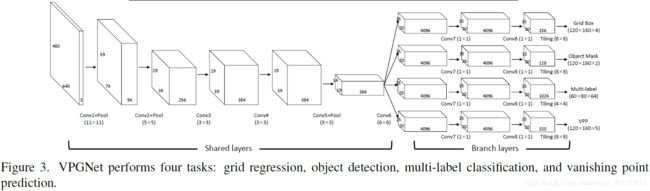
- **本文方法:为了有效地反映车道位置的全局信息,需要考虑整个场景。我们使用象限掩码(quadrant mask)**将整个图像分成四个部分。这四个部分的交点是VP。因此,本文为VPP任务的输出定义了五个通道:一个absence通道和四个quadrant通道。输出图像中的每个像素都选择属于五个通道中的一个。absence通道用于表示一个不是VP的像素;quadrant通道则代表图像上的一个象限部分。例如,如果VP存在于图像中,那么每个像素都应该被分配到四个quadrant通道之一,而absence通道则不能被选择。具体来说,第三个quadrant通道是道路场景的右上对角边缘,第四个quadrant通道是道路场景的左上对角边缘。(这里不是很懂)另一方面,如果VP很难被识别(例如,交叉道路,遮挡),每个像素都将被归类为absence通道。在这种情况下,absence信道的平均置信度将会很高。
图4b是这些方法的对比。本文方法丰富了包含场景全局结构的梯度信息。
训练
网络由四部分组成,各自涵盖不同的语义信息。
检测任务识别对象并涵盖局部上下文信息。VPP任务涵盖全局上下文信息。网络要分两个阶段来训练。(如果同时训练这些任务,网络会受到某一主导任务的高度影响)
- 阶段一:只训练VPP任务。(其他任务学习率置为0)。网络学习图像的全局上下文信息,在VP检测任务达到收敛时停止。(虽然只训练VPP任务,但由于相互共享层的权值更新,其他检测任务的loss也减少了20%左右。这说明车道和路标检测与VPP任务在特征表示层中具有一些共同的特征。)
- 阶段二:使用第一阶段训练好的网络来训练所有的任务。注意要平衡好各个任务之间的loss,不然会受到其他任务的影响。总损失如式(1)所示:
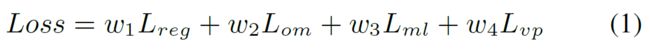
Lreg:网格回归L1损失;Lom、Lml、Lvp:是其他各个分支的交叉熵损失。
w1-w4:是四个损失的权重。
- 一开始置为1
- 其次,设置这些初始损失值的倒数为损失权值
在训练过程中,如果损失之间的尺度差异变大,则重复这个过程来平衡损失值。
当验证精度收敛时,第二阶段停止。
后处理
为了让网络输出的结果更加适合于应用。
(这一部分也不是很懂。。。)
车道线
- 点采样:首先,我们从多标签任务中车道通道概率高的区域中抽取局部峰值。采样点是成为车道段的潜在候选点。然后,通过逆透视映射(IPM)[3]将选定的点投影到鸟瞰视图。IPM用于分离VP附近的采样点。这不仅适用于直线道路,也适用于弯曲道路。
- 聚类:通过改进的基于密度的聚类方法对这些点进行聚类。按像素距离顺序决定聚类。
- lane回归:根据垂直索引对点进行排序后,如果现有的容器顶部有一个闭合点,则将该点堆叠在容器中。否则,我们将为新的集群创建一个新的bin。通过这样做,我们可以减少聚类的时间复杂度。最后,利用VP的位置对得到的聚类进行二次回归。如果每个车道簇的最远样本点离副点很近,则将其纳入簇中,估计出一个多项式模型。这使得车道结果在VP点位置附近稳定。类类型分配给网络的多标记输出的每个线段。
道路标志
- 网格采样:从对每个类的多标签输出具有较高的置信度的网格回归任务中提取网格单元。
- 边框聚类:选择每个网格的角点,迭代地将它们与附近的网格单元合并。如果没有其他相邻网格单元属于同一类,则合并终止。一些道路标记(如人行横道或安全区域)很难用一个边界框来定义,对这类标志则通过网格抽样进行本地化,而不进行合并。
消失点
VP是四个象限的交点,该点使得来自每个象限通道的四个置信度变得很接近。式(2)(3)描述了各象限的边界交点:
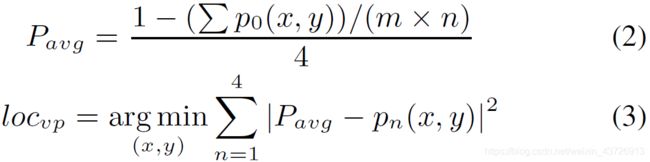
Pavg:VP存在于图像中的概率
Pn(x,y):(x,y)在第n个通道的置信度(n=0,absence通道)
mxn:置信度图的尺寸
LOCvp:VP点的位置
结果
实验设置
数据集如表1所示。
**数据增强:**翻转。一是增加了图片数量,二是可以防止了来自车道位置的位置偏差(数据集是在一个右侧驾驶的国家获得的,通过翻转数据集,我们可以模拟左侧驾驶的环境)。
网络经过第一阶段的VPP训练后得到了初始化,在第二个训练则四个任务同时训练。momentum=0.9;mini-batch=20;SGD。(由于多个任务必须按比例收敛,我们调整每个任务的学习速度。)
按照任务划分训练了三种网络模型:
- **2-Task网络:**包括回归任务和二元分类任务
- **3-Task网络:**包括2-Task和一个多标签分类任务
- **4-Task网络:**包括3-Task和一个VPP任务,即VPGNet。
NVIDIA GTX Titan X;单次向前传递大约需要30毫秒,后处理大约需要20毫秒或更少;20fps。
多任务学习分析
均衡了每一层激活的强度尺度。
评价指标
**车道线检测:**由于基准测试的ground truth是用网格单元来标注的,所以计算每个单元的中心到每个单元的采样车道点的最小距离。如果最小距离在边界R内,将这些采样点标记为true positive,并检测相应的网格单元。通过测量车道上的每个网格单元,可以严格地评价车道段的位置。此外,测量F1-score进行比较。
**道路标志识别:**采用了缓和评估测量方法。由于在开车时所需要的唯一信息是面前的道路标记,而不是道路标记的确切边界,所以测量预测blobs的精度。具体来说,计算所有与地面真值网格cells重叠的预测cells。重叠的cells标记为 true positive cells。如果 true positive cells数大于聚集斑点上所有预测cells数的一半,则定义覆盖的ground truth目标为检测到。此外,我们还测量了recall score以作比较。
**消失点预测:**测量地面真值点和预测VP之间的欧氏距离。通过改变阈值距离R和ground truth VP来评估recall score
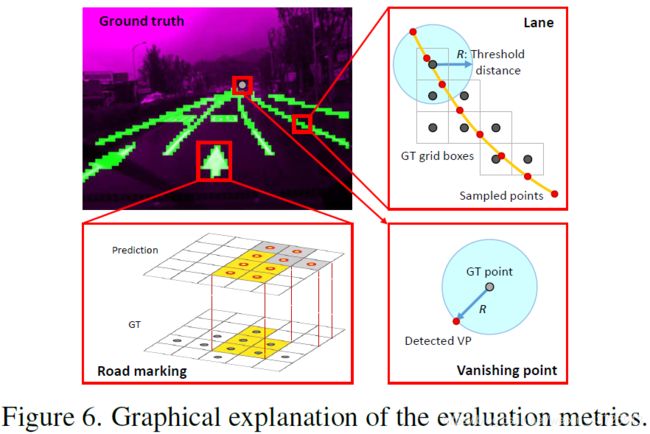
车道线检测和识别
设置R等于车道厚度的一半平均值(20像素)。由于透视效果,镜头前的双车道约为70 - 80像素,而VP点附近只有8个像素(单个网格大小)
在Caltech Lanes数据集上效果对比:由于该数据集包含白天相对容易的场景,所以2-Task、3-Task和4-Task网络的整体性能非常相似。
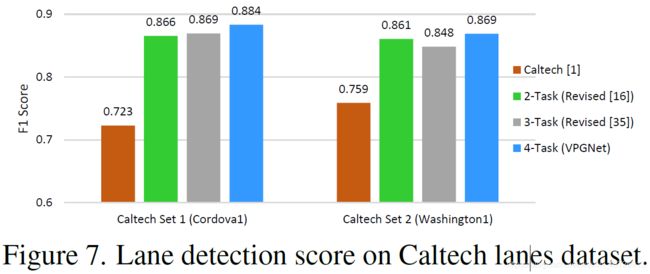
VPGNet的正向传递时间为30ms,而FCN-8s[24]的正向传递时间为130ms。
与像素级标注相比,FCN-8s在网格级标注方案中表现出了更好的性能。这证明了网格级标注更适合于车道的检测和识别。(因为网格级标注会从薄标注区域(如车道或道路标记)周围的边缘信息产生更强的梯度,这反过来又会丰富训练并导致更好的性能。)

VP不存在时(如交叉道路或遮挡)效果:表4显示了实验结果,表明在没有VP的情况下,通过VPP任务增强的特征表示有助于找到车道。(多任务学习的一个优势)

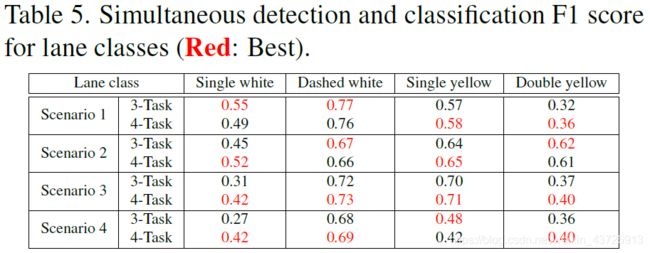
为了同时检测和分类车道类,由于类别不平衡,我们用实例数较多的前四个车道类来度量F1-socre。所选的类是:单白线、虚线、单黄线和双黄线。任务3和任务4网络的性能如表5所示。除“无雨、白天条件”外,对单线白线的识别能力得到了很大提高。这表明,在雨夜条件下使用VPP任务可以改善用单白线的车道边界的激活。
(但我感觉对其他类型车道线的效果一般,尤其对单黄线,F1-score明显降低。可能是因为VP的标注也用黄色引起的?)
道路标志检测和识别
由于类别不平衡,同样选择四类道路标志进行评估。结果如表6所示。
除“无雨,白天状态”的停止线类外,评价结果均有较大提高。这可能因为停止线有水平边,而这些边与VPP任务不密切相关。其他路标的形状从几何角度给VP指明方向。因此,对这些类的反应变得高度活跃。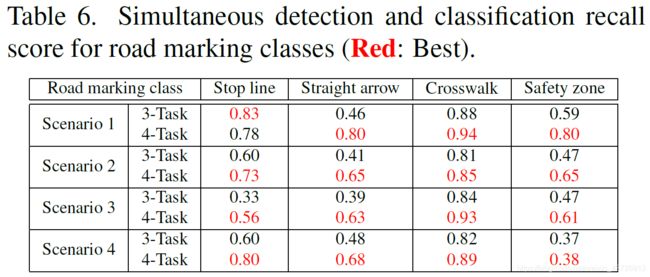
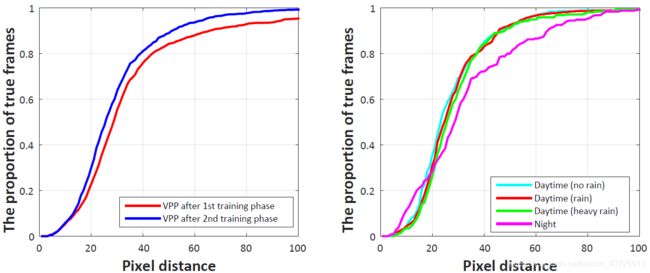
消失点预测
只比较vpp网络和4-Task网络。图9为实验结果。如左图所示,第二阶段后的预测得到了很大的提高,这意味着VPP任务对车道和路标检测任务的帮助。
结论
VPP任务通过增强车道和道路标记以及道路边界的激活来增强车道和道路标记的检测和分类。