关于深度学习的网络流量分类论文整理(一)
Paper:Malware Traffic Classification Using Convolutional Neural Network for Representation Learning
论文:使用卷积神经网络进行表示学习的恶意软件流量分类
论文下载:https://ieeexplore.ieee.org/document/7899588
代码下载:https://github.com/echowei/DeepTraffic
数据处理工具包使用方法:https://github.com/yungshenglu/USTC-TK2016
作者博士毕业论文收录于知网:基于深度学习的网络流量分类及异常检测方法研究
目录
- 一、介绍
- 二、数据集
- 三、数据预处理
- 四、模型结构
- 五、扩展性研究
- 六、实验结果及分析
一、介绍
如图一,流量分类方法主要有四种:基于端口号、基于深度包检测(DPI)、基于统计特征、基于行为特征。其中基于端口号和基于DPI方法是基于规则的方法,通过匹配预定义的硬编码规则来进行流量分类,而基于统计特征和基于行为特征的方法是经典机器学习的方法。这篇文章研究的则是机器学习中的表示学习。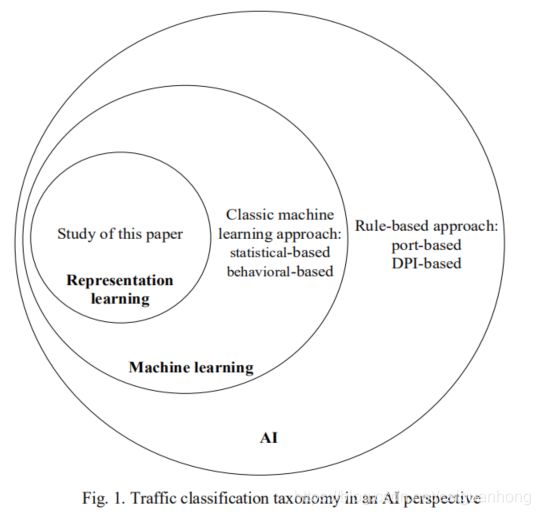
图二介绍了不同方法的工作流程,相比于传统方法需要手工设计特征,这篇文章使用的是表示学习方法中的深度学习,可以自动提取特征,使用的是卷积神经网络。

二、数据集
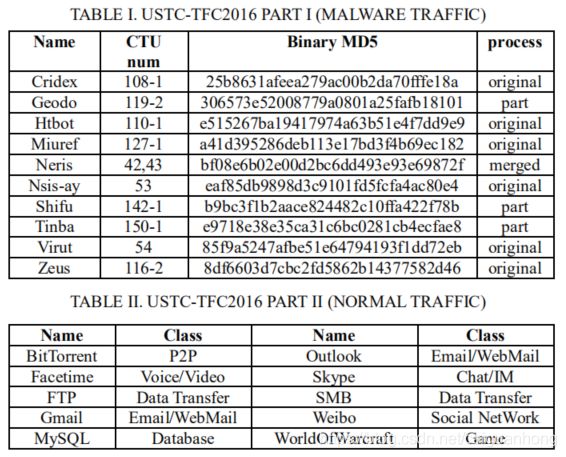
作者参考文献【16】和【17】制作了一个数据集USTC-TFC2016,分为恶意流量和正常流量,一共有10种流量包含8类应用,如下表1和表2。
接下来介绍了数据包的拆分和组合。
一个flow(流)包含5元组:源IP、源端口号、目的IP、目的端口号和传输协议,一个session(会话)就是双向的flow。

原始traffic由一些flow或session构成,而flow或session又由x、b、t分别为五元组、包的大小和开始传输的时间构成。

这里还提到每个flow或session只使用前784个字节,因为CNN输入的数据大小必须统一,而他们的长度可能会不一样,至于为何选取784字节,文中也给出了解释。因为流或会话的前面部分一般是建立连接的数据和一部分内容数据,更能反映流量特征,而之后部分更多的是数据,不能很好地体现流量类型特征。

三、数据预处理
从协议角度来说,可以选取部分某几层的数据,一般有两种分法:只选取应用层的数据(TCP/IP的应用层即OSI的第七层),选取全部数据。这样选的依据是应用层会包含大部分流量的信息,另外底层的信息也会对流量的分类起到一定作用。另外还会将流量依据方向分为两种:session和flow。所以就有4种流量表示方法:Flow+All,Flow + L7, Session + All, Session + L7。
数据预处理部分分为四步:traffic split, traffic clean, image generation, IDX conversion
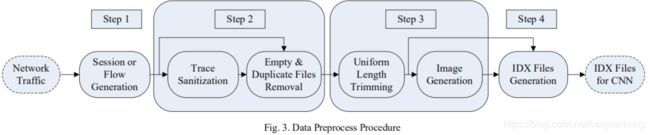
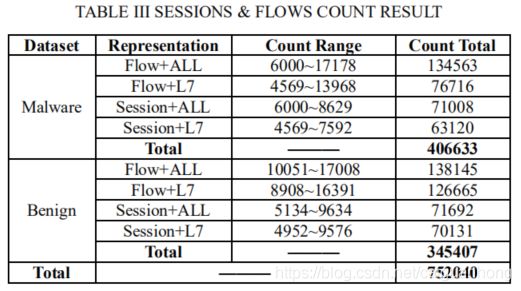
使用数据预处理工具USTC-TK2016对数据集USTC-TFC2016进行处理后,如下表,共产生752040条记录。
在预处理环节的image conversion,对数据进行了可视化,结果如下图,可以看到不同的数据流有明显的区分度,同一种数据流有高度相似的图片表示。

四、模型结构
因为模型的输入数据大小为784(28x28),和用于MNIST手写数字识别的网络LetNet-5的输入数据大小(32x32)差不多,因此使用的网络和LetNet-5类似。有2个卷积层,2个池化层,2个全连接层,文中也给出了具体的网络模型参数。


五、扩展性研究
使用了三种分类器:2分类、10分类、20分类,对流量好坏和类型进行分类,如图6。

六、实验结果及分析
使用accuracy (A), precision ( P ), recall ( R ), f1 value (F1)对模型优劣进行评估。
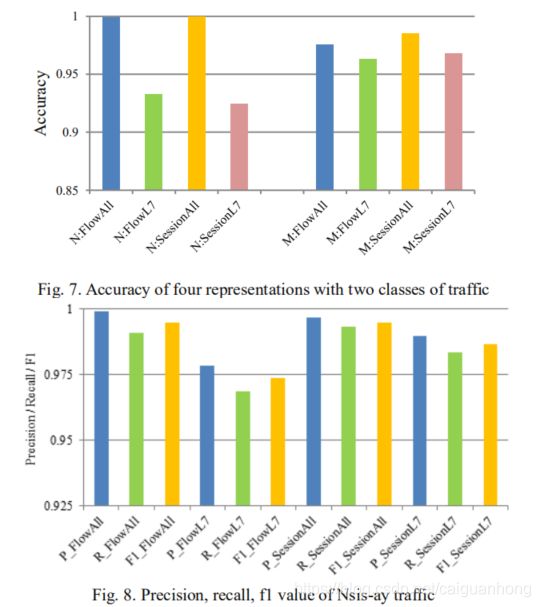
结论:session表现优于flow,all layer优于只有应用层
参考:
- 流量分类方法设计(一)——参考论文整理