打通图像增强tensorflow版Unet_v2代码
目录
数据path结构
代码调试
构建数据生成器对象
Augmentation函数
doAugmentate函数
splitMerge函数
保存到.npy模型文件
完整代码
data.py
unet.py
实验结果
基础v1版:打通tensorflow版Unet_v1代码_WRStop的博客-CSDN博客
代码来源&参考,改动都是在此基础上改动:U-net:运行你的第一个U-net进行图像分割_decouples的博客-CSDN博客
数据path结构
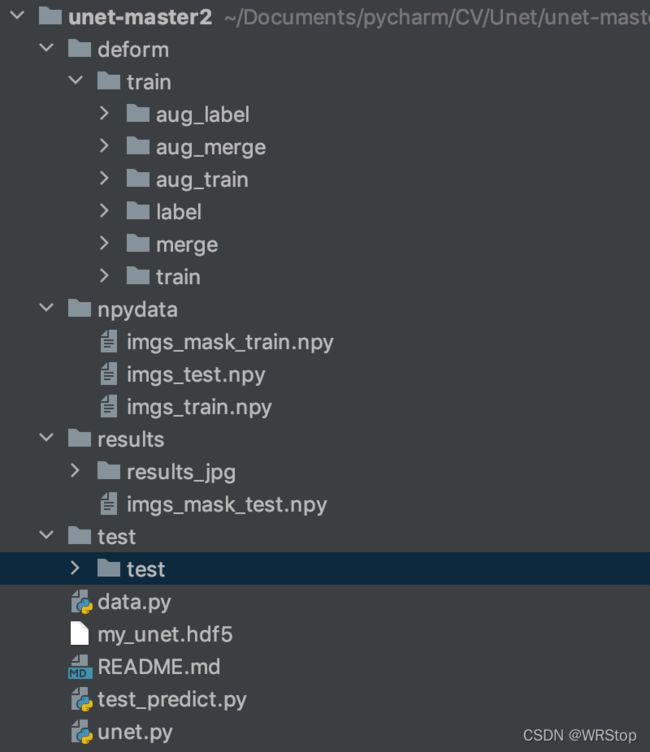
代码调试
只更改了data.py,增加图像增强
构建数据生成器对象
# 数据生成器对象
self.datagen = ImageDataGenerator(
rotation_range=0.2, # 随机旋转度数
width_shift_range=0.05, # 随机水平平移
height_shift_range=0.05, # 随机竖直平移
shear_range=0.05, # 随机错切变换
zoom_range=0.05, # 随机放大
horizontal_flip=True, # 水平翻转
fill_mode='nearest') # 填充方式Augmentation函数
合并train与label图片,save到merge路径下
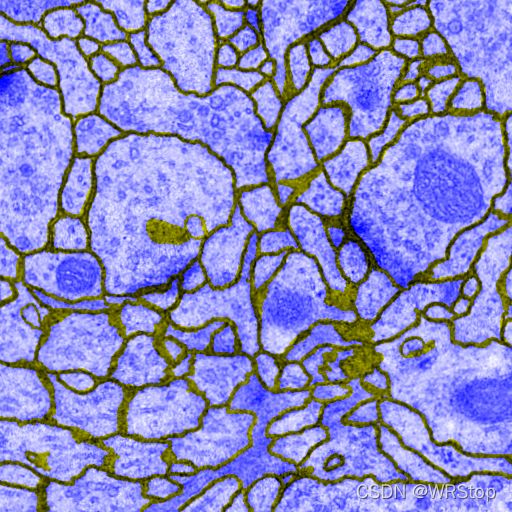
(0.tif)
doAugmentate函数
增强一张图片,其中imgnum为一张图片增强后的结果图片有几张,保存到aug_merge中
(这里的图片是Augmentation函数后的merge图片,所以也是对merge图片进行增强,输出的结果图片也是merge的)
以下都以增强两次即imgnum=2为例


0_0_3144.tif 0_0_5058.tif
splitMerge函数
将aug_merge中增强过的merge图片分开为aug_train与aug_label

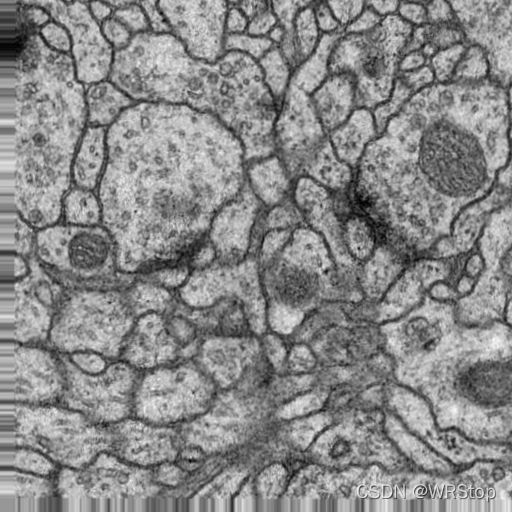
0_0_3144_train.tif 0_0_5058_train.tif


0_0_3144_label.tif 0_0_5058_label.tif
保存到.npy模型文件
与v1版的文件路径、文件名和加载方式有较大区别,
文件路径:aug_train和aug_label下分0-29文件夹分别存储增强后的图像
create_train_data中
imgs = glob.glob(self.data_path+"/*/*."+self.img_type) # 添加/*
imgs.sort(key=lambda x: int(x.split('/')[4][:-10])) #3,-4更改为4,-10文件名:从单纯的0.tif变成0_0_3144_label.tif,所以在匹配上花了些时间
create_train_data中
for imgname in imgs:
midname = imgname[23:imgname.rindex("_")] #[imgname.rindex("/")+1:]更改为[23:32]
img = load_img(self.data_path + "/" + midname + "_train.tif",grayscale = True)
label = load_img(self.label_path + "/" + midname + "_label.tif",grayscale = True)
img = img_to_array(img)
label = img_to_array(label)
imgdatas[i] = img
imglabels[i] = label
if i % 100 == 0:
print('Done: {0}/{1} train'.format(i, len(imgs)))
i += 1完整代码
data.py
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
import numpy as np
import os
import glob
import cv2
#from libtiff import TIFF
class myAugmentation(object):
"""
一个用于图像增强的类:
首先:分别读取训练的图片和标签,然后将图片和标签合并用于下一个阶段使用
然后:使用Keras的预处理来增强图像
最后:将增强后的图片分解开,分为训练图片和训练标签
"""
def __init__(self, train_path="deform/train/train", label_path="deform/train/label", merge_path="deform/train/merge", aug_merge_path="deform/train/aug_merge", aug_train_path="deform/train/aug_train", aug_label_path="deform/train/aug_label", img_type="tif"):
"""
使用glob从路径中得到所有的“.img_type”文件,初始化类:__init__()
"""
self.train_imgs = glob.glob(train_path+"/*."+img_type)
self.train_imgs.sort(key=lambda x: int(x.split('/')[3][:-4]))
self.label_imgs = glob.glob(label_path+"/*."+img_type)
self.label_imgs.sort(key=lambda x: int(x.split('/')[3][:-4]))
self.train_path = train_path
self.label_path = label_path
self.merge_path = merge_path
self.img_type = img_type
self.aug_merge_path = aug_merge_path
self.aug_train_path = aug_train_path
self.aug_label_path = aug_label_path
self.slices = len(self.train_imgs)
# 数据生成器对象
self.datagen = ImageDataGenerator(
rotation_range=0.2, # 随机旋转度数
width_shift_range=0.05, # 随机水平平移
height_shift_range=0.05, # 随机竖直平移
shear_range=0.05, # 随机错切变换
zoom_range=0.05, # 随机放大
horizontal_flip=True, # 水平翻转
fill_mode='nearest') # 填充方式
def Augmentation(self):
"""
Start augmentation.....
"""
trains = self.train_imgs
labels = self.label_imgs
path_train = self.train_path
path_label = self.label_path
path_merge = self.merge_path
imgtype = self.img_type
path_aug_merge = self.aug_merge_path
if len(trains) != len(labels) or len(trains) == 0 or len(trains) == 0:
print ("trains can't match labels")
return 0
for i in range(len(trains)):
# keras.preprocessing中load_img + img_to_array 形成numpy数组;与cv2.imread()效果相同
img_t = load_img(path_train+"/"+str(i)+"."+imgtype)
img_l = load_img(path_label+"/"+str(i)+"."+imgtype)
x_t = img_to_array(img_t)
x_l = img_to_array(img_l)
x_t[:,:,2] = x_l[:,:,0]
img_tmp = array_to_img(x_t)
# 合并train与label,save到merge路径下
img_tmp.save(path_merge+"/"+str(i)+"."+imgtype)
img = x_t
img = img.reshape((1,) + img.shape)
# 建立aug_merge下的0-29路径
savedir = path_aug_merge + "/" + str(i)
if not os.path.lexists(savedir):
os.mkdir(savedir)
self.doAugmentate(img, savedir, str(i))
def doAugmentate(self, img, save_to_dir, save_prefix, batch_size=1, save_format='tif', imgnum=2):
# 增强一张图片的方法
"""
augmentate one image
"""
datagen = self.datagen
i = 0
for batch in datagen.flow(img,
batch_size=batch_size,
save_to_dir=save_to_dir,
save_prefix=save_prefix,
save_format=save_format):
i += 1
# 原代码中>改成==
if i == imgnum:
break
def splitMerge(self):
# 将合在一起的图片分开
"""
split merged image apart
"""
path_merge = self.aug_merge_path
path_train = self.aug_train_path
path_label = self.aug_label_path
for i in range(self.slices):
path = path_merge + "/" + str(i)
train_imgs = glob.glob(path+"/*."+self.img_type)
savedir = path_train + "/" + str(i)
if not os.path.lexists(savedir):
os.mkdir(savedir)
savedir = path_label + "/" + str(i)
if not os.path.lexists(savedir):
os.mkdir(savedir)
for imgname in train_imgs:
midname = imgname[imgname.rindex("/")+1:imgname.rindex("."+self.img_type)]
img = cv2.imread(imgname)
img_train = img[:,:,2] #cv2 read image rgb->bgr
img_label = img[:,:,0]
cv2.imwrite(path_train+"/"+str(i)+"/"+midname+"_train"+"."+self.img_type,img_train)
cv2.imwrite(path_label+"/"+str(i)+"/"+midname+"_label"+"."+self.img_type,img_label)
def splitTransform(self):
# 拆分透视变换后的图像
"""
split perspective transform train
"""
#path_merge = "transform"
#path_train = "transform/data/"
#path_label = "transform/label/"
path_merge = "deform/deform_norm2"
path_train = "deform/train/"
path_label = "deform/label/"
train_imgs = glob.glob(path_merge+"/*."+self.img_type)
for imgname in train_imgs:
midname = imgname[imgname.rindex("/")+1:imgname.rindex("."+self.img_type)]
img = cv2.imread(imgname)
img_train = img[:,:,2]#cv2 read image rgb->bgr
img_label = img[:,:,0]
cv2.imwrite(path_train+midname+"."+self.img_type,img_train)
cv2.imwrite(path_label+midname+"."+self.img_type,img_label)
print("after splitTransform")
class dataProcess(object):
def __init__(self, out_rows, out_cols, data_path = "deform/train/aug_train", label_path = "deform/train/aug_label", test_path = "test/test", npy_path = "npydata", img_type = "tif"):
# 数据处理类,初始化
self.out_rows = out_rows
self.out_cols = out_cols
self.data_path = data_path
self.label_path = label_path
self.img_type = img_type
self.test_path = test_path
self.npy_path = npy_path
# 创建训练数据
def create_train_data(self):
i = 0
print('-'*30)
print('Creating training train...')
print('-'*30)
imgs = glob.glob(self.data_path+"/*/*."+self.img_type) # 添加/*
imgs.sort(key=lambda x: int(x.split('/')[4][:-10])) #3,-4更改为4,-10
print(len(imgs))
imgdatas = np.ndarray((len(imgs),self.out_rows,self.out_cols,1), dtype=np.uint8)
imglabels = np.ndarray((len(imgs),self.out_rows,self.out_cols,1), dtype=np.uint8)
for imgname in imgs:
midname = imgname[23:imgname.rindex("_")] #[imgname.rindex("/")+1:]更改为[23:32]
img = load_img(self.data_path + "/" + midname + "_train.tif",grayscale = True)
label = load_img(self.label_path + "/" + midname + "_label.tif",grayscale = True)
img = img_to_array(img)
label = img_to_array(label)
#img = cv2.imread(self.data_path + "/" + midname,cv2.IMREAD_GRAYSCALE)
#label = cv2.imread(self.label_path + "/" + midname,cv2.IMREAD_GRAYSCALE)
#img = np.array([img])
#label = np.array([label])
imgdatas[i] = img
imglabels[i] = label
if i % 100 == 0:
print('Done: {0}/{1} train'.format(i, len(imgs)))
i += 1
print('loading done')
np.save(self.npy_path + '/imgs_train.npy', imgdatas)
np.save(self.npy_path + '/imgs_mask_train.npy', imglabels)
print('Saving to .npy files done.')
# 创建测试数据
def create_test_data(self):
i = 0
print('-'*30)
print('Creating test train...')
print('-'*30)
imgs = glob.glob(self.test_path+"/*."+self.img_type)
imgs.sort(key=lambda x: int(x.split('/')[2][:-4]))
print(len(imgs))
imgdatas = np.ndarray((len(imgs),self.out_rows,self.out_cols,1), dtype=np.uint8)
for imgname in imgs:
midname = imgname[imgname.rindex("/")+1:]
img = load_img(self.test_path + "/" + midname,grayscale = True)
img = img_to_array(img)
#img = cv2.imread(self.test_path + "/" + midname,cv2.IMREAD_GRAYSCALE)
#img = np.array([img])
imgdatas[i] = img
i += 1
print('loading done')
np.save(self.npy_path + '/imgs_test.npy', imgdatas)
print('Saving to imgs_test.npy files done.')
# 加载训练图片与mask
def load_train_data(self):
print('-'*30)
print('load train train...')
print('-'*30)
imgs_train = np.load(self.npy_path+"/imgs_train.npy")
imgs_mask_train = np.load(self.npy_path+"/imgs_mask_train.npy")
imgs_train = imgs_train.astype('float32')
imgs_mask_train = imgs_mask_train.astype('float32')
imgs_train /= 255
mean = imgs_train.mean(axis = 0)
imgs_train -= mean
imgs_mask_train /= 255
# 做一个阈值处理,输出的概率值大于0.5的就认为是对象,否则认为是背景
imgs_mask_train[imgs_mask_train > 0.5] = 1
imgs_mask_train[imgs_mask_train <= 0.5] = 0
return imgs_train,imgs_mask_train
# 加载测试图片
def load_test_data(self):
print('-'*30)
print('load test train...')
print('-'*30)
imgs_test = np.load(self.npy_path+"/imgs_test.npy")
imgs_test = imgs_test.astype('float32')
imgs_test /= 255
mean = imgs_test.mean(axis = 0)
imgs_test -= mean
return imgs_test
if __name__ == "__main__":
# 以下注释掉的部分为数据增强代码,通过他们可以将数据进行增强
aug = myAugmentation()
aug.Augmentation()
aug.splitMerge()
aug.splitTransform()
mydata = dataProcess(512,512)
mydata.create_train_data()
mydata.create_test_data()
imgs_train,imgs_mask_train = mydata.load_train_data()
print (imgs_train.shape,imgs_mask_train.shape)
unet.py
import os
#os.environ["CUDA_VISIBLE_DEVICES"] = "0"
import numpy as np
from keras.models import *
from keras.layers import Input, merge, Conv2D, MaxPooling2D, UpSampling2D, Dropout, Cropping2D
from keras.optimizers import *
from keras.callbacks import ModelCheckpoint, LearningRateScheduler
from keras import backend as keras
from data import *
class myUnet(object):
def __init__(self, img_rows = 512, img_cols = 512):
self.img_rows = img_rows
self.img_cols = img_cols
# 参数初始化定义
def load_data(self):
mydata = dataProcess(self.img_rows, self.img_cols)
imgs_train, imgs_mask_train = mydata.load_train_data()
imgs_test = mydata.load_test_data()
return imgs_train, imgs_mask_train, imgs_test
# 载入数据
def get_unet(self):
inputs = Input((self.img_rows, self.img_cols,1))
# 网络结构定义
'''
#unet with crop(because padding = valid)
conv1 = Conv2D(64, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(inputs)
print "conv1 shape:",conv1.shape
conv1 = Conv2D(64, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv1)
print "conv1 shape:",conv1.shape
crop1 = Cropping2D(cropping=((90,90),(90,90)))(conv1)
print "crop1 shape:",crop1.shape
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
print "pool1 shape:",pool1.shape
conv2 = Conv2D(128, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(pool1)
print "conv2 shape:",conv2.shape
conv2 = Conv2D(128, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv2)
print "conv2 shape:",conv2.shape
crop2 = Cropping2D(cropping=((41,41),(41,41)))(conv2)
print "crop2 shape:",crop2.shape
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
print "pool2 shape:",pool2.shape
conv3 = Conv2D(256, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(pool2)
print "conv3 shape:",conv3.shape
conv3 = Conv2D(256, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv3)
print "conv3 shape:",conv3.shape
crop3 = Cropping2D(cropping=((16,17),(16,17)))(conv3)
print "crop3 shape:",crop3.shape
pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
print "pool3 shape:",pool3.shape
conv4 = Conv2D(512, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(pool3)
conv4 = Conv2D(512, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv4)
drop4 = Dropout(0.5)(conv4)
crop4 = Cropping2D(cropping=((4,4),(4,4)))(drop4)
pool4 = MaxPooling2D(pool_size=(2, 2))(drop4)
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(pool4)
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv5)
drop5 = Dropout(0.5)(conv5)
up6 = Conv2D(512, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(drop5))
merge6 = merge([crop4,up6], mode = 'concat', concat_axis = 3)
conv6 = Conv2D(512, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(merge6)
conv6 = Conv2D(512, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv6)
up7 = Conv2D(256, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv6))
merge7 = merge([crop3,up7], mode = 'concat', concat_axis = 3)
conv7 = Conv2D(256, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(merge7)
conv7 = Conv2D(256, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv7)
up8 = Conv2D(128, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv7))
merge8 = merge([crop2,up8], mode = 'concat', concat_axis = 3)
conv8 = Conv2D(128, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(merge8)
conv8 = Conv2D(128, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv8)
up9 = Conv2D(64, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv8))
merge9 = merge([crop1,up9], mode = 'concat', concat_axis = 3)
conv9 = Conv2D(64, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(merge9)
conv9 = Conv2D(64, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv9)
conv9 = Conv2D(2, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv9)
'''
conv1 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(inputs)
print ("conv1 shape:",conv1.shape)
conv1 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv1)
print ("conv1 shape:",conv1.shape)
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
print ("pool1 shape:",pool1.shape)
conv2 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool1)
print ("conv2 shape:",conv2.shape)
conv2 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv2)
print ("conv2 shape:",conv2.shape)
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
print ("pool2 shape:",pool2.shape)
conv3 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool2)
print ("conv3 shape:",conv3.shape)
conv3 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv3)
print ("conv3 shape:",conv3.shape)
pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
print ("pool3 shape:",pool3.shape)
conv4 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool3)
conv4 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv4)
drop4 = Dropout(0.5)(conv4)
pool4 = MaxPooling2D(pool_size=(2, 2))(drop4)
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool4)
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv5)
drop5 = Dropout(0.5)(conv5)
up6 = Conv2D(512, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(drop5))
merge6 = merge.concatenate([drop4,up6], axis = 3)
conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge6)
conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv6)
up7 = Conv2D(256, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv6))
merge7 = merge.concatenate([conv3,up7], axis = 3)
conv7 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge7)
conv7 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv7)
up8 = Conv2D(128, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv7))
merge8 = merge.concatenate([conv2,up8], axis = 3)
conv8 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge8)
conv8 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv8)
up9 = Conv2D(64, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv8))
merge9 = merge.concatenate([conv1,up9], axis = 3)
conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge9)
conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv9)
conv9 = Conv2D(2, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv9)
conv10 = Conv2D(1, 1, activation = 'sigmoid')(conv9)
model = Model(inputs = inputs, outputs = conv10)
model.compile(optimizer = adam_v2.Adam(lr = 1e-4), loss = 'binary_crossentropy', metrics = ['accuracy'])
return model
# 如果需要修改输入的格式,那么可以从以下开始修改,上面的结构部分不需要修改
def train(self):
print("loading data")
imgs_train, imgs_mask_train, imgs_test = self.load_data()
print("loading data done")
model = self.get_unet()
print("got unet")
model_checkpoint = ModelCheckpoint('my_unet.hdf5', monitor='loss',verbose=1, save_best_only=True)
print('Fitting model...')
model.fit(imgs_train, imgs_mask_train, batch_size=2, epochs=10, verbose=1,validation_split=0.2, shuffle=True, callbacks=[model_checkpoint])
print('predict test data')
imgs_mask_test = model.predict(imgs_test, batch_size=1, verbose=1)
np.save('/Users/fengyuting/Documents/pycharm/CV/Unet/unet-master2/results/imgs_mask_test.npy', imgs_mask_test)
def save_img(self):
print("array to image")
imgs = np.load('/Users/fengyuting/Documents/pycharm/CV/Unet/unet-master2/results/imgs_mask_test.npy')
# 二值化
# imgs[imgs > 0.5] = 1
# imgs[imgs <= 0.5] = 0
for i in range(imgs.shape[0]):
img = imgs[i]
img = array_to_img(img)
img.save("/Users/fengyuting/Documents/pycharm/CV/Unet/unet-master2/results/results_jpg/%d.jpg"%(i))
if __name__ == '__main__':
myunet = myUnet()
myunet.train()
myunet.save_img()
实验结果


增强前 增强后 (x2)