DenseNet——密集连接的卷积神经网络
-
论文题目:Densely Connected Convolutional Networks
-
论文地址:https://arxiv.org/pdf/1608.06993.pdf
-
发表于:cvpr,2017
前言
ResNet模型的核心是通过建立前面层与后面层之间的“短路连接”(skip connection),这有助于训练过程中梯度的反向传播,从而能训练出更深的CNN网络。DenseNet模型基本思路与ResNet一致,但是它建立的是前面所有层与后面层的密集连接(dense connection),通过特征在channel上的连接来实现特征重用(feature reuse)。这些特点让DenseNet在参数和计算成本更少的情形下实现比ResNet更优的性能,也因此斩获CVPR 2017的最佳论文奖。
文章目录
一、研究动机与创新点
二、相关工作
三、主要内容
1、密集连接(Dense connectivity)
2、复合函数(Composite function)
3、池化层(Pooling layers)
4、增长率(Growth rate)
5、瓶颈层(Bottleneck layers)
6、压缩操作(Compression)
四、实验设置
五、实验结果
一、研究动机与创新点
CNN史上的一个里程碑事件是ResNet模型的出现,ResNet可以训练出更深的CNN模型,从而实现更高的准确度,其核心是通过建立前面层与后面层之间的“短路连接”(shortcuts,skip connection),训练出更深的CNN网络。
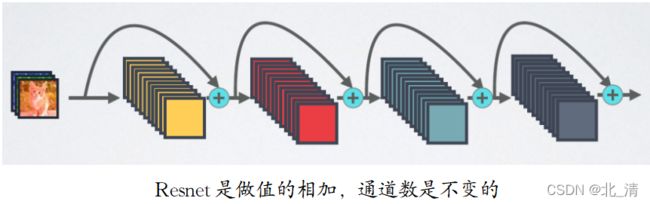
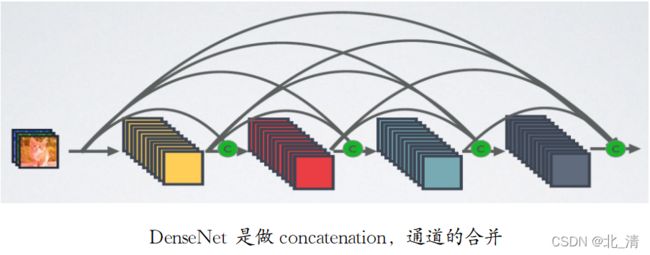
DenseNet模型基本思路与ResNet一致,但是它建立的是后面层与前面所有层的密集连接(Dense Connection)。其另一大特色是通过特征在channel维度上的连接来实现特征重用(Feature Reuse)。DenseNet缓解了梯度消失问题,加强了特征传播,鼓励了特征重用,并大大减少了参数的数量。这些特点让DenseNet在参数和计算成本更少的情形下实现比ResNet更优的性能,DenseNet也因此斩获CVPR 2017的最佳论文奖。
梯度消失问题在网络深度越深的时候越容易出现,原因是输入信息和梯度信息在很多层之间传递导致的,而Dense connection相当于每一层都直接连接input和loss,因此可以减轻梯度消失现象。
二、相关工作
现代网络中层数的增加放大了架构之间的差异,并激发了对不同连接模式的探索和对旧的研究思想的重新审视。早期以分层的方式训练完全连接的多层感知器。最近提出了用批处理梯度下降训练的全连接级联网络。虽然对小数据集有效,但这种方法只可以扩展到具有几百个参数的网络。通过短路连接来利用CNN中的多层次特征已被发现对各种视觉任务都是有效的。
Highway网络是第一批提供了一种有效训练超过100层的端到端网络的手段的架构之一。使用旁路路径和门单元,数百层的Highway网络可以轻松地优化。旁路路径被认为是简化这些非常深的网络的训练的关键因素。ResNets进一步支持了这一点,其中纯恒等映射被用作旁路路径。ResNets在许多具有挑战性的图像识别、定位和检测任务上都取得了令人印象深刻的、破纪录的性能,如ImageNet和COCO目标检测。最近,随机深度被提出作为一种成功训练1202层ResNet的方法。随机深度通过在训练过程中随机删除图层来改进深度残差网络的训练。这表明并非所有的层都需要的,并强调了在深度残差网络中有大量的冗余。
增加网络的宽度是使网络更深入的一种正交方法(例如,借助于短路连接的帮助)。GoogLeNet使用了一个“初始模块”,它连接了由不同大小的过滤器产生的特征映射。事实上,只要深度足够,简单地增加每个ResNets中的滤波器的数量就可以提高其性能。通过使用广泛的网络结构,框架集在多个数据集上也取得了有竞争力的结果。
DenseNets没有从极其深或广泛的架构中获取表示能力,而是通过特征重用来利用网络的潜力,生成易于训练和高度参数化的压缩模型。连接由不同层学习到的特征图增加了后续层输入的变化,并提高了效率。这构成了数据网和重置网之间的主要区别。与同样连接不同层特征的初始网络相比,网络更简单、更高效。
NIN(网络中的网络)结构将微多层感知器包含到卷积层的滤波器中,以提取更复杂的特征。在深度监督网络(DSN)中,内层直接由辅助分类器进行监督,这可以加强早期层所接收到的梯度。梯网将横向连接引入自动编码器,在半监督学习任务上产生令人印象深刻的准确性。深度融合网络(DFNs),通过结合不同基础网络的中间层来改善信息流。具有最小化重建损失路径的网络增强也可以改善图像分类模型。
三、主要内容
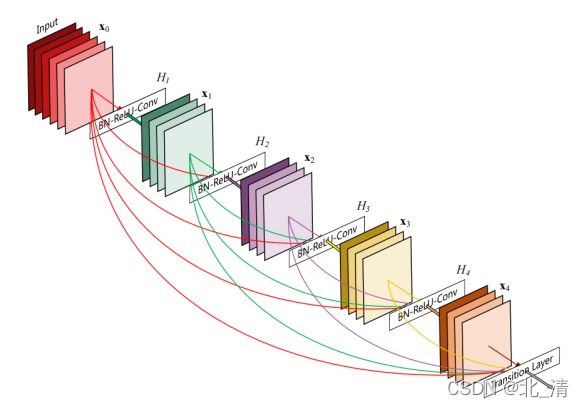
1、密集连接(Dense connectivity)
为了进一步改善层之间的信息流,我们提出了一种不同的连接模式:我们引入了从任何层到所有后续层的直接连接。xl表示的是第l层的输出,第l层接收到的是前面l-1层的特征映射 [x0,x1, ……,xl−1] 指的是从第0层到第l−1层中产生的特征映射的连接:
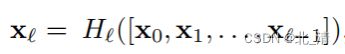
2、复合函数(Composite function)
将H(.)定义为三个连续操作的复合函数:批处理归一化(BN)、校正线性单元(ReLU)、3×3卷积(Conv)。
3、池化层(Pooling layers)

卷积网络的一个重要部分是改变特征映射大小的下采样层,为了便于在我们的架构中进行下采样,将网络划分为多个密集连接的密集块,我们将块之间的层称为过渡层,它可以进行卷积和池化,在实验中使用的过渡层包括批处理归一化层、1×1卷积层和2×2平均池化层。
4、增长率(Growth rate)
如果每个函数H产生k个特征图,那么第l层有k0+k×(l−1)个输入特征图,其中k0是输入层的通道数。DenseNet和现有的网络架构之间的一个重要区别是,DenseNet可以有非常狭窄的层,例如,k=12。我们把超参数k称为网络的增长率。一个相对较小的增长率就足以在测试的数据集上获得最先进的结果。对此的一种解释是,每个层都可以访问其块中的所有前面的特征映射,因此,也可以访问网络的“集体知识”。人们可以将特征映射视为网络的全局状态。每一层都添加了k个自己的特征映射。增长率调节了每一层对全局状态贡献的新信息。全局状态一旦被写入,就可以从网络内的任何地方进行访问,而且与传统的网络架构不同,它不需要逐层复制它。
5、瓶颈层(Bottleneck layers)
虽然每一层只产生k个输出特性映射,但它通常有更多的输入。在每次3×3卷积之前,可以引入1×1卷积作为瓶颈层,以减少输入特征图的数量,既能降维减少计算量,又能融合各个通道的特征,从而提高计算效率。这种设计对DenseNet特别有效,将具有这种瓶颈层的网络,即BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3)版本的H,称为DenseNet-B。在我们的实验中,我们让每个1×1的卷积产生4k个特征映射。
6、压缩操作(Compression)
为了进一步提高模型的紧致性,可以减少过渡层上的特征映射的数量。如果一个密集块包含m个特征映射,我们让下面的过渡层生成θm个输出特征图,其中0<θ≤1称为压缩因子。当θ=1时,跨过渡层的特征映射的数量保持不变。我们将使用θ<1的DenseNet称为DenseNet-C,并在实验中设置了θ=0.5。当同时使用了θ<1的瓶颈层和过渡层时,我们将我们的模型称为DenseNet-BC。
四、实验设置
在除ImageNet之外的所有数据集上,我们实验中使用的DenseNet有三个密集的块,每个块都有相同数量的层。在进入第一个密集块之前,对输入图像进行16个(或DenseNet-BC增长率的两倍)输出通道的卷积。对于内核大小为3×3的卷积层,输入的每一边都被零填充一个像素,以保持特征映射的大小不变。我们使用1×1卷积,然后使用2×2平均池化作为两个相邻密集块之间的过渡层。在最后一个密集块的最后,执行一个全局平均池,然后附加一个softmax分类器。三个密集块的特征图大小分别为32×32、16×16和8×8。我们实验了配置{L=40,k=12},{L=100,k=12}和{L=100,k=24}的基本DenseNet结构。对于DenseNet-BC,评估配置为{L=100、k=12}、{L=250、k=24}和{L=190、k=40}的网络。
在ImageNet上的实验中,我们在224×224输入图像上使用了一个具有4个密集块的DenseNet-BC结构。初始卷积层包括2k卷7×7,步幅2;所有其他层的特征映射的数量也遵循设置k。我们在ImageNet上使用的确切网络配置如下示。所有网络的增长率均为k=32,表中所示的每个“conv”层都对应于序列BN-ReLU-conv。
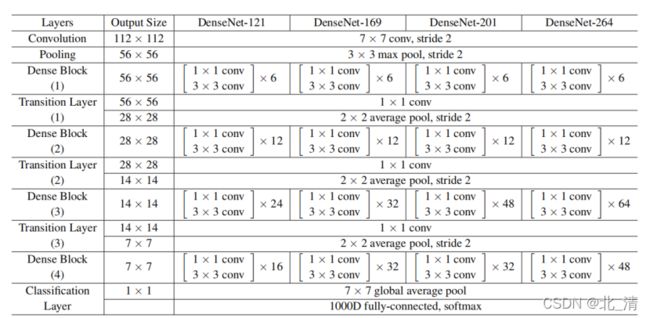
五、实验结果
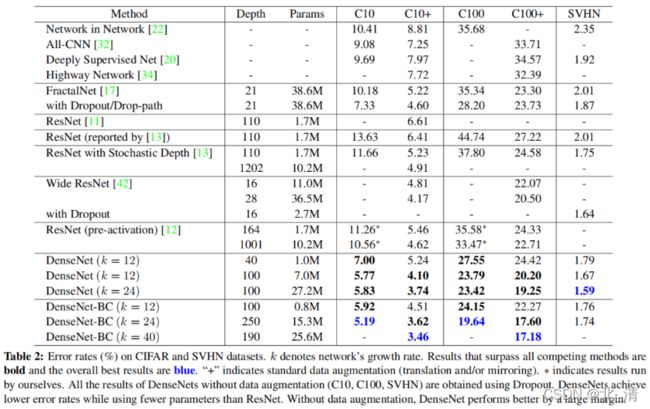
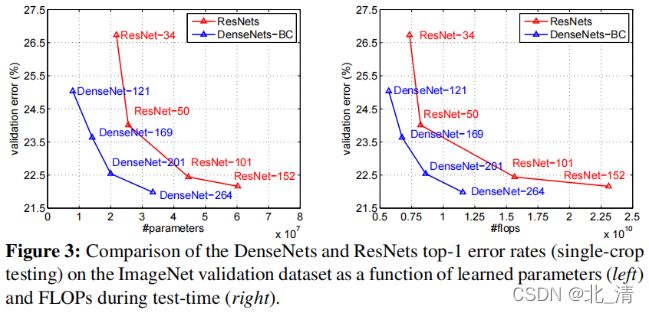
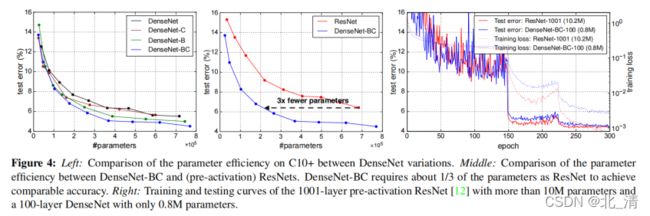
总结
DenseNet核心思想在于建立了不同层之间的连接关系,充分利用了feature,进一步缓解了梯度消失问题。另外,利用瓶颈层和过渡层以及较小的增长率使得网络变窄,参数减少,有效抑制了过拟合,同时计算量也减少了。