[NLP] 实体消歧论文阅读—Entity Disambiguation by Knowledge and Text Jointly Embedding
实体消歧论文阅读—Entity Disambiguation by Knowledge and Text Jointly Embedding
原文link: Entity Disambiguation by Knowledge and Text Jointly Embedding
前言
本篇论文是知识图谱任务中的实体消歧,花了几天时间阅读一遍,在这里将我对原文的理解阐述出来,大部分是根据原文翻译,直译比较难以理解的部分就用我自己的想法打出来。
大多消歧系统都是mention和实体的基于词袋的特征表示,但是BoW有一些缺点:
- 忽略单词/实体的内部含义
- 高维度向量空间以及昂贵计算
- 对不同应用,需要手工设计不同表示,缺少了泛化的指导
先利用联合同个向量空间中的embedding knowledge base and text,学习单词和实体的低维连续向量表示,再利用这些embedding去设计简单但有效的特征,构建一个2-layer的消歧模型。
1 Introduction
given 在文档d中的mention 集合 M = { m 1 , m 2 , … , m k } M = \{m1, m2, …, mk\} M={m1,m2,…,mk},特定的或自动检测的都可,每个mention m i ∈ M m_i \in M mi∈M,目标是找到知识库KB中对应的正确实体
一般的实体链接步骤:
1) 从raw data中为mention/entity构建表示,通常是稀疏向量形式
2) 从基于mention和实体的消歧模型中抽取出特征
3) 在抽取出的特征上设置参数、学习权重来优化消歧模型,例如:训练一个分类器或排序器。
本文强调第一步骤,一般实体链接强调第二、三步骤
有少数特征是由启发式规则直接定义的,跳过了第一个步骤(从raw data中构建向量表示)。可以是
1) 利用mention表面形式和实体标准形式的字串相似度/编辑距离
2) 指向实体的mention表面形式的先验概率
但是这些非常少数,而且对人类来说要设计这种特征是很困难的。
实体链接的第一步骤常见的作法就是定义手工的BoW表示。
实体常以 “包含实体的n-grams文本”上权重的稀疏向量来表示,例如Bag-of-Words表示,TF-IDF也常用于设置权重。此类方式有一些变体,例如使用选定的key phrases(关键短语)或Wikipedia in-links/out-links(入/出的连结)而不是直接把所有n-gram当作向量维度来使用。
更具挑战性的问题:mention若用n-gram表示,但是window_size有限,对于mention的表示来e说也会受到局限,在实际使用中,也有另外的限制:实体和mention地表示应该要在同个空间,例如要共享向量维度。这种限制让设计表示更加困难,这就是消歧系统的商业机密所在。例如Cucerzan(2007)用维基百科的anchor surfaces和目录的值当作维度,设计了复杂机制,用这个维度上的稀疏向量来表示单词、mention和实体。
BoW也存在一些隐含的缺点。例如:
1) 单一维度上的语义会严重的被忽视
2) BoW常常会引入高维向量空间,导致计算上的成本过大
3) 对于不同应用,设计人工表示也会不同,缺乏一个general指引
一些直观的问题像是“为何要使用n-grams、维基百科链接或目录值当作维度”或是“为什么要把TF-IDF当作权重”可以看出来,手工表示并不是最好的,应该还存在一些更好的表示法。
本文着重在实体链接的第一步骤:向量表示步骤
- (因)启发:
- word embedding方法(Bengio et al., 2003; Collobert et al., 2011; Mikolov et al., 2013a; - Mikolov et al., 2013b)
- knowledge embedding的方法(Bordes et al., 2011; Bordes et al., 2013; Socher et al., 2013; Wang et al., 2014b)
- 联合嵌入知识库和文本joint embedding KBs and texts的方法(Wang et al., 2014a; Zhong and Zhang, 2015 )
- (果)本文方法:
- 本文提出了对实体消歧的表示学习,特别是来自知识库及文本的实体和单词,联合将实体和单词嵌入到同样的低维连续向量空间。
- 优点:
- 借由考虑知识库及文本中所有信息进行全局目标优化得到embedding,可以保留单词和实体的内涵语义(intrinsic sematics)。
- 下一步:
- 设计了基于embedding的简单有效特征和2层消歧模型,对真实数据集进行了延伸的实验,展现了我们对于单词及实体表示的效率
2. Related work
Entity Disambiguation 实体消歧
- local方法 本地方法
- 在文档中独立对每一个mention进行消歧
- Bunescu and Pasca(2006)比较了同一候选实体的维基百科目录中的每个mention的上下文
- Miline and Witten(2008)提出了消歧链接的概念,以便于计算实体相关性
- collective方法 集体方法 关键字:coherence
- 与本地方法不同,需要文档中所有语义上一致(coherent)的所有实体,用一些目标函数去measure。
- Cucerzan(2007)提出了主题表示(topic representation),聚集文档中所有候选实体的主题向量
- Kulkarnu(2009)对于每对实体(2个不同mention)pair-wise(逐对)找一致的候选实体,使用hill-climbing算法得到近似解
- Hoffart(2011)把实体消歧视为找到在大型图中,含有所有mention节点、每个mention恰有一个mention-实体的边的稠密子图的任务
- 以上大部分方法都需要为mention和实体设计不同的表示。
- 例如Cucerzan(2007)使用锚文本表面来表示在上下文空间的实体,使用目录相来表示在主题空间的实体,使用固定大小的window找mention的上下文作为上下文向量。
- Kulkarni et al. (2009)利用单词集合、单词计数集合和TF-IDF集合来表示实体。
- Retinov et al. (2011)用延伸的in-links和out-links表示实体。
- 近年的工作则着重于将如何从上下文中应用NN于消歧系统。
- 例如 He et al. (2013)使用前向网络去表示基于BoW输入的上下文,此时Sun et al. (2015)在word2vec(Mikolov et al., 2013a)的基础上直接使用卷积网络。然而这些工作都较不注重于设计有效的单词和实体表示。
- 本文将专注于针对消歧学习表示单词和实体向量。
Embedding
- 这边只做简略的介绍:
- word embedding目的是在于学习单词的连续向量表示,有Skip-Gram方法和Bag-of-Word方法,通过预测当前词的上下文单词或是预测当前词来无监督的学习word embedding(Bengio et al., 2003; Collobert et al., 2011; Mikolov et al., 2013a; Mikolov et al., 2013b)
- 近年还有knowledge embedding,目的是将知识图谱的实体和关系嵌入到低维的连续向量空间中,同时也保留图的某些特性(Bordes et al., 2011; Bordes et al., 2013; Socher et al., 2013; Wang et al., 2014a; Wang et al., 2014b)。
- 为了连接word embedding和knowledge embedding,(Wang et al., 2014a)提出通过维基百科的锚点和实体名称来对齐这两个嵌入空间。(Zhong and Zhang, 2015)根据实体的描述进行调整。
3 Disambiguation by Embedding 用嵌入做消歧
这里要先完善当前的联合嵌入技术来训练Freebase和维基百科的文本中的单词和实体embedding以便于后续的消歧任务。然后基于embedding设计简单特征,最后再提出一个两层的消歧模型,以平衡mention-实体先验和其他特征。
3.1 Embeddings Jointly Learning 嵌入联合学习
- 主要基于 Wang et al. (2014a)的联合模型框架,再利用Zhong and Zhang(2015)的对齐技术,将单词和实体embedding在同个空间中对齐。
- 针对消歧,从两个方面优化了embedding:
- 增加了从维基百科中共现的url-anchor(entity-entity)
- 改善了传统的负采样部分,让候选实体清单更有可能被采样,目标是能从别的候选实体中对候选实体做消歧。
Knowledge Model 知识模型
- 知识库K常由三元组 ( h , r , t ) (h, r, t) (h,r,t)组成, h , t h, t h,t属于实体集合, r r r属于关系集合。这里跟随(Wang e al. 2014a)使用 h , r , t \mathbf{h},\mathbf{r},\mathbf{t} h,r,t表示 h , r , t h,r,t h,r,t的embedding
- 三元组分数计算:
- z ( h , r , t ) = b − 1 2 ∥ h + r − t ∥ 2 z(h,r,t)=b-\frac{1}{2}\|\mathbf{h}+\mathbf{r}-\mathbf{t}\|^2 z(h,r,t)=b−21∥h+r−t∥2, (1)
- b:近似优化阶段中数值稳定性的常数
- 对z做归一化:
- P r ( h ∣ r , t ) = exp { z ( h , r , t ) } ∑ h ~ ∈ ε exp { z ( h ~ , r , t ) } \mathsf{Pr}(h|r,t)=\frac{\exp\{z(h,r,t)\}}{\sum_{\tilde{h}\in\varepsilon}\exp\{z(\tilde{h},r,t)\}} Pr(h∣r,t)=∑h~∈εexp{z(h~,r,t)}exp{z(h,r,t)}, (2)
- P r ( r ∣ h , t ) \mathsf{Pr}(r|h,t) Pr(r∣h,t)和 P r ( t ∣ h , r ) \mathsf{Pr}(t|h,r) Pr(t∣h,r)也是同样方式定义
- 似然函数:
- L t r i p l e t ( h ∣ r , t ) = log P r ( h ∣ r , t ) + log P r ( r ∣ h , t ) + log P r ( t ∣ h , r ) L_{triplet}(h|r,t)=\log\mathsf{Pr}(h|r,t)+\log\mathsf{Pr}(r|h,t)+\log\mathsf{Pr}(t|h,r) Ltriplet(h∣r,t)=logPr(h∣r,t)+logPr(r∣h,t)+logPr(t∣h,r), (3)
- 目标函数:最大化所有知识图谱内三元组的似然函数
- L K = ∑ ( h , r , t ) ∈ K L t r i p l e t ( h , r , t ) L_K=\sum_{(h,r,t)\in \mathcal{K}}L_{triplet}(h,r,t) LK=∑(h,r,t)∈KLtriplet(h,r,t), (4)
Text Model
- 为了跟knowledge model兼容,用下面的方式对共现词对评分:
- z ( w , v ) = b − 1 2 ∥ w − v ∥ 2 z(w,v)=b-\frac{1}{2}\|\mathbf{w}-\mathbf{v}\|^2 z(w,v)=b−21∥w−v∥2, (5)
- w, v代表在上下文window内出现的共现词,粗体w,v代表相应的embedding
- 归一化:
- P r ( w ∣ v ) = exp { z ( w m v ) } ∑ w ~ ∈ V exp { z ( w ~ , v ) } \mathsf{Pr}(w|v)=\frac{\exp\{z(wmv)\}}{\sum_{\tilde{w}\in V}\exp\{z(\tilde{w},v)\}} Pr(w∣v)=∑w~∈Vexp{z(w~,v)}exp{z(wmv)}, (6)
- V: vocabulary
- 目标函数 最大化似然函数:
- L T ( w , v ) = log P r ( w ∣ v ) + log P r ( v ∣ w ) L_T(w,v)=\log\mathsf{Pr}(w|v)+\log\mathsf{Pr}(v|w) LT(w,v)=logPr(w∣v)+logPr(v∣w), (7)
Alignment Model
- 保证了单词和实体的embedding在同个空间里,例如:相似度/距离值是有意义的。本文结合了下列三个对齐模型(Wang et al., 2014a; Zhong and Zhang, 2015):
- Alignment by Wikipedia Anchors(section links)(Wang et al., 2014a)
把mention替换成连结到的实体,共现的单词-单词变成共现的单词-实体
L A A = ∑ ( w , a ) , a ∈ A [ ] log P r ( w ∣ e a ) + log P r ( e a ∣ w ) ] L_{AA}=\sum_{(w,a),a\in A}[]\log Pr(w|e_a)+\log Pr(e_a|w)] LAA=∑(w,a),a∈A[]logPr(w∣ea)+logPr(ea∣w)], (8)
A: anchors集合
e a e_a ea: anchor a代表的实体 - Alignment by Names of Entities(Wang et al., 2014a)
对于每个三元组(h,r,t),h或t用他们相应的名称取代,得到了、和,w_h表示h的名称,w_t表示t的名称。

- Alignment by Entities’ Description(Zhong and Zhang, 2015)
利用維基百科url頁面描述的url和單詞的共現,這跟Le and Mikolov, 2014的PV-DBOW model很相似。
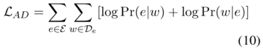
E:候選實體集合;De:實體e的描述。
澄清:”url”在這裏跟”實體”是指同個東西。
結合這些對齊技術,得到整個對齊模型:
L A = L A A + L A N + L A D , ( 11 ) L_A=L_{AA}+L_{AN}+L_{AD}, (11) LA=LAA+LAN+LAD,(11)
- Alignment by Wikipedia Anchors(section links)(Wang et al., 2014a)
Url-Anchor Co-occurrence 超链接-锚共现
- 对实体消歧系统来说,实体关联图对于捕捉维基百科实体的“主题”是很有用的,因此我们也希望能将这种信息编码进我们的embedding中。特别是我们会进一步的结合“url-anchor”的共现至训练目标。
- “url”代表维基百科页面
- “anchor”代表页面中锚的超链接
- L U = ∑ e ∈ E ∑ a ∈ A D e [ P r ( e ∣ e a ) + P r ( e a ∣ e ) ] , ( 12 ) L_U=\sum_{e\in E} \sum_{a\in A_{D_e}}[Pr(e|e_a)+Pr(e_a|e)], (12) LU=∑e∈E∑a∈ADe[Pr(e∣ea)+Pr(ea∣e)],(12)
- A D e A_{D_e} ADe代表维基百科页面 D e D_e De中的所有anchors
- P r ( e ∣ e a ) Pr(e|e_a) Pr(e∣ea)和 P r ( e a ∣ e ) Pr(e_a|e) Pr(ea∣e)代表eq.(6)中定义的相似度
- 考虑知识模型、文本模型、对齐模型和url-anchor共现,我们最大化这些模型的似然函数:
- L = L K + L T + L A + L U , ( 13 ) L=L_K+L_T+L_A+L_U, (13) L=LK+LT+LA+LU,(13)
Negative Sampling Refinement 负采样改善
*负采样:
- 构造一个新的监督学习问题:give a pair of words,例如(orange, juice)来预测是否是一对context-target
- (orange, juice)是正样本,标为1,负样本就是标为0的其他juice以外的单词,例如(orange, king)
- 生成一个正样本,抽取一个context,在一定window_size内选一个target,生成表的第一row,即:orange-juice-1的过程
- 生成一个负样本,用相同context,再次再字典中随机选取一个词标为0(因为随机选很大可能跟中心词orange没有关联)
- 构造监督学习问题,学习输入x(a pair of words),预测目标的标签输出y
- 负采样中某个固定的正样本对应k个负样本,即模型总共包含k+1个二分类,比之前有vocabulary_size个输出单元的softmax分类,负采样转化为k+1个二分类问题。
- 在训练阶段,为了避免(2)和(6)的归一化计算,跟从(Mikolov et al., 2013b)的方法,将原本softmax形式的目标函数转换至简单的二分类目标函数,为的是可以从噪声中辨别出观察数据。
- 为了优化实体消歧,使用上下文单词来预测一个anchor(实体),例如:优化Pr(e_a|w)而不是制式从单词库里进行(Mikolov et al., 2013b)的负采样,我们根据候选实体的先验分布来总结我们的采样方法。
3.2 Disambiguation Features Design 消歧特征设计
- 有了上面我们训练的embedding后,许多实体消歧方法可以直接将他们视为单词和实体的表示,重新定义其特征。这里只需设计简单的特征来表达消歧中embedding的功能。实验章节中我们可以发现,即使只用了单一embedding-based特征,也比数个BoW-based特征的组合还要好。
- Mention-Entity Prior Mention-实体先验
- 这个特征是直接从维基百科的anchor fields计数而来,given a mention m的实体e,计算可能是链接的概率。
- 先验(prior)是对于是否选择正确实体的一个强指标(Fader et al., 2009)。但是如果总是只用先验作为特征的话会有非常大的权重,会使训练数据上发生过拟合。
- 本文提出了一个分类器,可以辨别何时才要使用先验作为特征。
- 下面是三个设计的特征:
- (1) Global Context Relatedness (E-GCR) 全局上下文关联
- 前提是假设mention真实的实体与同文档中大多数其他单词的意义一样
- 所以这个特征将所有候选实体与每一个上下文单词的idf weighted关联分数加总起来,再做平均
- (1) Global Context Relatedness (E-GCR) 全局上下文关联
- ∀ e ∈ Γ ( m ) , E − G C R ( e , d ∣ m ) = 1 ∣ d ∣ ∑ w ∈ d i d f ( w ) Ω ( e , w ) , ( 14 ) \forall e \in \Gamma(m), E-GCR(e,d|m)=\frac{1}{|d|}\sum_{w\in d}idf(w)\Omega(e,w), (14) ∀e∈Γ(m),E−GCR(e,d∣m)=∣d∣1∑w∈didf(w)Ω(e,w),(14)
- 对于文档中每个单词,计算单词的IDF与先前embedding模型的embedding和words距离关联性相乘,再与文档长度做平均。
- d:文档;e: 实体;w: word
- Γ ( m ) \Gamma(m) Γ(m)代表mention m的候选实体集合
- Ω ( e , w ) \Omega(e,w) Ω(e,w)代表基于距离的关联(relatedness): b − 1 2 ∥ e − w ∥ 2 b-\frac{1}{2}\|\mathbf{e-w}\|^2 b−21∥e−w∥2,这与embedding model兼容
- IDF: 语 料 库 文 档 总 数 包 含 该 词 的 文 档 数 + 1 \frac{语料库文档总数}{包含该词的文档数+1} 包含该词的文档数+1语料库文档总数
- (2) Local Context Relatedness (E-LCR) 本地上下文关联
- E-GCR只能粗略的将与主题相关的候选实体排在前几个位置的其中之一而已,但有时真识实体和文档主题之间几乎没有任何关系。
- 例如:”Stefani, a DJ at The Zone 101.5 FM in Phoenix, AZ, sent me an awesome MP3 of the interview.” 这句话的意思是亚利桑那州凤凰城The Zone 101.5 FM的DJ向我发送了一份很棒的采访MP3,AZ指的是亚利桑那州,但是如果使用E-GCR只与文档主题(关于音乐)相关的话,就会把AZ与AZ(嘻哈歌手)链接,造成了实体链接不正确。
- 为了防止这种错误发生,我们设计了一种特征可以描述候选实体和mention周围重要单词的关联性。要找出这些单词,我们转向Stanford CoreNLP(Manning et al., 2014)的依存分析工具,把特征形式化为:
- ∀ e ∈ Γ ( m ) , E − L C R ( e , d ∣ m ) = 1 ∣ S d e p e n d ∣ ∑ w ∈ S d e p e n d Ω ( e , w ) , ( 15 ) \forall e \in \Gamma(m), E-LCR(e,d|m)=\frac{1}{|S_{depend}|}\sum_{w\in S_{depend}}\Omega(e,w), (15) ∀e∈Γ(m),E−LCR(e,d∣m)=∣Sdepend∣1∑w∈SdependΩ(e,w),(15)
- S d e p e n d S_depend Sdepend:在文档 d d d的依存图中,由mention m m m的所有邻近单词组成的集合
- (3) Local Entity Coherence (E-LEC) 本地实体一致性
- 现实中有很多随意的mention用法链接到实体,像是w v会链接到West Virginia:
- “We would like to welcome you to the official website for the city of Chester, w v.”
- 这个案例中,”w v”应该是对”Chester”歧义的强烈暗示,然而如果只取其字面上的意义,”w”, “v”或”w v”用作捕捉有用信息来说太随意了。因此我们不只要取这种相关的表面形式,还要取他们的候选实体来纳入考量。
- 因此实体”West Virginia”对”Chester”链接到“Chester, West Virginia”有帮助。这个特征跟前面的collective(集体)或topic-coherence(主题一致性)方法很相似。而我们的本地实体一致性会更精确,因为只考虑相关的mention/实体,而不是文档中的所有实体。E-LEC的公式:

3.3 Two-layer Disambiguation Model 两层消歧模型
- 为了平衡先验和其他特征的使用,我们提出一个2-layer的消歧模型。
- (1) 建立一个二元分类器,给出概率p_conf,表示只使用先验作为特征的置信度。特征使用E-GCR构造出一个分类器,mention单词本身和window_size=4内的上下文单词。
- (2) 如果p_conf超过一定阈值,则仅在选择最佳候选实体之前使用,否则只考虑其他3.2节中基于embedding的特征(E-GCR、E-LCR、E-LEC)

4 Experiments
- 比较我们的embedding-based features和数个传统BoW-based features,说明2层消歧系统的性能。
- 在实体消歧任务中比较我们的embedding技术EDKate与其他简单的解决方法。
- 最后将侦测mention的方法与消歧系统来与其他现存系统比较。
4.1 数据:
- 使用Freebase作为知识库,全部的维基百科语料作为文本语料。实验对比中,测试环节也使用了一些小的分支语料。
- 数据预处理—维基百科:
- 过滤掉非英语和非实体页面,用html样板从中抽取文本和anchor信息。
- 在某些实验里,只考虑“有效实体(valid entities)”和“(filtered)” tag会被加入到数据集的名称中。
- Valid Entities 有效实体
- 在某些实验中,我们将KB实体限制在维基百科训练集中,为提高效率,删除在Wikipedia训练集中提到少于3次的实体,其余实体为“有效实体”。
- Knowledge Base 知识库
- Freebase
- 只需要链接mention至维基百科的实体,所以过滤掉头或尾不包含在维基百科内的三元组。
- Small Benchmark Corpus
- 除维基百科,也用其他小的分支数据集来评估我们的embedding-based方法。
- KBP 2010,一个文档只有一个mention
- AQUAINT,由(Milne and Witten, 2008) 模仿维基百科结构而来
- 其他还有MSNBC、ACE等
- Difficult Set
- 大部分例子可以透过mention-实体的先验就解决,而不用透过上下文来解决,但也有一些例子只使用先验不能很好解决,我们认为消歧应该要更注重于这类例子。
- 因此我们从测试及中收集了只透过先验不能将正确的实体排在第一的状况,把这些单独构建成一个”difficult set”。
4.2 Embedding Training
- SGD随机梯度下降来优化目标eq.13(就是把三个embedding模型加起来)
- embedding dimension=150,用接近0的随机数初始化embedding vector的每个元素。
- b先用经验法则设置7
- 在knowledge model中:
- 使用Freebase作为知识库,没有设置固定的epoch number,知识的训练线程在下一个文本训练线程结束前不会停止,此外还将知识训练中的学习率调整为文本训练中的学习率。
- 当考虑一个三元组 ( h , r , t ) (h, r, t) (h,r,t)时,为了要构建 ( h ~ , r , t ) (\tilde{h},r,t) (h~,r,t)、 ( h , r ~ , t ) (h,\tilde{r},t) (h,r~,t)和 ( h , r , t ~ ) (h,r,\tilde{t}) (h,r,t~),设置负样本的数=10,其中 h ~ \tilde{h} h~和 t ~ \tilde{t} t~是从实体集合E中均匀采样, r ~ \tilde{r} r~是从关系集合R中均匀采样。
- text model中:
- 使用过滤的维基百科训练集作为文本与料,设置epoch number=6,初始学习率0.025,在训练过程中线性下降。
- 当遇到一个单词,使用window_size=5来获取共现词,对于每个共现词,提高到3.4次方的一元分布中取30个负样本,
- alignment model:
- 用维基百科和实体名称对齐。
- “按维基百科锚对齐”和“按实体名称对齐”可以分别吸收到文本模型和知识模型中。
- 对于“按实体的描述对齐”,我们在 P r ( e ∣ w ) Pr(e|w) Pr(e∣w)中采样了10个负样本, P r ( w ∣ e ) Pr(w|e) Pr(w∣e)中采样了30个负样本。
- 对于“ url-anchor 共現”中的 P r ( e a ∣ w ) Pr(e_a|w) Pr(ea∣w),我们从锚点提及的候选列表中抽取20个否定词,并从整个实体集中抽取10个否定词。
- 为了平衡训练过程,我们给知识模型10个线程,给文本模型20个线程。 我们采用了类似(Bordes et al., 2013)的共享内存方法,且不用锁。
4.3 Comparison between Embedding-based and BoW-based Feature
![[NLP] 实体消歧论文阅读—Entity Disambiguation by Knowledge and Text Jointly Embedding_第1张图片](http://img.e-com-net.com/image/info8/3a1722495e0f4cc4af59aff98001ebe0.jpg)
剩下的实验与比较就请各位自己到原文细看了,本篇只介绍文章里模型的基本架构以及目标函数如何定义