KG-BERT for Knowledge Graph Completion 笔记
Abstract
1、采用预训练的语言模型BERT来补全知识图谱
2、将知识图谱中的三元组视为文本序列,并提出新框架KG-BERT
3、方法:用三元组的实体描述和关系描述作为输入,利用KG-BERT语言模型计算三元组的评分函数
资料查阅:
预训练语言模型 PLMs:预训练模型就意味着先学习人类的语言知识,然后再代入到某个具体任务。
1)基于大规模文本,预训练得出通用的语言表示;2)通过微调的方式,将学习到的知识传递到不同的下游任务
预训练模型的三个关键技术:①Transformer ②自监督学习 ③微调
Introduction
1、KG通常是一个多关系图,KG通常是一个多关系图,包含实体作为节点,关系作为边。
每条边都表示为一个三元组(head entity, relation, tail entity)(简称(h, r, t)),表示两个实体的关系
例如(Steve Jobs, founded, Apple Inc.)
2、知识图谱补全的任务:评估知识图中未出现的三元组的合理性
3、知识图谱补全的常用方法:
”知识图嵌入“它将三元组中的实体和关系表示为实值向量,并用这些向量评估三元组的真实性(Wang et al. 2017)
缺陷:只观察到三元组的结构信息,存在知识图谱的稀疏性问题
BERT的优势:通过掩码语言建模和下一句预测对双向Transformer编码器进行预训练,它可以在预先训练的模型权重中获取丰富的语言知识。
本研究中,提出了一种利用预先训练的语言模型来完成知识图谱的新方法:
将实体、关系和三元组看成文本序列,并将知识图谱的补全问题转化为序列分类问题,然后在这些序列上面微调BERT模型,以预测一个三元组或一个关系的可信度。
1、该文提出了一种新的语言模型用于知识图谱的补全,这是第一个用预先训练过的语言模型来进行三元组的可信性研究。
2、实验结果表明,该方法在三元组分类、关系预测和链路预测等方面取得了较好的效果。
Method
Bert:Bidirectional Encoder Representations from Transformers(一种从Transformers模型得来的双向编码表征模型。)
《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
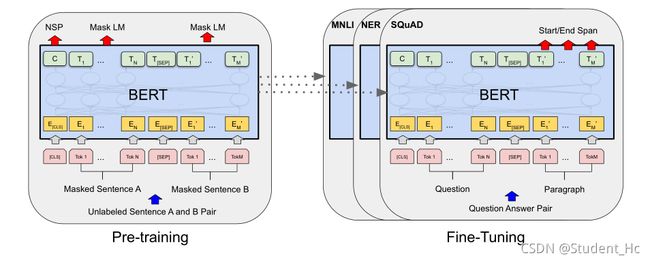
每个序列的首个token总是一个特定的classification token([CLS])。这个token对应的最后的隐藏状态被用作分类任务的聚合序列表征。SEP是分隔符,用于区分句子,如Question/Answer
Pre-training:
1、Task 1:Masked LM:为了训练一个深度双向表征,作者简单的随机mask一些百分比的输入tokens,然后预测那些被mask掉的tokens。这一步称为“masked LM”(MLM),文献中它通常被称为完型填空任务(Cloze task)。在实验中,作者为每个序列随机mask掉了15%的WordPiece tokens。
2、Task 2:Next Sentence Prediction (NSP):当为每个预测样例选择一个句子对A和B,50%的时间B是A后面的下一个句子(标记为IsNext), 50%的时间B是语料库中的一个随机句子(标记为NotNext)。图1中,C用来预测下一个句子(NSP)。
Fine-tuning:
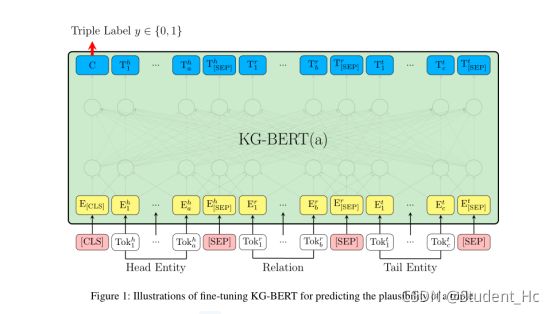
具体的做法是修改了BERT模型的输入使其适用于知识库三元组的形式。
首先是KG-BERT(a),输入为三元组( h , r , t )的形式,当然还有BERT自带的special tokens。例如,对于三元组(SteveJobs,founded,AppleInc),上图中的Head Entity输入可以表示为Steven Paul Jobs was an American business magnate, entrepreneur and investor或者Steve Jobs,而Tail Entity可以表示为Apple Inc. is an American multinational technology company headquartered in Cupertino, California或Apple Inc。也就是说,头尾实体的输入可以是实体描述句子或者实体名本身。
上述的KG-BERT(a)需要输入关系,对于预测关系任务不适用,于是作者又提出一种KG-BERT(b),如下图。
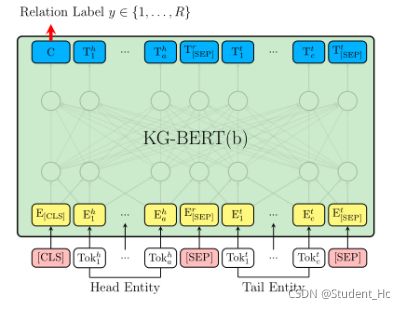
KG-BERT(b)采用CLS处的隐态输出C后接一个分类矩阵来预测两实体之间的关系:
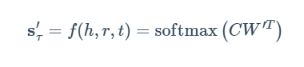
其中W为关系的分类矩阵,多分类也将sigmoid换成了softmax.
Experiments
数据集:
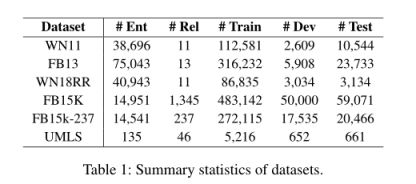
作者微调的BERT参数
fine-tuning: batch size: 32, learning rate: 5e-5, dropout rate:0.1
Epochs:
3 for triple classification,
5 for link (entity) prediction
20 for relation prediction
三元组分类(3),实体预测(5),关系预测(20)
对于关系预测,epoch越多效果越好,三元组分类和实体预测不是这样。
关于深度学习中的三个概念:
(1)iteration:表示1次迭代(也叫training step),每次迭代更新1次网络结构的参数;
(2)batch-size:1次迭代所使用的样本量;
(3)epoch:1个epoch表示过了1遍训练集中的所有样本。
三元组分类任务
不同嵌入方法的三元组分类精确度:
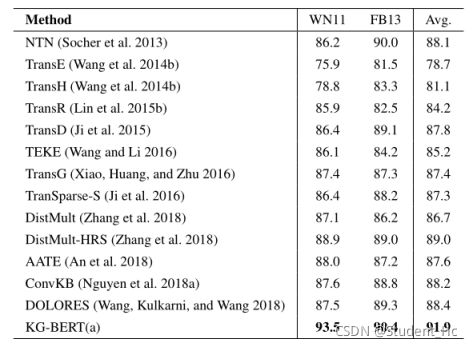
KG-BERT表现良好的原因:
1)输入序列同时包含实体词序列和关系词序列
2)三元组分类任务与BERT预训练中的下一个句子预测任务非常相似,该任务捕获了大型自由文本中两个句子之间的关系,因此预先训练的BERT权值可以很好地定位到三元组分类任务中不同元素之间的关系
3)标记隐藏向量是上下文嵌入。同一个标记可以在不同的三元组中有不同的隐藏向量,因此可以显式地使用上下文信息。
4)自注意机制可以发现与三元组事实相关的最重要的词
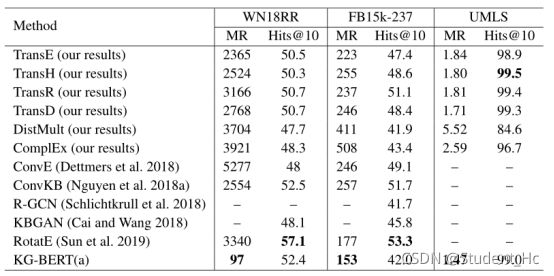
链接(实体)预测任务
预测头部实体(?,r,t)或预测给定的尾部实体(h, r,?)
(?表示缺少的元素)
关系预测任务
该任务预测两个给定实体之间的关系,即(h,?,t)这个过程类似于链接(实体)预测。
KG-BERT的注意模式

输入序列使用实体描述“一张价值20美元的美钞”和“一张纸币”以及关系名称“hypernym”。一些重要的词,如“纸”和“钱”,与标签标记[CLS]相关的注意力得分更高,而一些不太相关的词,如“联合”和“国家”,获得的关注较少。
存在的不足
BERT模型的一个主要局限性是代价昂贵,使得链路(实体)预测评估非常耗时,链路(实体)预测评估需要用几乎所有的实体替换头或尾实体。
总结
本文提出了一种新的知识图补全方法,称为知识图BERT (KG-BERT)。我们将实体和关系表示为名称/描述文本序列,并将知识图补全问题转化为序列分类问题。KG-BERT可以利用丰富的语言信息在大量的自由文本和突出最重要的单词连接到一个三元组。
总结
本文提出了一种新的知识图补全方法,称为知识图BERT (KG-BERT)。我们将实体和关系表示为名称/描述文本序列,并将知识图补全问题转化为序列分类问题。KG-BERT可以利用丰富的语言信息在大量的自由文本和突出最重要的单词连接到一个三元组。