Tensorflow 2.x 模型-部署与实践
Tensorflow 2.x 模型-部署与实践
在《基于TensorFlow Serving的YOLO模型部署》文章中有介绍tensorflow 1.x版本的模型如何利用TensorFlow Serving部署。本文接着上篇介绍tensorflow2.x版本的模型部署。
![]()
工作原理
![]()
架构图
**核心概念 **
**⑦ ServableHandler:**servable实例,用于处理client发送的请求
servable的生命周期:
● 一个Source插件会为一个特定的version创建一个Loader。该Loaders包含了在加载Servable时所需的任何元数据
● Source会使用一个callback来通知该Aspired Version的Manager
● 该Manager应用该配置过的Version Policy来决定下一个要采用的动作,它会被unload一个之前已经加载过的version,或者加载一个新的version
● 如果该Manager决定它是否安全,它会给Loader所需的资源,并告诉该Loader来加载新的version
● Clients会告知Manager,即可显式指定version,或者只请求最新的version。该Manager会为该Servable返回一个handle
![]()
Tensorflow 2.x 模型部署
![]()
TF serving环境准备
Tensorflow Serving环境最简单的安装方式是docker镜像安装。
docker pull tensorflow/sering:last
sudo apt-get install -y nvidia-docker2
docker pull tensorflow/serving:latest-devel-gpu
模型保存—savedmodel
Tensorflow 2.x模型有以下几种格式:
model.save_weights(“./xxx.ckpt” , save_format=”tf”)
model.save(“./xxx.h5”)
model.save_weights(“./xxx.h5”, save_format=”h5”)
model.save(“./xxx”, save_format=”tf”)
tf.saved_model.save(obj, “./xxx”)
model.to_json()
# coding=utf-8
import tensorflow as tf
class TestTFServing(tf.Module):
def __init__(self):
self.x = tf.Variable("hello", dtype = tf.string,trainable=True)
@tf.function(input_signature=[tf.TensorSpec(shape = [], dtype = tf.string)])
def concat_str(self, a):
self.x = self.x + a
return self.x
@tf.function(input_signature=[tf.TensorSpec(shape = [], dtype = tf.string)])
def cp_str(self, b):
self.x.assign(b)
return self.x
if __name__ == '__main__':
demo = TestTFServing()
tf.saved_model.save(demo, "model\\test\\1", signatures={"test_assign": demo.cp_str,\
"test_concat": demo.concat_str})
# coding=utf-8
import tensorflow as tf
class DenseNet(tf.keras.Model):
def __init__(self):
super(DenseNet, self).__init__()
def build(self, input_shape):
self.dense1 = tf.keras.layers.Dense(15, activation='relu')
self.dense2 = tf.keras.layers.Dense(10, activation='relu')
self.dense3 = tf.keras.layers.Dense(1, activation='sigmoid')
super(DenseNet, self).build(input_shape=input_shape)
def call(self, x):
x = self.dense1(x)
x = self.dense2(x)
x = self.dense3(x)
return x
if __name__ == '__main__':
model = DenseNet()
model.build(input_shape=(None, 15))
model.summary()
inputs = tf.random.uniform(shape=(10, 15))
model._set_inputs(inputs=inputs) # tf2.0 need add this line
model.save(".\\model\\test\\2", save_format="tf")
tf.keras.models.save_model(model, ".\\model\\test\\3", save_format="tf")
![]()
服务启动
![]()
docker run -p 8500:8500 -p 8501:8501 --mount "type=bind,source=/home/test/ybq/model/demo,target=/models/demo" -e MODEL_NAME=demo tensorflow/serving:latest
docker run -p 8500:8500 -p 8501:8501 --runtime nvidia --mount "type=bind,source=/home/test/ybq/model/demo,target=/models/demo" -e MODEL_NAME=demo tensorflow/serving:latest-gpu
![]()
Warm up 模型
![]()
由于tensorflow有些组件是懒加载模式,因此第一次请求预测会有很严重的延迟,为了降低懒加载的影响,需要在服务初始启动的时候给一些小的请求样本,为了降低懒加载的影响,需要在服务初始启动的时候给一些小的样本(tfrecord格式),调用模型的预测接口,预热模型。
WarmUp Model步骤如下所示:
# coding=utf-8
import tensorflow as tf
from tensorflow_serving.apis import model_pb2
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_log_pb2
def main():
with tf.io.TFRecordWriter("tf_serving_warmup_requests") as writer:
request = predict_pb2.PredictRequest(
model_spec=model_pb2.ModelSpec(name="demo", signature_name='serving_default'),
inputs={"x": tf.make_tensor_proto(["warm"]),
"y": tf.make_tensor_proto(["up"])}
)
log = prediction_log_pb2.PredictionLog(
predict_log=prediction_log_pb2.PredictLog(request=request))
writer.write(log.SerializeToString())
if __name__ == "__main__":
main()

900×109 68.5 KB
![]()
模型维护
![]()
默认版本维护策略是只会加载同时加载servable的一个版本,但是我们可以通过配置config,修改模型版本加载策略,也可以通过配置多个模型,同时维护多个模型。
model_config_list {
config {
name: "demo"
base_path: "/models/demo"
model_platform: "tensorflow"
model_version_policy{
specific {
versions: 1
versions: 2
}
}
}
}
docker run -p 8500:8500 -p 8501:8501 --mount "type=bind,source=/home/test/ybq/model/demo,target=/models/demo" -e MODEL_NAME=demo \
tensorflow/serving:latest \
--model_config_file=/models/demo/model.config \
--model_config_file_poll_wait_seconds=60
model_config_list {
config {
name: "demo"
base_path: "/models/model/demo"
model_platform: "tensorflow"
model_version_policy{
specific {
versions: 1
versions: 2
}
}
}
config {
name: "111"
base_path: "/models/model/111"
model_platform: "tensorflow"
model_version_policy{
specific {
versions: 1
}
}
}
}
docker run -p 8500:8500 -p 8501:8501 --mount "type=bind,source=/home/test/ybq/model/,target=/models/model" tensorflow/serving:latest \
--model_config_file=/models/model/models.config \
--model_config_file_poll_wait_seconds=60
![]()
服务调用
![]()
TF Serving提供了两种方式,一种是grpc方式(默认端口是8500),另一种是http接口调用方式(默认端口是8501)。
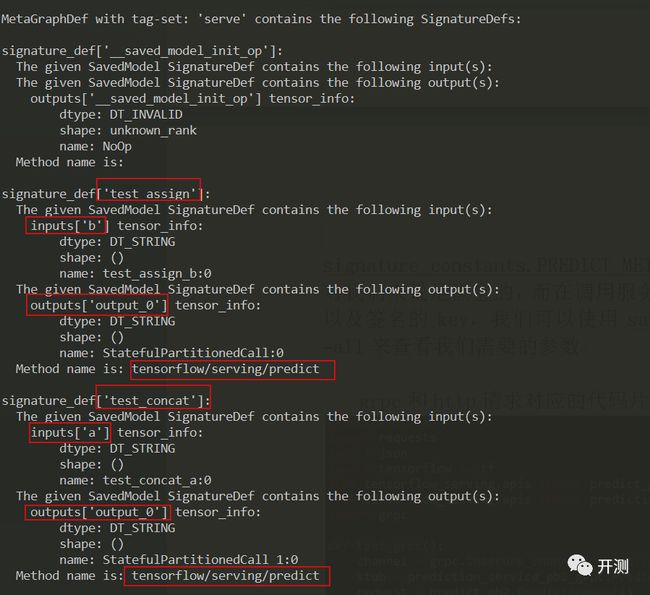
对于tensorflow2.x版本生成的saved_model模型,没有像1.x版本使用SavedModelBuilder API自定义签名(输入输出的数据类型+方法),2.x版本模型输入的数据类型可以通过@tf.function中的input_signature参数指定,方法目前来看是写死在源码中的,只有signature_constants.PREDICT_METHOD_NAME一种。很多时候模型的输入输出对我们来说是黑盒的,而在调用服务接口的时候我们需要知道模型的输入输出以及签名的key,我们可以使用saved_model_cli show --dir model/test/1 –all来查看我们需要的参数。
899×823 71 KB
grpc和http请求对应的代码片段分别如下所示:
# coding=utf-8
import requests
import json
import tensorflow as tf
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
import grpc
def test_grpc():
channel = grpc.insecure_channel('{host}:{port}'.format(host="127.0.0.1", port=8500))
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
request = predict_pb2.PredictRequest()
request.model_spec.name = "demo"
request.model_spec.signature_name = "test_concat"
request.inputs['a'].CopyFrom(tf.make_tensor_proto("xxx"))
result = stub.Predict(request, 10.0)
return result.outputs
def test_http():
params = json.dumps({"signature_name": "test_concat", "inputs": {"a": "xxx"}})
data = json.dumps(params)
rep = requests.post("http://127.0.0.1:8501/v1/models/demo/version1/:predict", data=data)
return rep.text