GPLinker:基于GlobalPointer的实体关系联合抽取
基础思路
关系抽取乍看之下是三元组(s,p,o)(即subject, predicate, object)的抽取,但落到具体实现上,它实际是“五元组”( s h s_{h} sh, s t s_{t} st,p, o h o_{h} oh, o t o_{t} ot)的抽取,其中( s h s_{h} sh, s t s_{t} st分别是s的首、尾位置,而 o h o_{h} oh, o t o_{t} ot则分别是o的首、尾位置。
从概率图的角度来看,我们可以这样构建模型:
1、设计一个五元组的打分函数S( s h s_{h} sh, s t s_{t} st,p, o h o_{h} oh, o t o_{t} ot);
2、训练时让标注的五元组S( s h s_{h} sh, s t s_{t} st,p, o h o_{h} oh, o t o_{t} ot)>0,其余五元组则S( s h s_{h} sh, s t s_{t} st,p, o h o_{h} oh, o t o_{t} ot)<0;
3、预测时枚举所有可能的五元组,输出S( s h s_{h} sh, s t s_{t} st,p, o h o_{h} oh, o t o_{t} ot)>0的部分。
问题:
直接枚举所有的五元组数目太多,假设句子长度为l,p的总数为n,即便加上 s h s_{h} sh≤ s t s_{t} st和 o h o_{h} oh≤ o t o_{t} ot的约束,所有五元组的数目也有
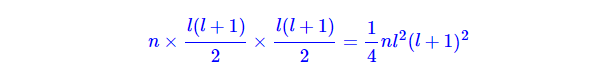
这是长度的四次方级别的计算量,实际情况下难以实现,所以必须做一些简化。
简化的思路
以我们目前的算力来看,一般最多也就能接受长度平方级别的计算量,所以我们每次顶多能识别“一对”首或尾,为此,我们可以用以下的分解:
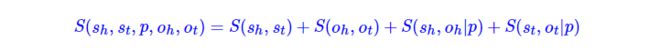
要注意的是,该等式属于模型假设,是基于我们对任务的理解以及算力的限制所设计出来的,而不是理论推导出来的。
其中S( s h s_{h} sh, s t s_{t} st)、S( o h o_{h} oh, o t o_{t} ot)分别是subject、object的首尾打分,通过S( s h s_{h} sh, s t s_{t} st)>0和S( o h o_{h} oh, o t o_{t} ot)>0来析出所有的subject和object。
后两项,则是predicate的匹配,S( s h s_{h} sh, o h o_{h} oh|p)这一项代表以subject和object的首特征作为它们自身的表征来进行一次匹配,如果我们能确保subject内和object内是没有嵌套实体的,那么理论上S( s h s_{h} sh, o h o_{h} oh|p)>0就足够析出所有的predicate了
但考虑到存在嵌套实体的可能,所以我们还要对实体的尾再进行一次匹配,即S( s t s_{t} st, o t o_{t} ot|p)这一项。
训练和预测过程
1、训练时让标注的五元组S( s h s_{h} sh, s t s_{t} st)>0、S( o h o_{h} oh, o t o_{t} ot)>0、S( s h s_{h} sh, o h o_{h} oh|p)>0、S( s t s_{t} st, o t o_{t} ot|p)>0,其余五元组则S( s h s_{h} sh, s t s_{t} st)<0、S( o h o_{h} oh, o t o_{t} ot)<0、S( s h s_{h} sh, o h o_{h} oh|p)<0、S( s t s_{t} st, o t o_{t} ot|p)<0;
2、预测时枚举所有可能的五元组,逐次输出S( s h s_{h} sh, s t s_{t} st)>0、S( o h o_{h} oh, o t o_{t} ot)>0、S( s h s_{h} sh, o h o_{h} oh|p)>0、S( s t s_{t} st, o t o_{t} ot|p)>0的部分,然后取它们的交集作为最终的输出(即同时满足4个条件)。
具体实现
由于S( s h s_{h} sh, s t s_{t} st)、S( o h o_{h} oh, o t o_{t} ot)是用来识别subject、object对应的实体的,它相当于有两种实体类型的NER任务,所以我们可以用一个GlobalPointer来完成
至于S( s h s_{h} sh, o h o_{h} oh|p),它是用来识别predicate为p的( s h s_{h} sh, o h o_{h} oh)对,跟NER不同的是,它这里不需要sh≤oh的约束,这里我们同样用GlobalPointer来完成,但为了识别出sh>oh的部分,要去掉GlobalPointer默认的下三角mask;
为什么可以用GlobalPointer
GlobalPointer理解为一个token-pair的识别模型
TPLinker与GPLinker的区别
- TPLinker的token-pair分类特征是首尾特征后拼接做Dense变换得到的,其思想来源于Additive Attention;GPLinker则是用GlobalPointer实现,其思想来源于Scaled Dot-Product Attention。平均来说,后者拥有更少的显存占用和更快的计算速度。
- GPLinker分开识别subject和object的实体,而TPLinker将subject和object混合起来统一识别。笔者也在GPLinker中尝试了混合识别,发现最终效果跟分开识别没有明显区别。
- 在S(sh,oh|p)和S(st,ot|p),TPLinker将其转化为了l(l+1)/2个3分类问题,这会有明显的类别不平衡问题;而GPLinker用到了笔者提出的多标签交叉熵,则不会存在不平衡问题,更容易训练。事实上后来TPLinker也意识到了这个问题,并提出了TPLinker-plus,其中也用到了该多标签交叉熵。
对输入文本 S={w1,w2,…,wn} 的编码向量以【token-pair】标记方式建模 n×n 大小的词元矩阵,进而做实体识别、实体关系抽取任务。