【论文笔记】-- Visual Place Recognition:A Survey
Visual Place Recognition:A Survey
- 1. 原理图
- 2. A place 是什么?
- 3. Image processing 模块
- 4. mapping 模块
- 5. belief generation 模块
- 6. 在动态环境下的视觉 place recognition
-
- A. 描述 place
- B. 记住 place
- C. 识别 place
- 7. 总结
1. 原理图
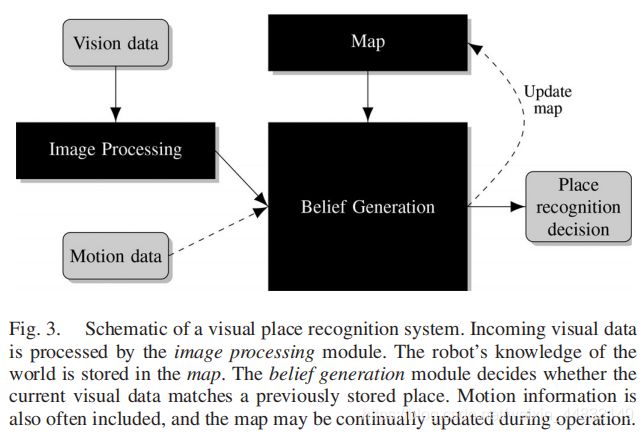
- image processing: 输入图像,输出视觉信息。用于描述place。
- map: 表示place,记住place,用于与当前观测作比较。有metric / topological。
- belief generation:将当前信息与之前的作比较,决策。
2. A place 是什么?
定性地说,
1)基于机器人的具体导航环境。A place可以是,
- a precise position—“a place describes part of the environment as a zero-dimensional point”.
- a larger area—“a place may also be defined as the abstraction of a region” where a region “represents a two-dimensional subset of the environment”.
- a 3-D area.
2)基于时间密度或者空间密度来确定一个place,比如机器人每运行一段时间,或每运行一段距离,确定一个place。
3)基于外观的差异来确定place。即,appearance-based
定量地确定topological place,即拓扑地图上的节点,
1)change-point detection algorithms,有关算法:Bayesian surprise and segmented regression
2)image sequencing partitioning techniques
...还有很多
基于密度、外观的方法在实际中都很实用。
面临的challenge ,
1)基于外观的方法可以和语义信息相结合,从而改善外观信息。
2)借助语义信息,place recognition 和 object recognition 可以相互促进。
3. Image processing 模块
该模块作用是,描述place。描述方法大概分成两类,

1)Local Feature Descriptors
def. detection + description
BoW模型
- 将特征空间分割成有限数量的单词,这些单词组成 vocabulary / dictionary。
- 一张图像 = a vector of visual words。
- 图像比较时,可采用 Hamming distance or histogram comparison techniques。
- 大场景,采用 vocabulary tree 更高效。
- 配合 inverted index ,更高效。
采用BoW描述时,忽略了place的几何结构信息,因此描述是 pose invariant,即 the place can be recognized regardless of the position of the robot within the place。因此,给 place 添加几何信息,可以增加 place matching 时的鲁棒性。
比如,添加,
- 3-D information using laser sensor
- use stereo vision
- epipolar constraints
- the position of the elements within the image
BoW面临的挑战,
- pose invariance 和 condition invariance 之间的折衷。
- pose invariance:recognizing places regardless of the robot orientation
- condition invariance:recognizing places when the visual appearance changes
- 如何在线更新vocabulary。
2)Global Descriptors
不是 global feature,
3)Describing Places Using Local and Global Techniques
两者各有优劣,可相互结合。
- 局部特征法可以结合度量信息,来校正定位。
- 全局描述对机器人位姿敏感。
- 局部特征子可以重组,生成未见过的place。
- 局部特征法对环境条件变化敏感,但全局描述法可胜任。
Using global descriptors on image segments rather than whole images may provide a compromise between the two approaches, as sufficiently large image segments exhibit some of the condition invariance of whole images, and sufficiently small image segments exhibit the pose invariance of local features.
4)Including Three-Dimensional Information in Place Descriptions
1)、2)、3)的描述法都是 appearance based,都只是在视觉域上对图像数据建模,而非生成一个完整的几何模型。若要应用到度量定位系统(metric localization systems),则必须包含度量信息,比如像素的深度信息。而度量信息又可分为稠密和稀疏两种,比如 DTAM 和 ORB-SLAM。
4. mapping 模块
该模块的作用是,表示place,记住place,并用于与当前观测相比较。mapping framework取决于两点,获取的数据和所执行的 place recognition 的类型。图1为建图的方法分类。

1)纯图像检索
- 最抽象的 mapping framework,只存储 place 的外观信息而无位置信息。
- 仅基于外观的相似性来匹配 place。
- 大部分研究聚焦于检索的效率。
- BoW + inverted index 是重要手段。
If a bag-of-words model is used to quantize the descriptor space, image retrieval can be accelerated using inverted indices; the image ID numbers are stored against the words that appear in the image, rather than the words being stored against the image IDs. Inverted indices allow quicker elimination of unlikely images, rather than requiring a linear search of all images in the database.
- hierarchical vocabulary tree 也可提高检索效率。
- hierarchical searching
注:纯图像检索对应着 loop closure detection 中的 image-to-image 法,也即基于外观法的回环检测,appearance based loop closure detection。
2)拓扑地图
拓扑地图包含 places 之间的相对位置信息,但不含关联这些 places 的度量信息。
- 拓扑信息可以增加正确的 place 匹配,并过滤错误的匹配。
- 拓扑地图可以用定位先验来加速匹配。
- 在回环检测中,利用拓扑信息,将 place recognition 作为 a sparse convex L1 -minimization problem 来解决。
- 基于拓扑信息的 place recognition,可使用低分辨率的图像,因此降低内存需要。
注:回环检测时,采用 image-to-image 法。
3)拓扑-度量地图
给拓扑地图的边添加度量信息——距离、方向,可使其改善。比如,FAB-MAP→CAT-SLAM Seq-SLAM→SMART。
- 度量信息可以添加给边,如位姿变换,但 place 描述仍属于 appearance-based。
- 可以添加给节点,如像素的深度信息,则节点(place)变为路标点,或稠密地图中的栅格。
注:后者中,在 loop closure detection 时,既可采用 image-to-map 方法,也可采用 image-to-image。
5. belief generation 模块
该模块作用是,决策。判断当前 place 是否在之前见过。定量地说,一个 place recognition system 的中心目标就是使视觉输入与所存储的地图数据相协调,以生成一个 belief 分布。该分布提供了一个关于当前输入与 map 所储存的 place 相匹配的置信度 / 概率。
通常,两个 place description 越相似,那么概率就越大,则认为当前 place 为先前所见。但是实际应用中,面临两个挑战,
- perceptual aliasing,感知混叠,即不同的 place,因包含相似的环境要素,被认为是相同的 place。
- changing conditions,即变化的环境条件使得同一 place 发生巨大变化,从而被认为是不同的place。
1)Place recognition 与 SLAM
- 在SLAM 的位姿图优化中,place recognition 可以提供 loop closure candidates。
- 有 Place recognition 系统可执行类似 SLAM 的 local metric correction。
- 包含度量信息的 place recognition maps 可用于执行 metric SLAM。
因此,Place recognition 在 SLAM 中相当于 loop closure detection。
2)Topological Place Recognition
- 采用投票机制,生成一个置信度(如,confident, uncertain, or confused),来确定当前 place 是否为先前所见。
- 基于BoW,给 word 一个 TF-IDF分数。term frequency × inverse document frequency。
- 基于 Bayes theorem 计算 place 匹配的概率。
- Monte Carlo localization
- 用 data-driven approach 计算 observational likelihood。如 FAB-MAP
FAB-MAP
- 使用 SIFT / SURF 的 BoW描述图像,并在训练时计算每个 word 的独特性。
- 被观测到的 word 的 the full joint probability distribution 采用 a naive Bayes assumption or a Chow–Liu tree来估计。
- 判断是否为同一 place 时,不仅考虑共同的 word,还要考虑共有的 word 是否稀缺,从而处理 perceptual aliasing 问题。
- 计算 a pairwise consistency matrix between possible hypotheses,消除假阳匹配。
- Biologically inspired methods,RatSLAM。
3)Evaluation of Place Recognition Systems
- 采用两个指标,precision 和 recall。
- 通常,基于100% reccall 的 precision 为最重要的度量指标。
- 存在方法,使用拓扑信息来消除假阳匹配。
- 先找到许多潜在 place 匹配,再校正。也逐渐流行,尤其针对 changing condition 。
- 考虑 place matches 空间分布的度量标准。
6. 在动态环境下的视觉 place recognition
采用与上述相同的流程,描述→记住→识别。
A. 描述 place
针对光照和天气的变化,大致有两种描述法。一,condition-invariant description of the place,设计 scale-, rotation-, and illumination-invariant 的局部特征描述子。二,学习外观如何变化的。
1)Invariant Methods
- U-SIFT 有 lighting invariance,然后 U-SURF ?
- Whole-image descriptors,如 SeqSLAM,但是环境变化太大,容易失效,且对 viewpoint change 敏感。
- Edge features,they are invariant to lighting, orientation and scale,但是基于边特征的 data association 有困难。
- shadow removal, illumination invariant color space
- hardware-based solution,比如 scanning laser-rangefinders,long-wave infrared thermal imaging camera, thermal imaging cameras
- 结合CNNs学习特征
- 深入挖掘图像的颜色信息,尤其是相对颜色信息。(注,当前许多流行的描述法都是针对灰度图像的,如SURF, BRIEF)
2) Learning Methods:学习不同时间下,变化的 places 之间的关系。
- 该方法假设 place 的变化是规律重复的,因此训练时,学习到的变化具备泛化能力。
- 存在方法,学习一个精确的 vocabulary。
The motivation for the fine vocabulary is the observation that descriptors transform in a highly non-linear way due to illumination change, changing viewpoint, and other effects, and learning a distribution of alternative words allows these changes to be learned and quantified.
- neural network learning technique
- 学习不同季节下,视觉的变化。
- 有监督 / 无监督
B. 记住 place
为了建立在动态环境下的 map,有两种方法,第一,选择性地记住并忘记一些数据(环境要素),第二,建立多种 map 表示,从而记住不同条件下的 place。
1)Remembering and Forgetting Data
challenge
难以决定哪些要素是短暂的,应该被忘记,而哪些要素应该被记住。-- stability-plasticity dilemma
solution
Concepts such as sensory memory, short-term memory, and long-term memory found in human memory models have been coopted to create decision models for remembering and forgetting.
- 受生物启发的建图系统,通过感觉记忆的类似物,将传感器信息传递到短期记忆和长期记忆存储区域。
- 使用 BoW 模型并采用 a quality measure 以决定有用的特征被保留。
2)Multiple Representations of the Environment
- solution 1 – 添加 timescale
- 对同一环境采用多个 map 时,对每个 map 编码一个时间尺度 timescale。
- 其中,一些 map 表示短期记忆并频繁更新,而一些 map 代表长期记忆并很少更新。
- 于是,保持不同时间尺度下的地图更新,以确保旧的 map 数据不会被短暂的动态变化覆盖。
- 相反,静态元素长时间保持不变,而过滤掉短暂元素。
- 最终,在执行 place recognition 时,选择符合当前数据的 map。
- solution 2 – 添加 map configuration
- solution 3 – 使用 submaps,隔离动态区域
Using submaps to segregate dynamic areas allowed multiple environmental configurations where necessary while keeping the map manageable.
- solution 4 – feature cooccurrence maps
- solution 5 – learn scene signatures
scene signatures —— locally distinctive elements of a place that are also stable over changes in appearance.
- solution 6 – 针对环境外观受周期性因素影响,谱分析 ,如傅里叶分析,可用于预测未来某个时间的外观变化
以上,都基于一个前提假设:机器人知道哪一个位置足以将同一位置的不同表示匹配在一起,即使这些表示在视觉上是不同的。 如果系统不知道要更新哪个位置,并且在不断变化的环境中,可能无法确切知道机器人的位置,则无法更新地图。
为避免上述假设,
proposed a plastic map formulation that explicitly localizes within robot “experiences” rather than physical locations.
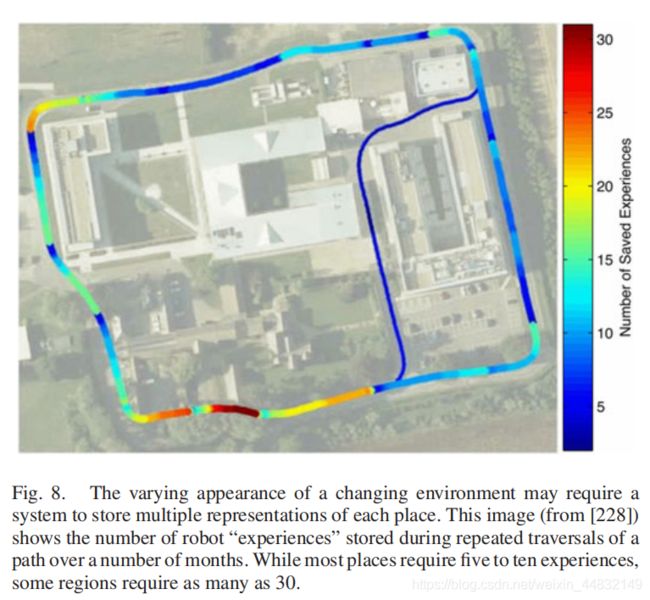
每当机器人无法识别出一个地点,那么就生成一个experience,那么同一地点,map 就存在多种表示。如下图,不同颜色代表着不同 experience 的数量
C. 识别 place
-
因为上述中,存在多种 place 的表示,即多个 map,那么在识别时,系统应根据当前的数据,选择最合适的 map,预测出最有可能的 place matches。
-
或者,系统同时执行多个 map hypotheses。
-
匹配 image sequences 而非单张 image 可以改善 place recognition,如SeqSLAM。
7. 总结
we are still a long way from a universal place recognition system for robots that is robust and widely applicable across a range of robotic platforms and varying environments. Here, we highlight several promising avenues of ongoing and future research that are moving us closer toward this outcome.
1)结合 deep learning, image classification, object recognition, video description,GPU hardware
2)结合 object detection, scene classification
- 结合 object detection。可检测出楼房,可帮助 long-term place recognition;可检测出行人,应被忽略;可检测出车,给 place recognition 提供线索。
An increased robustness to structural changes can be achieved by exploiting knowledge about which objects are dynamic or static and how that property depends on the temporal and semantic context—for example, cars in a parking garage can temporarily provide useful place recognition cues.
- 未来研究可聚焦于 CNNs 的表达能力,以辅助 place recognition。
3)结合 context,即探究 place 潜在的环境要素。
- places 之间的位置关系
- knowledge about the time of day, or the current weather conditions
- …
4)结合 Semantic scene context,即场景的语义信息。