【论文阅读】Siamese Neural Networks for One-shot Image Recognition
关键词:
- one-short learning : 待解决的问题只有少量的标注数据,先验知识很匮乏,迁移学习就属于one-short learning的一种
- zero-short learning: 这个种情况下完全没有标注数据,聚类算法等无监督学习就属于zero-short learning的一种。
论文主要内容:
- 训练卷积孪生网络训练模型做图片验证,详细介绍了如何使用Omniglot数据集训练的过程
- 说明的模型的效果,与当前主流的方法作比较,也很不错
- 对未训练的数据集直接做测试,模型也不错(这里是不是提醒人们进一步去做迁移学习呢?)
人在接触和认知新模式时有很强的能力。机器学习虽然很成功,当遇到标记信息时非常少时,往往会失败。在新分类中扩展训练的成本是非常昂贵的,我们期望模型可以不经过扩展训练直接适应新的分类。
比如只有少量标注数据做分类的任务,这个就很有意思,被称为one-shot learning。于此对应的zero-short learning则是限制不允许有标记的训练数据。
One-short learning 通过学习特定领域的特征或者可以生成可区分属性的推测器,解决目标任务。这种方法在处理相似实例时表现优异,但是在解决其他的问题时通常是失败的。我们提出了一个新的方法,不在限制输入数据的结构,也成功的对只有很少样例进行建模。这种方法使用了深度学习技术,堆积很非多分线性层,使用了包含巨多参数的模型,同时要使用很多数据防止过拟合,学习参数时不需要很强的先验只是,当然学习算法的代价也需要考虑的。
1、方法
通过孪生网络学图片特征,然后在不重新学习直接复用网络输出的特征。
实验室将问题限制在字符识别领域,这不影响扩展到其他范围。我们开发了大的孪生卷积网络,它可以:
- 学习到一些通用的图片特征,可以预测数据非常少的新分类
- 在数据源上进行随机采样生成成对的训练数据,然后使用标准的优化算法进行训练
- 这种方法不依赖特定领域知识,只依赖深度学习
在开发一个之后很少训练数据的图片分类模型,需要学习一个区分不同分类的图片对,这是一个标准图片验证任务(verification task)。能够处理verification task的模型能够很好的繁华到one –shot classification。如果在verification task中得分很高,在one shot task得分也会很高
2、类似的研究
李飞飞使用贝叶斯框架研究one-shot task。2013有HBPL解决此类问题,难度非常大。。。。
有些研究人员在尝试其他的方法,例如结合生成式隐马尔库模型和贝叶斯推断识别未知演讲者的新词。
3、用于图像验证的深度孪生网络(Deep Siamese Networks for Image Verification)
1990s, Bromley 和 LeCun使用孪生网络处理签名验证任务。孪生网络使用两个相同的网络,接收不同输出,网络间共享参数。共享参数能够保证相似图片的特征值不会相差很多。同时也能保证输入不同的图片时,执行的相同的度量计算从而保证输出特征的可比性。
LeCun使用的Contrastive loss Function,包括两项,相同对降低loss,不同对增加loss。作者使用计算两张图特征的带权重的L1距离 + simoid激活函数,输出值映射到[0,1]范围,这个参照了FaceBook的DeepFace论文。
效果最好的模型使用多个卷积层+ 全连层+损失函数的设计。
3.1 网络结构
前两层使用ReLU激活函数,其余的使用sigmoid单元。卷积层的filters尺寸可变,stide固定为1,。为了方便优化滤波器的数量的是16的倍数,然后使用ReLU激活函数,然后选择性的使用max-pooling,stride为2.
网络结构如下:
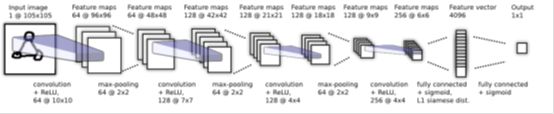
没有描述孪生网络的另一部分。实际使用时,在全连层之后会对两张图片的各自4096维特征计算L1距离,输出的公式是:
![]()
最后一层在学习的特征中输出一个度量值,用以表示两个特征的相似度。
其中阿尔法J是模型学习到的权重参数,表示元素距离的重要性。
3.2 学习
损失函数
使用带有正则化的二元分类交叉熵函数:

最优化
Minbatch size =128
参数优化过程:
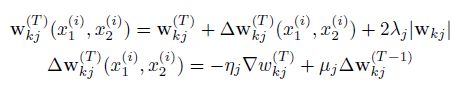
偏导数 学习速率 是L2正则化权重 动量
![]() 偏导数
偏导数 ![]() 学习速率
学习速率 ![]() 是L2正则化权重
是L2正则化权重 ![]() 动量
动量
权重初始化
卷积层使用均值为0,标准差0.01的正态分布初始化权重参数,使用均值为0.5,标准差为0.01正态分布初始化bias。
全连层的bias初始化方法和卷积层一样,权重的初始化均值为0,标准差为0.02,比卷积层更宽泛。
学习模式
一个epoch学习速率下降0.01,即
![]()
学习速率的退化(或者叫退火)有益于模型收敛到局部最小值,不会卡在误差表面。
动量值初始化为0.5,每个epoch线性增加这个值,直到到达每个层分别设置动量值
每个网络训练200 epoch,在验证集中随机抽取320个图片检测error值。当erro值连续20个epoch没有下降时,停止训练,选用error值最小的model。如果整个训练过程,error值不断下降,我们使用最后的model。
超参数的最优化:
使用贝叶斯最优化框架Whetlab,用的beta版本。学习速率范围[0.0001, 0.1],每个层的动量范围是[0,1],L2正则化惩罚项范围[0, 0.1]。卷积核的大小在3x3到20x20的范围内变化,卷积核的数目是16的倍数,从16到256。全连层输出从128到4096。超参数优化的标准是最大化验证集的准确率。
Affine distortions 仿射扭曲
数据增强使用仿射扭曲。对于每个训练对(x1, x2)使用相同的仿射变换参数生成对应的新对(x1’, x2’),反射。
4 实验
4.1 数据集
在Omniglot数据集则子集上训练模型。Omniglot数据集包括了50的字母表,既包括诸如拉丁,韩语一类的国际语言也包括一些土语。每个字母表中字母数量从15到40不等。所有的字母表的字符是20个人画出来的。包含字母数量约为50个字母表*每个字母表按30个字母算*20个人 = 3w。
数据集被分成40个字母表的Background Set和10的字母表的Evaluation Set。数据分成两部分是为了区分正常训练,验证和测试的model训练方法。Background set用训练模型学习超参数和特征映射关系, Evaluation Set用于验证使用少量数据进行one-shot classification的能力。
4.2 verification 验证网络训练
为了训练验证网络,随机抽样相同和不同的pairs,生成三个不同规模的数据集,分别是3w, 9w和15w。我们使用总数据的60%进行训练,50个字母表中30个, 20个drawer中的12个。
每个字母表中用来训练数量是固定的,保证每个字母表在优化的过程中能够获得等同的表征,但是不能保证每个字母都能公平对待。每个训练样本经过仿射扭曲后生成8个新的样例,数据集规模变成27w, 81w和135w。
为验证性能,从额外的10个字母表和4个drawer抽取了1w pairs。10个字母表和4个drawer的剩余pairs用于测试,这部分和Omniglot数据集的测试数据是一样的,方便进行横向对比。 用于验证性能的另一类策略是使用相同的字母表和drawer生成一组320个识别实验,模拟Evaluation Set上的目标任务。在实际训练过程中,第二组策略用于停止训练的标准,即在最少训练次数时达到最低的验证loss。
在下表中,我们列出了六种可能的培训集中的每一种的最终验证结果,其中列出的测试准确度在最佳验证检查点和阈值处报告。 我们报告六种不同训练运行的结果,改变训练集大小和切换扭曲。

图7中,我们抽取性能Top2模型的前32个滤波器(9w和15w训练集,经过仿射扭曲数据扩展训练获得),可以看到滤波器之间有相似适应性,但是在输入空间中承担的不同的角色
4.3 one-shot learning
经过优化后获得孪生网络的优化模型,开始验证学到特征在one-short learning任务中辨识的潜力了。
为了凭经验评估one-shot learning的性能,Lake开发了一种20-way的字母表内的分类任务,首先从为评估集保留的字母表中选择一个字母表,在该字母表中随机均匀地采集20个字符。二十个drawers中的也选择两个。这样每个drawer都花了了二十个字符的样本。由第一drawer产生的每个字符被表示为测试图像并且分别与来自第二抽屉的所有二十个字符进行比较,目的是从所有第二抽屉的字符中预测与测试图像对应的类。对于所有字母表,该过程重复两次,因此对于每个评估字母表,都有40个one shot learning 实验。这构成了总共400次一次性学习试验,从中计算分类准确度,结果如下表:
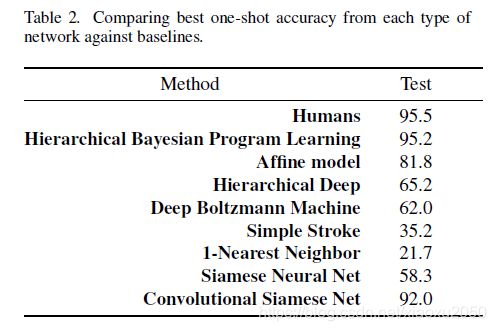
列表中还包含一个只包括两个全连层的非卷积神经网络。我们卷积模型达到92%的准确率,比HBPL差点。但是我们的模型没有关于字符和笔画的任何先验知识,这是模型的主要优势。
4.4 MNIST one short Trial
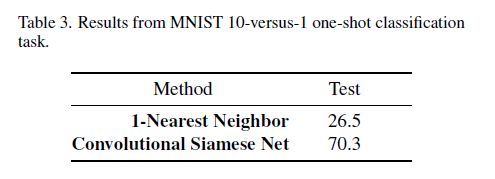
Omniglot数据被成功MNIST的变换,因为Omniglot数据集的分类数量远多于每个分类的图片数量。那如果直接使用Omniglot数据集上的训练模型测试MNIST的分类效果会怎么样呢,作者列出了与NN算法的比较:
5、结论
- 提出一种首先学习卷积孪生网络模型的one-short classification的方法,在Onniglot数据训练模型,其性能超过绝大的基线,仅比最好的方法稍差,很接近人类的准确率。并且可以扩展到其他的领域的one-short learning。
- 作者使用affine distortion做数据扩展,现在正在试验对字体的笔画做独立仿射变换,然后叠加的一个合成图中,由此来模仿一些常见变化。