【图像盲超】Learning the Degradation Distribution for Blind Image Super-Resolution(CVPR2022)学习盲图像超分辨率的退化分布
DAN的原作者,中科院自动化所的团队。
文章中心思想:通过建模一个随机退化模型,让HR随机退化到LR图像。LR图像与测试的real图像做GAN来区分是否是一个域的分布(对抗损失),如果不是,则返回重新生成LR图像,如果是,则进入SR model去生成SR图像(L1损失)。一句话:通过学习怎么生成真实图像的分布,合成大量的符合真实图像分布的训练样本。从而在测试真实图像时能够有很好的效果。

摘要
合成高分辨率 (HR) 和低分辨率 (LR) 对广泛用于现有的超分辨率 (SR) 方法。为了避免合成图像和测试图像之间的域差距,大多数以前的方法都试图通过确定性模型自适应地学习合成(降级)过程。然而,真实场景中的一些退化是随机的,不能由图像的内容来确定。这些确定性模型可能无法对随机因素和与内容无关的退化部分进行建模,这将限制以下 SR 模型的性能。在本文中,我们提出了一种概率退化模型(PDM),它将退化 D 作为随机变量进行研究,并通过对从先验随机变量 z 到 D 的映射进行建模来学习其分布。与之前的确定性退化模型相比,PDM 可以建模更多样化的退化并生成可以更好地覆盖测试图像的各种退化的 HR-LR 对,从而防止 SR 模型过度拟合特定的退化。大量实验表明,我们的退化模型可以帮助 SR 模型在不同的数据集上实现更好的性能。
介绍
之前大多数基于退化学习的 SR 方法都有一个共同的缺点:它们的退化模型是确定性的,每张 HR 图像只能退化为某个 LR 图像。它暗示了一个假设:退化完全取决于图像的内容。一些降级与内容无关且是随机的,例如由 相机的随机抖动引起的随机噪声或模糊。这些确定性模型无法很好地模拟这些随机因素和与内容无关的退化部分。一个更好的假设是退化受分布的影响,这可以通过概率模型更好地建模。
学习退化分布
退化过程可以用以下公式表示

过程图如下:

直觉上,模糊核和噪声这两个步骤是相互独立的,因为模糊核主要取决于相机镜头的属性,而噪声主要与传感器的属性有关。因此,退化分布可以建模为:
![]()
核模型设计
为了对模糊核 ![]() 的分布进行建模,我们定义了一个服从多维正态分布的先验随机变量
的分布进行建模,我们定义了一个服从多维正态分布的先验随机变量  。然后我们使用生成模块来学习从 到
。然后我们使用生成模块来学习从 到 ![]() 的映射(表示随机模糊,
的映射(表示随机模糊,![]() 表示拟合的目标模糊核):
表示拟合的目标模糊核):
![]()
其中 ![]() 是由卷积神经网络表示的生成模块。
是由卷积神经网络表示的生成模块。
【我们首先考虑空间变化的模糊核,即 ![]() 的每个像素的模糊核是不同的。】个人认为意思是每个像素的模糊程度是不一样的,比如
的每个像素的模糊核是不同的。】个人认为意思是每个像素的模糊程度是不一样的,比如 的模糊程度是1,
的模糊程度是1,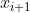 的模糊程度是3。这种情况下有:
的模糊程度是3。这种情况下有:
![]()
其中 ![]() 是正态分布 的维度,
是正态分布 的维度, 是模糊核的大小,
是模糊核的大小, 和
和  分别是
分别是 ![]() 的高度和宽度。我们在最后添加了一个 Sof tmax 层 [2] 以保证 的所有元素总和为 1。一般来说,
的高度和宽度。我们在最后添加了一个 Sof tmax 层 [2] 以保证 的所有元素总和为 1。一般来说,![]() 中卷积权重的大小设置为3×3,这表明学习到的模糊核是空间相关的,Ps:即3x3宽度的像素模糊核有相关性。否则,如果将所有卷积权重的空间大小设置为 1 × 1,则每个像素的模糊核都是独立学习的。
中卷积权重的大小设置为3×3,这表明学习到的模糊核是空间相关的,Ps:即3x3宽度的像素模糊核有相关性。否则,如果将所有卷积权重的空间大小设置为 1 × 1,则每个像素的模糊核都是独立学习的。
模糊核的空间差异通常是由镜头畸变引起的,主要出现在图像的角落附近。在大多数情况下,模糊核可以近似为空间不变的核,这是空间异变模糊核的一个特例, = = 1。我们有:
![]()
这种近似对于大多数数据集来说已经足够好了。 这两段没太看得懂QAQ
噪声模型设计
退化的第二步是向模糊和缩小的图像 ![]() 添加噪声。大多数以前的退化模型只考虑 AWGN(加性高斯白噪声),它与
添加噪声。大多数以前的退化模型只考虑 AWGN(加性高斯白噪声),它与 ![]() 的内容无关,Ps:即同一种噪声,加在任何图像上都是同一种效果。在这种情况下,噪声
的内容无关,Ps:即同一种噪声,加在任何图像上都是同一种效果。在这种情况下,噪声 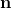 的分布也可以用一个普通的生成模块来表示(
的分布也可以用一个普通的生成模块来表示( 表示随机噪声,符合正太分布, 是拟合的目标噪声):
表示随机噪声,符合正太分布, 是拟合的目标噪声):
![]()
同样![]() 表示的也是卷积神经网络,在噪声域:
表示的也是卷积神经网络,在噪声域:
![]()
其中 ![]() 是正态分布 的维数。在其他方法中,原始空间
是正态分布 的维数。在其他方法中,原始空间 ![]() 中的噪声被建模为散粒噪声和读取噪声的组合。并且
中的噪声被建模为散粒噪声和读取噪声的组合。并且 ![]() 可以近似为异方差高斯分布(不懂这是个啥) :
可以近似为异方差高斯分布(不懂这是个啥) :
![]()
其中 ![]() 和
和 ![]() 由相机传感器的模拟和数字增益决定(read为加性噪声,shot为噪声系数?百度的:模拟增益,就是靠放慢快门和开大光圈来实现,数字增益,就是在拍摄过程中通过运算来提亮画面,会造成颗粒增加,画面模糊)。由于 来源于
由相机传感器的模拟和数字增益决定(read为加性噪声,shot为噪声系数?百度的:模拟增益,就是靠放慢快门和开大光圈来实现,数字增益,就是在拍摄过程中通过运算来提亮画面,会造成颗粒增加,画面模糊)。由于 来源于![]() ,说明 也与图像内容有关, 的分布应该用一个条件生成模块表示:
,说明 也与图像内容有关, 的分布应该用一个条件生成模块表示:
![]()
因此,我们还可以调整 ![]() 中卷积权重的大小,以确定噪声是否在空间上相关。
中卷积权重的大小,以确定噪声是否在空间上相关。
概率退化模型(PDM)(模糊模型+噪声模型)
上面讨论的内核模块和噪声模块共同构成了我们的概率退化模型 (PDM),如图 2 所示。PDM 可用于合成 HR-LR 对:

其中 ![]() 是参考 HR 图像,{
是参考 HR 图像,{![]() ,
, ![]() } 形成 SR 模型的配对训练样本。
} 形成 SR 模型的配对训练样本。
我们的 PDM 通过对抗训练进行了优化,这鼓励 ![]() 与测试图像
与测试图像 ![]() 相似。此外,我们假设噪声 的均值为零。因此,除了对抗性损失
相似。此外,我们假设噪声 的均值为零。因此,除了对抗性损失 ![]() ,我们添加了一个关于噪声 的额外正则化器:
,我们添加了一个关于噪声 的额外正则化器:
![]()
那么退化模型的总损失函数为:
![]()
其中  是正则项的权重。在我们所有的实验中,我们设置 = 100 来平衡两个损失的大小。
是正则项的权重。在我们所有的实验中,我们设置 = 100 来平衡两个损失的大小。
与以往的退化模型相比,PDM 具有三个优势:
首先,PDM 能够模拟更多样化的退化。它允许将一张 HR 图像降级为多张 LR 图像。因此,在相同数量的 HR 图像下,PDM 可以生成更多样化的 LR 图像,并为 SR 模型提供更多的训练样本,这可能更好地覆盖测试图像的退化。因此,PDM 可以弥合训练和测试数据集之间的差距,并帮助 SR 模型在测试图像上表现更好。
其次,关于退化的先验知识可以很容易地融入 PDM,这可能会鼓励它更好地学习退化。例如,如果我们观察到单个图像中的模糊几乎是均匀的,那么我们可以调整 ![]() 和
和 ![]() 的形状,仅学习空间不变的模糊核。这种先验知识有助于减少 PDM 的学习空间,并可能鼓励使其更容易被训练。
的形状,仅学习空间不变的模糊核。这种先验知识有助于减少 PDM 的学习空间,并可能鼓励使其更容易被训练。
最后,PDM 将退化过程表述为一个线性函数,学习到的退化只能对图像内容施加有限的影响。通过这种方式,它可以更好地将退化与图像内容解耦(即拆开单独分析),并可以专注于学习退化。在大多数以前的方法中,为了确保 ![]() ,与
,与![]() 具有一致的内容,
具有一致的内容,![]() 通常由双三次下采样(来进行退化)引导 。但是,这种退化引导可能不合适,尤其是在测试图像严重模糊时。相反,在我们的 PDM 中,由于受到良好约束的模糊内核和噪声,
通常由双三次下采样(来进行退化)引导 。但是,这种退化引导可能不合适,尤其是在测试图像严重模糊时。相反,在我们的 PDM 中,由于受到良好约束的模糊内核和噪声, ![]() 的内容本质上与
的内容本质上与 ![]() 一致。因此,PDM 可以避免额外引导的限制,并专注于学习降级。
一致。因此,PDM 可以避免额外引导的限制,并专注于学习降级。
盲SR 的统一框架
在Unsupervised Real-World Super-Resolution: A Domain Adaptation Perspective 阅读笔记 - 知乎 (zhihu.com) https://zhuanlan.zhihu.com/p/445268270和(7条消息) DSGAN: Frequency Separation for Real-World Super-Resolution_sr_super的博客-CSDN博客https://blog.csdn.net/sinat_34546154/article/details/112614765中,退化模型和SR模型的训练是分开的,即它们首先训练退化模型,然后使用训练好的退化模型来帮助训练SR模型。这种两步训练方法虽然耗时但对他们的方法来说是必要的,因为他们的高度非线性退化模型会在训练开始时产生不良结果,这可能会误导 SR 模型的优化。然而,在我们的方法中,由于 PDM 受到更好的约束并且更容易训练,因此同时训练 PDM 和 SR 模型效果很好。通过这种方式,PDM 可以与任何 SR 模型集成,形成盲 SR 的统一框架,称为 PDM-SR(或 PDM-SRGAN,如果在 SR 的训练中也采用对抗性损失和感知损失 [19])模型)。Ps:感觉这部分才是最大的创新,提出了一个通用框架。
https://zhuanlan.zhihu.com/p/445268270和(7条消息) DSGAN: Frequency Separation for Real-World Super-Resolution_sr_super的博客-CSDN博客https://blog.csdn.net/sinat_34546154/article/details/112614765中,退化模型和SR模型的训练是分开的,即它们首先训练退化模型,然后使用训练好的退化模型来帮助训练SR模型。这种两步训练方法虽然耗时但对他们的方法来说是必要的,因为他们的高度非线性退化模型会在训练开始时产生不良结果,这可能会误导 SR 模型的优化。然而,在我们的方法中,由于 PDM 受到更好的约束并且更容易训练,因此同时训练 PDM 和 SR 模型效果很好。通过这种方式,PDM 可以与任何 SR 模型集成,形成盲 SR 的统一框架,称为 PDM-SR(或 PDM-SRGAN,如果在 SR 的训练中也采用对抗性损失和感知损失 [19])模型)。Ps:感觉这部分才是最大的创新,提出了一个通用框架。
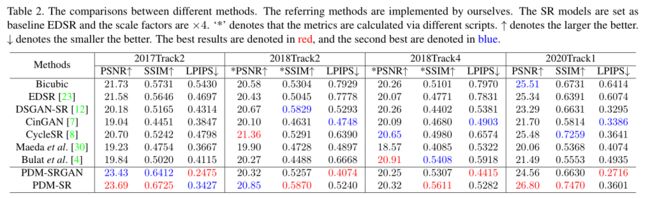
实验部分
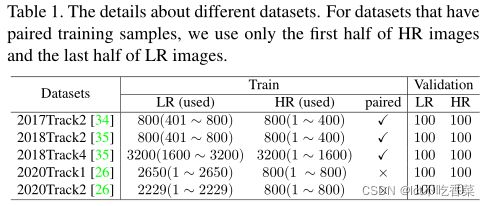
数据集。我们主要在五个数据集上进行实验(Ps:都是比赛数据),即
- NTIRE2017的 track2、
- NTIRE2018的 track2 和 track4
- NTIRE2020的 track1 和 track2
不同数据集的详细信息如表 1 所示。前三个数据集提供了 800、800 和 3200 对 HR-LR 图像进行训练和 100 对 HR-LR 图像进行验证。但在本文中,我们主要研究配对样本不可用的情况。因此,对于每个数据集,我们仅使用 HR 图像的前半部分和 LR 图像的后半部分进行训练。对于 NTIRE2020 的 track1 和 track2,由于他们提供的训练样本已经是未配对的,我们直接使用所有图像进行训练。
评价指标
PSNR ![]() 、SSIM
、SSIM ![]() 、LPIPS
、LPIPS ![]() 、NIQE
、NIQE ![]()
图像在 RGB 空间中进行评估,其中LPIPS 使用 AlexNet计算,NIQE主要用来评价没有GT图像的超分结果。
实施细节
我们对不同的数据集使用不同的 PDM 设置。对于所有数据集,内核模块的设置都是共享的。 ![]() 的维度设置为
的维度设置为  = 64,模糊核的大小设置为 21×21。为简单起见,我们假设数据集中的模糊核是空间不变的。
= 64,模糊核的大小设置为 21×21。为简单起见,我们假设数据集中的模糊核是空间不变的。
- 对于 2017Track2,由于测试图像干净且几乎没有噪点,我们省略了 PDM 中的噪点模块。
- 对于其他三个数据集,
 的维度设置为
的维度设置为  = 3,卷积权重的大小设置为 3 × 3。我们使用 PatchGAN 鉴别器作为对抗性训练的鉴别器。
= 3,卷积权重的大小设置为 3 × 3。我们使用 PatchGAN 鉴别器作为对抗性训练的鉴别器。
SR模型是根据比较方法选择的。为了公平比较,所有比较方法共享相同的 SR 模型。在本文中,有两种情况:基线 EDSR 和 RRDB。
训练
我们将 HR 图像裁剪为 128 × 128,将 LR 图像裁剪为 32 × 32 用于训练。 batch size = 32。我们所有的模型都在单个 RTX 2080Ti GPU 上进行了 2 × ![]() 次的训练。我们使用 Adam 作为优化器。所有模型的学习率在开始时设置为 2 ×
次的训练。我们使用 Adam 作为优化器。所有模型的学习率在开始时设置为 2 ×  ,每 5000 次衰减一半。
,每 5000 次衰减一半。
一些客观指标