注意力机制(CH10)——attention
自用~~笔记~~~
李沐《动手学习深度学习》pytorch版第十章笔记。
1. 注意力提示
查询、键、值

注意力机制与全连接层或汇聚层的区分:“是否包含自主性提示”。
- 自主性提示成为:查询(query) (像目标是什么就是找什么)
- 给定任意查询,注意力机制通过注意力汇聚(attention pooling)将选择引导至感官输入(sensory inputs,例如中间特征表示)。感官输入:值(value)
- 每个值与键(key)配对。可以想象为感官输入的非自主提示。
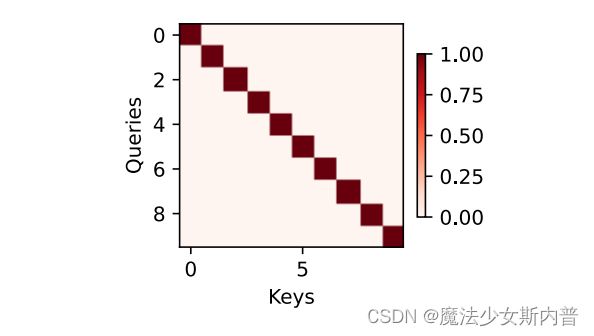
如下图,设计注意力汇聚,以便给定的查询(自主性提示)与键(非自主性提示)匹配,引导得出最匹配的值(感官输入)。

所以:查询(query,自主提示)和键(key, 非自主提示)之间的交互形成了注意力汇聚,注意力汇聚有选择的聚合了值(value)以生成最终输出。
例如:仅当查询和键相同时,注意力权重为1,否则为0。
2. 注意力汇聚:Nadaraya-Watson 核回归
本节以核回归为例介绍注意力汇聚。
生成数据集
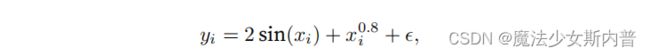
平均汇聚

非参数注意力汇聚
通用的注意力汇聚公式:
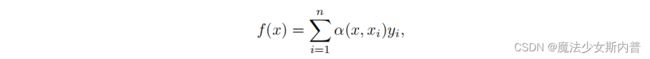
其中,x是查询,(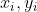 )是键值对。查询x 和键
)是键值对。查询x 和键 之间关系建模为注意力权重。越接近x那么分配给对应
之间关系建模为注意力权重。越接近x那么分配给对应 的注意力权重越大。
的注意力权重越大。
将高斯核代入上式可得
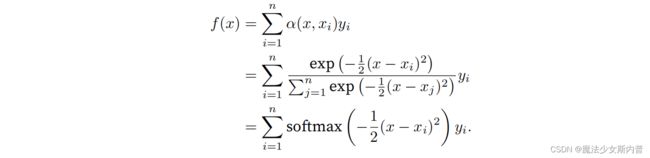
在实验过程中:测试数据的输入相当于查询,而训练数据的输入相当于键。
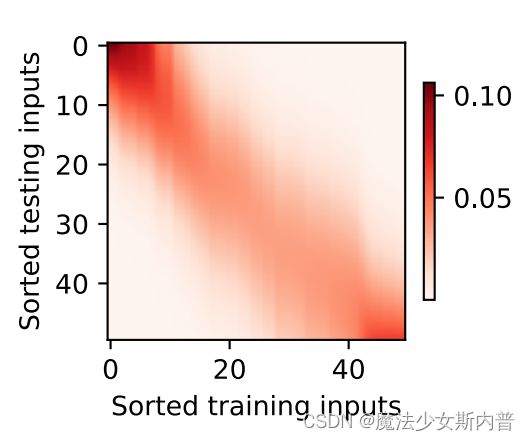
带参数注意力汇聚
在下⾯的查询x和键xi之间的距离乘以可学习参数w:

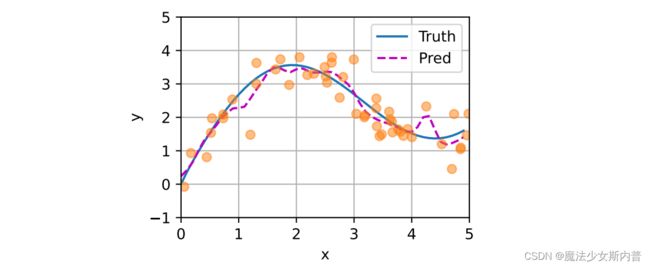

3. 注意力评分函数
如上一部分,高斯核可以说为注意力评分函数,然后输出到softmax函数中,得到与键对应的值的概率分布即注意力权重。最后加权求和,注意力汇聚的输出就是基于这些注意力权重的值的加权和。
键k、查询q——>评分函数——>softmax——>注意力权重——>和值v加权平均——>输出

attention机制的本质:即是如下,它里面存储的数据按
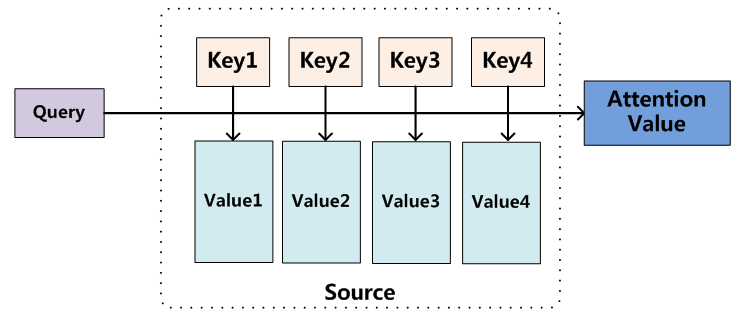
公式描述:
![]()
将上上图再画一遍,attention的计算可分为如下三个阶段:
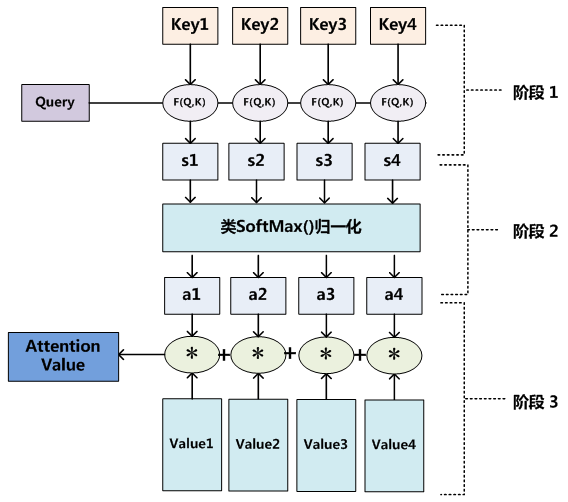

注意力打分机制:

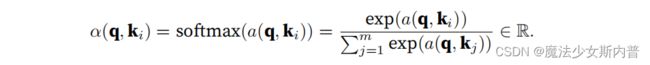 归一化的注意力概率分布
归一化的注意力概率分布
![]()
如前可知,选择不同的注意力评分函数 会导致不同的注意力汇聚操作,接下来介绍几个评分函数。(下图中的score(h,H)就是上面的similarity(Q,K)和这几个都一样。 )
会导致不同的注意力汇聚操作,接下来介绍几个评分函数。(下图中的score(h,H)就是上面的similarity(Q,K)和这几个都一样。 )

掩蔽softmax操作
防止计算softmax过程中过滤掉超出指定范围的位置,可以指定一个有效序列长度。这叫掩蔽softmax操作(masked softmax operation),任何超出有效长度的位置都要被掩蔽为0。
import math
import torch
from torch import nn
from d2l import torch as d2l
def masked_softmax(X, valid_lens):
"""通过在最后⼀个轴上掩蔽元素来执⾏softmax操作"""
# X:3D张量,valid_lens:1D或2D张量
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape
if valid_lens.dim() == 1:
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
else:
valid_lens = valid_lens.reshape(-1)
# 最后⼀轴上被掩蔽的元素使⽤⼀个⾮常⼤的负值替换,从⽽其softmax输出为0
X = d2l.sequence_mask(X.reshape(-1, shape[-1]), valid_lens,value=-1e6)
return nn.functional.softmax(X.reshape(shape), dim=-1)
"""为了演⽰此函数是如何⼯作的,考虑由两个2 × 4矩阵表⽰的样本,这两个样本的有效⻓度分别为2和3。经过
掩蔽softmax操作,超出有效⻓度的值都被掩蔽为0"""
masked_softmax(torch.rand(2, 2, 4), torch.tensor([2, 3]))
"""同样,我们也可以使⽤⼆维张量,为矩阵样本中的每⼀⾏指定有效⻓度。"""
masked_softmax(torch.rand(2, 2, 4), torch.tensor([[1, 3], [2, 4]]))加性注意力
一般,查询q和键k是不同长度的矢量时,用加性注意力作为评分函数
![]()
可学习的参数是:W_{q} 、W_{k}和 w_{v}。将查询和键连结起来后输入到一个多层感知机里(MLP),感知器包含一个隐藏层,其隐藏单元数是一个超参数h。通过使用tanh作为激活函数,并且禁用偏置项。
2022.12.7 待补充
参考链接:
李沐课程书:https://zh-v2.d2l.ai
详解深度学习中的注意力机制(Attention) - 知乎