SIFT特征点提取及描述论文算法详解
SIFT特征点提取及描述论文算法详解
-
- 1. 尺度空间极值检测(Scale-space extrema detection)
-
- 1.1 尺度空间和极值
- 1.2 DoG和LoG的关系
- 1.3 构建高斯尺度差分空间
-
- Tips
- 2. 极值点定位(Keypoint localization)
-
- 2.1 空间局部极值检测
- 2.2 空间点精确定位
- 2.3 去除不稳定的特征点
- 3. 特征点描述子构造(Orientation assignment and Keypoint descriptor)
-
- 3.1 分配主方向
- 3.2 构造SIFT描述子
- 3.3 归一化处理
- 4. 特征点的匹配(Match)
- 参考文献
- 附录《SCALE-SPACE FILTERING:A New Approach To Multi-Scale Description》论文部分翻译
-
-
- 摘要:
- 1. Introduction
- 2. The Scale-Space Image
- 3. 不同尺度下的追踪
- 6. Summary
-
SIFT(Scale-invariant feature transform)尺度不变特征变换,是计算机视觉中非常经典的特征点提取与描述算法, 该方法于1999年由David Lowe 首先发表于计算机视觉国际会议(International Conference on Computer Vision,ICCV),2004年再次经David Lowe整理完善后发表于International journal of computer vision(IJCV)。
SIFT与Harris这种纯角点检测算法不同,它由 角点检测和 特征点描述子构造两部分组成。也就是他不光能检测到特征点,还可以给他一个描述子向量,有了这个向量, 特征点就可以被计算机所理解。
为了实现尺度不变的特征检测和定位,作者的思路是在所有可能的尺度上搜寻稳定的特征点。
1. 尺度空间极值检测(Scale-space extrema detection)
1.1 尺度空间和极值
尺度空间(scale-space)的概念在1983年Andrew P. Witkin的论文《SCALE-SPACE FILTERING:A New Approach To Multi-Scale Description》中被提出。这篇论文中提到:我们一般用极值和导数来描述信号的特征,然而尺度对这种有描述的影响,所以他们提出了尺度空间(scale-space)作为多尺度描述。论文部分翻译如下:
通常情况下,信号及其导数中的局部极值——以及极值限定的区间——是特别合适的描述基元:虽然局部和与信号数据紧密相连,但这些事件通常有直接的语义解释,例如图像中的边缘。一个描述信号的极值和它的前几个导数的描述是一种定性描述,正是我们在初等微积分中所学到的用来“勾画”一个函数的描述。
信号的极值及其前几阶导数为许多种信号提供了有用的、通用的定性描述。然而我们感知和发现的events在size和extent上差异很大。所以尺度给我们的描述带来了困难。问题的关键不是去消除尺度产生的噪声,而是分离不同物理过程在不同尺度下产生的events.
依赖于尺度的描述可以通过多种方式进行计算。作为一种原始的尺度参数化方法,高斯卷积具有许多好的特性,高斯是对称的,并且严格地减少均值,因此赋予信号值的权值会随着距离的增加而平滑地减少。高斯卷积在尺度参数 σ \sigma σ的极限处表现得很好,在较小的 σ \sigma σ处趋近非光滑信号,在较大的 σ \sigma σ处趋近信号的平均值。高斯函数也很容易被微分和积分。高斯函数并不是唯一满足这些条件的卷积核。然而,我们选择的一个更具体的动机是高斯卷积的零交点(及其导数的交点)的一个性质:当一个值减小时,可能会出现额外的零,但现有的零一般不会消失;此外,在满足“良好行为”准则的卷积核中(大致如上所述),高斯函数是唯一保证满足条件[1]的。这个属性的用途将在下面的部分中解释。
信号f(x)的高斯卷积既依赖于信号的自变量x,也依赖于高斯标准差 σ \sigma σ。卷积是由
F ( x , σ ) = f ( x ) ∗ g ( x , σ ) = ∫ − ∞ ∞ f ( μ ) 1 σ 2 π e − ( x − μ ) 2 2 σ 2 d μ F(x, \sigma) = f(x)*g(x,\sigma) = \int_{-\infty }^{\infty}f(\mu ) \frac{1}{\sigma\sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}d\mu F(x,σ)=f(x)∗g(x,σ)=∫−∞∞f(μ)σ2π1e−2σ2(x−μ)2dμ
其中 ∗ * ∗表示对 x x x的卷积。这个函数在 ( x , σ ) (x,\sigma) (x,σ)平面上定义了一个曲面,其中常数 σ \sigma σ的每个轮廓是 f ( x ) f(x) f(x)的高斯平滑版本,平滑的量随着 σ \sigma σ的增加而增加。我们称 ( x , σ ) (x, \sigma) (x,σ)-平面尺度空间,上面定义的函数 F F F称为图像 f f f的尺度空间。
然而,仅仅在多尺度上计算这种描述并不解决问题,我们需要找到一些方法来组织或简化这些描述(description).我们的解决方法是尺度空间滤波(scale-space filtering)。通过不断改变尺度参数,扫出一个被叫做"尺度空间图像"的表面(因为原文的实验是基于1维信号的,所以多尺度形成一个二维表面。)通过这种表示,在极值随着尺度参数的变化不断移动时我们可以追踪它,并找出出现新极值的奇点。
所以我们现在清楚了尺度空间其实就是一个和连续的以尺度参数为自变量的函数。那么为了实现尺度不变的特征检测和定位,David Lowe的思路是在所有可能的尺度上搜寻稳定的特征点。为了检测尺度空间中稳定的关键点,Lowe又提出了在高斯差分函数和原图像卷积形成的尺度空间中检测极值作为关键点,这个方法的具体思路在Lowe 1999年的论文中。这个高斯差分尺度空间(Difference of Gaussian, DoG)记为 D ( x , y , σ ) D(x,y,\sigma) D(x,y,σ),它通过相邻尺度做差得到,这两个相邻尺度的尺度参数差了一个常数 k k k:
D ( x , y , σ ) = ( G ( x , y , k σ ) − G ( x , y , σ ) ) ∗ I ( x , y ) = L ( x , y , k σ ) − L ( x , y , σ ) D(x,y,\sigma) = (G(x,y,k\sigma)-G(x,y,\sigma))*I(x,y)\\ = L(x,y,k\sigma) - L(x,y,\sigma) D(x,y,σ)=(G(x,y,kσ)−G(x,y,σ))∗I(x,y)=L(x,y,kσ)−L(x,y,σ)
L ( x , y , σ ) = G ( x , y , σ ) ∗ I ( x , y ) L(x,y,\sigma) = G(x,y,\sigma)*I(x,y) L(x,y,σ)=G(x,y,σ)∗I(x,y)
G ( x , y , σ ) = 1 2 π σ 2 e − ( x 2 + y 2 ) / 2 σ 2 G(x,y,\sigma) = \frac{1}{2\pi \sigma^2}e^{-(x^2+y^2)/2\sigma^2} G(x,y,σ)=2πσ21e−(x2+y2)/2σ2
选择 D ( x , y , σ ) D(x,y,\sigma) D(x,y,σ)这个尺度空间函数的原因有很多,其一是它计算高效,且对图像做了一个平滑滤波;其二,它是对尺度归一化的LoG空间( σ 2 ∇ 2 G \sigma^2 \nabla^2 G σ2∇2G)的一个很好近似,而从尺度归一化的LoG空间中提取的特征具有真正的尺度不变性。
1.2 DoG和LoG的关系
D ( x , y , σ ) D(x,y,\sigma) D(x,y,σ)与 σ 2 ∇ 2 G \sigma^2 \nabla^2 G σ2∇2G的关系可以通过heat diffusion方程理解,此时参数是 σ \sigma σ而不是常见的 σ 2 \sigma^2 σ2:
∂ G ∂ σ = σ ∇ 2 G \frac{\partial G}{\partial \sigma} = \sigma\nabla^2G ∂σ∂G=σ∇2G
从上式可以看出。使用相邻尺度 k σ k\sigma kσ和 σ \sigma σ的差值,通过计算有限差分近似 ∂ G ∂ σ \frac{\partial G}{\partial \sigma} ∂σ∂G,可以得到 ∇ 2 G \nabla^2G ∇2G
σ ∇ 2 G = ∂ G ∂ σ ≈ G ( x , y , k σ ) − G ( x , y , σ ) k σ − σ \sigma\nabla^2G = \frac{\partial G}{\partial \sigma} \approx \frac{G(x,y,k\sigma)- G(x,y,\sigma)}{k\sigma-\sigma} σ∇2G=∂σ∂G≈kσ−σG(x,y,kσ)−G(x,y,σ)
因此:
G ( x , y , k σ ) − G ( x , y , σ ) ≈ k σ − σ ∇ 2 G G(x,y,k\sigma)- G(x,y,\sigma) \approx k\sigma-\sigma\nabla^2G G(x,y,kσ)−G(x,y,σ)≈kσ−σ∇2G
这表明,当高斯差函数的尺度相差一个常数因子时,它已经包含了尺度不变拉普拉斯函数所需的 σ 2 \sigma^2 σ2尺度归一化。方程中的因子 ( k − 1 ) (k−1) (k−1)在所有尺度上都是常数,因此不影响极值位置。当k趋近于1时,近似误差趋近于0.但在实践中作者发现,即使是尺度上的显著差异,如 k = 2 k = \sqrt{2} k=2,近似对极值检测或定位的稳定性几乎没有影响。
1.3 构建高斯尺度差分空间
构建DoG的过程如下图所示:

基本概念:
图像金字塔: 图像金字塔模型是指将原始图像不断降阶采样,得到一系列大小不一的图像,由大到小,从下到上构成的塔状模型。
降采样: 对金字塔上一组图像的图像隔点采样(隔一个像素取一个像素)得到。
octave: 是指金字塔的每一层,包含一组连续尺度的高度模糊图像。一个octave内部的组数叫做interval(组内层数)。
构建过程:
初始图像被递增的高斯函数重复进行卷积,以生成在尺度空间中尺度以常数因子 k k k分隔的图像,如左列所示。把左侧相邻尺度的图像做差得到右侧的高斯尺度差分图像。检测是在右侧的DoG空间中进行的。
David Lowe选择将尺度空间的每个octave(即 σ \sigma σ的倍增)划分为一个整数 s s s的区间,所以 k = 2 k=\sqrt{2} k=2。
这一段不太懂他为啥所以…,附上原文。
We choose to divide each octave of scale space (i.e., doubling of σ \sigma σ) into an integer number, s, of intervals, so k = 2 \sqrt{2} 2. We must produce s + 3 s +3 s+3 images in the stack of blurred images for each octave, so that final extrema detection covers a complete octave.
我理解这里的 s s s应该是DoG中每个octave里检测极值点的尺度的个数,由于接下来检测局部极值的时候(接下来2.1节就会提到),是考虑尺度空间邻域,即需要和上下相邻的尺度作比较,所以对于上面图片中 s = 2 s=2 s=2的情况来说,右列中这4个尺度中中间两个尺度用于检测。所以检测 2 2 2个尺度,那么DoG中就需要 s + 2 = 4 s+2=4 s+2=4张图片。那么左侧的高斯模糊图像就需要 s + 3 = 5 s+3=5 s+3=5张。
k与s的关系: k = 2 1 s k=2^{\frac{1}{s}} k=2s1
做完一个octave后,需要下采样得到下一个octave的初始图像,作者使用初始尺度 σ \sigma σ两倍的图像做降采样,正好是每个octave从上往下倒数第三张图像。这样使得检测的尺度是连续的。
Once a complete octave has been processed, we resample the Gaussian image that has twice the initial value of σ (it will be 2 images from the top of the stack) by taking every second pixel in each row and column. The accuracy of sampling relative to σ is no different than for the start of the previous octave, while computation is greatly reduced
作者通过一组真实图像的实验确定了尺度采样频率和空间采样频率,实验表明 s = 3 , σ 0 = 1.6 s=3, \sigma_0 = 1.6 s=3,σ0=1.6时检测到的极值点能够被正确匹配的比最高,因此,本文采用这个值作为默认参数。
其中 s s s代表Number of scales sampled per octave: 也就是每个octave中提取特征点的层数, σ 0 \sigma_0 σ0代表Prior smoothing for each octave.
论文中的超参数的实验结果:
Tips
实际中,如果我们在极值检测之前对图像进行预平滑,我们就有效地丢弃了最高的空间频率。因此,为了充分利用输入,可以将原始图像扩展一下,创建比原始图像更多的采样点。在构建金字塔的第一级之前,我们使用线性插值将输入图像的大小增加了一倍。虽然通过在原始图像上使用亚像素偏移滤波器可以有效地执行等效操作,但图像倍增可以更有效地实现。假设原始图像至少有σ = 0.5(防止明显混叠的最小值)的模糊,因此,相对于新的像素间距,加倍的图像有σ = 1.0。这意味着在创建尺度空间的第一个octave之前几乎不需要额外的平滑。把输入图像扩大一倍使检测到的稳定关键点的数量增加了近4倍,但扩大更多的倍数时没有发现进一步的显著改善。
这一块如果觉得抽象可以参考这个链接https://blog.csdn.net/zddblog/article/details/7521424
2. 极值点定位(Keypoint localization)
2.1 空间局部极值检测
我们认为在尺度空间中 D ( x ) D(x) D(x)的值极值点可能是特征点,所以在高斯差分尺度空间中,搜索每个点的26邻域 ( 8 + 9 + 9 ) (8+9+9) (8+9+9),若是该点为局部极值点,则保存为候选关键点。

2.2 空间点精确定位
由于图片是对连续信号的离散采样,所以我们上一步得到的像素级的极值点可能是不准确的,要进一步计算,确定关键点的精确位置。
对每个极值点,把DoG函数做二阶泰勒展开:
D ( x ) = D + ∂ D T ∂ X X + 1 2 X T ∂ 2 D ∂ X 2 X D(x) = D + \frac{\partial D^T}{\partial X}X +\frac{1}{2}X^T \frac{\partial^2D}{\partial X^2}X D(x)=D+∂X∂DTX+21XT∂X2∂2DX
对方程求导,令导数为0,得到的解即为极值点的偏移量:
X ^ = − ∂ 2 D − 1 ∂ X 2 ∂ D ∂ X \hat{X} = - \frac{\partial^2 D^{-1}}{\partial X^2}\frac{\partial D}{\partial X} X^=−∂X2∂2D−1∂X∂D
其中 X = ( x , y , σ ) X = (x,y,\sigma) X=(x,y,σ),如果它在任一维度上偏移量大于0.5,那就说明极值点已经偏到另一个像素上去了,此时就要改变关键点的初始位置 x x x,然后重新计算偏移量,重复进行。最终得到的值可能就不是整数了,是亚像素精度。
2.3 去除不稳定的特征点
由于对比度低的点易受噪声影响,DoG对图像中的边缘有较强的响应,而一旦特征点落在图像边缘上,这些点就变得不稳定,所以我们要把它们去除。
2.3.1 去除对比度低的点
我们认为如果这个点的DoG值不够大的话就把他去掉。
D ( x ^ ) = D + 1 2 ∂ D T ∂ X X D(\hat{x})=D+\frac{1}{2}\frac{\partial D^T}{\partial X}X D(x^)=D+21∂X∂DTX
根据经验,取 ∣ D ( x ^ ) ∣ < 0.03 |D(\hat{x})|<0.03 ∣D(x^)∣<0.03
2.3.2 去除边缘点
利用Hession矩阵 H H H判断关键点是否位于边缘。如果在边缘上,两个特征值的比值会比较大,因此设置个阈值来判断。H的两个特征值对应两个方向上的主曲率大小。
设两个特征值之间的比值为 r r r: λ 1 = r λ 2 \lambda_1 = r\lambda_2 λ1=rλ2
T r 2 ( H ) D e t ( H ) = ( λ 1 + λ 2 ) 2 λ 1 λ 2 = ( r λ 2 + λ 2 ) 2 r λ 2 λ 2 = ( r + 1 ) 2 r > ( 10 + 1 ) 2 10 \frac{Tr^2(H)}{Det(H)} = \frac{(\lambda_1+\lambda_2)^2}{\lambda_1\lambda_2} = \frac{(r\lambda_2+\lambda_2)^2} {r\lambda_2\lambda_2}\\=\frac{(r+1)^2}{r} > \frac{(10+1)^2}{10} Det(H)Tr2(H)=λ1λ2(λ1+λ2)2=rλ2λ2(rλ2+λ2)2=r(r+1)2>10(10+1)2
r r r的设定是经验值,Lowe论文中 r r r取了10
通过计算矩阵的行列式和矩阵,避免了直接计算特征值。
至此,其实就完成了特征点检测部分,接下来就是为每个特征点分配一个描述子。
3. 特征点描述子构造(Orientation assignment and Keypoint descriptor)
刚刚的DoG差分,使得特征点具有了尺度不变性,为了使它再具有旋转不变性,我们要为每个特征点计算它的主方向,再进行特征描述。
3.1 分配主方向
能不能找到一个量,随着被拍摄物体的变化而变化。David Lowe提出了主方向。相机发生旋转时,主方向相对于图像上的物体,是没有发生变化的。这样我们就可以把不同姿态的物体都转到同一个方向上来进行描述。
以特征点为中心, 3 × 1.5 σ 3\times1.5\sigma 3×1.5σ为半径区域,找一个圆形邻域,计算邻域内图像的梯度幅角和幅值,把它分成36份,以角度区间为横坐标,梯度幅值为纵坐标,统计每个区间内梯度幅值的累加,绘制灰度直方图,这表示了这个邻域内图像灰度的统计规律,得到直方图的峰值就是特征点的主方向。
梯度幅角和幅值的计算:
m ( x , y ) = ( L ( x + 1 , y ) − L ( x − 1 , y ) ) 2 + ( L ( x , y + 1 ) − L ( x , y − 1 ) ) 2 m(x,y) = \sqrt{(L(x+1, y)-L(x-1, y))^2 + (L(x,y+1)-L(x,y-1))^2} \\ m(x,y)=(L(x+1,y)−L(x−1,y))2+(L(x,y+1)−L(x,y−1))2
θ ( x , y ) = t a n − 1 ( ( L ( x , y + 1 ) − L ( x , y − 1 ) ) / ( L ( x + 1 , y ) − L ( x − 1 , y ) ) \theta(x,y) = tan^{-1}((L(x,y+1)-L(x,y-1))/(L(x+1, y)-L(x-1, y)) θ(x,y)=tan−1((L(x,y+1)−L(x,y−1))/(L(x+1,y)−L(x−1,y))
值得一提的是,在梯度直方图中,一个特征点可能产生多个坐标、尺度相同,但是方向不同的特征点,15%的特征点有多方向,而且这些点对匹配的稳定性很关键。在梯度直方图中,当存在一个相当于主峰值梯度幅值80%的区间时,可以认为这个方向是这个特征点的辅助方向。为了得到更精确的方向,关键点的方向可以由和主峰值最近的三个柱值通过抛物线插值得到。
3.2 构造SIFT描述子
对每一个关键点,把x轴旋转到主方向上,这次取它的矩形邻域,把邻域划分为 4 × 4 4\times4 4×4的子区域,对区域内的每个像素计算它的梯度幅值和方向;对每个子区域,将梯度划分为8个方向 ( 0 , 45 , 90 … ) (0,45,90\dots) (0,45,90…),在每个方向上统计梯度幅值的累加直方图,得到一个 4 × 4 × 8 4\times4\times8 4×4×8的128维向量,作为这个特征点的SIFT描述子。
Tips: 实际中像素的梯度方向不会正好落在划分的方向上,这时候要根据和两个方向的夹角关系在做一步插值,表明他对两个方向都有贡献。梯度幅值求和时还有一个权值的变化,离中心点近的权值大。
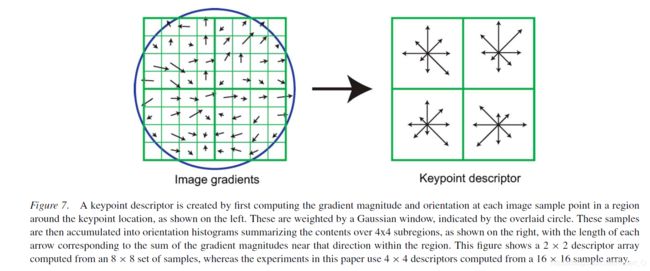
3.3 归一化处理
为了去除光照变化的影响,对特征向量进行归一化处理,去除图像灰度值的整体漂移。
4. 特征点的匹配(Match)
匹配准则:总体思路在另一幅图像的所有特征点中找到一个描述子和当前点最接近的。
- 最近邻匹配:直接算两个128维向量的距离,选最近的。这一步可以两幅图像互相匹配。如果互相Match上了,那才算,这样可以减少很多误匹配。
- 最邻近距离和次邻近距离比。对左图每一个点在右图中寻找它的最邻近和次临近点,如果最邻近距离比次临近距离小于某个阈值,那就说明他和这个最邻近点离的足够近,此时认为他们匹配上了。
搜索策略:当特征点较多时,采用暴力搜索两两计算距离效率是很低的,所以往往采用一些高效的数据结构或者搜索算法,比如kd-tree ,BBF
参考文献
[1] David G. Lowe. Distinctive Image Features from Scale-Invariant Keypoints[J]. International Journal of Computer Vision, 2004, 60(2) : 91-110.
[2] Witkin, A.P . 1983. Scale-space filtering. In International Joint Conference on Artificial Intelligence, Karlsruhe, Germany, pp. 1019–1022.
附录《SCALE-SPACE FILTERING:A New Approach To Multi-Scale Description》论文部分翻译
摘要:
信号的极值及其前几阶导数为许多种信号提供了有用的、通用的定性描述。计算这类描述的一个基本问题是尺度:一个导数必须取代某些邻域,但很少有选择其大小的原则基础。尺度空间滤波是一种定性地描述信号的方法,以有组织和自然的方式处理尺度模糊。信号首先用高斯掩模在一个连续尺寸上进行卷积展开。然后,利用其定性结构,将这张“尺度空间”图像折叠成一棵树,提供涵盖所有观测尺度的简洁而完整的定性描述。该描述通过应用稳定性标准进一步细化,以识别规模上持续存在大变化的事件。
1. Introduction
几乎没有任何复杂的信号理解任务可以直接使用原始的数字信号值;首先必须得到信号的一些描述。最初的描述应该尽可能地紧凑,其元素应该尽可能地与信号形成过程中有意义的对象或事件相对应。通常情况下,信号及其导数中的局部极值——以及极值限定的区间——是特别合适的描述基元:虽然局部和与信号数据紧密相连,但这些事件通常有直接的语义解释,例如图像中的边缘。一个描述信号的极值和它的前几个导数的描述是一种定性描述,正是我们在初等微积分中所学到的用来“勾画”一个函数的描述。
为了得到这种原始的定性描述(文献综述见[11],[2],[1O])花费了大量的努力,这个问题被证明是极其困难的。尺度问题一直以来都是困难的一个基本来源,因为我们所感知和发现的有意义的事件在规模和程度上有着巨大的差异。问题不在于消除精细尺度的噪声,而在于分离由不同物理过程产生的不同尺度的事件可以通过一个可变大小的掩模平滑信号来引入尺度参数,但引入尺度依赖会产生歧义:尺度参数的每一个设置都会产生不同的描述;新的极值点可能出现,现有的极值点可能移动或消失。我们如何判断哪个描述的连续体是“正确的”?
很少有一个健全的基础来设置尺度参数。事实上,对于许多任务来说,没有一种描述尺度是绝对正确的:产生图像等信号的物理过程在不同的尺度上起作用,本质上没有哪一种更有趣或更重要。因此,尺度引起的模糊性是固有的、不可避免的,因此尺度相关描述的目标不是消除这种模糊性,而是有效地管理它,尽可能地减少它。
这一思路引起了对多尺度描述[12],[2],[9]的极大兴趣。然而,仅仅在多个尺度上计算描述并不能解决问题;如果说有什么不同的话,那就是数据量的增加会加剧这种情况。必须找到一些办法,通过把一种比例尺与另一种比例尺联系起来,来组织或简化描述。在这方面已经做了一些工作,旨在获得“边缘金字塔”(如[6]),但没有提出明确的标准来构建它们。Marr[7]认为,在几个尺度上重合的零跨越是“物理意义上的”,但这个想法既没有得到证明,也没有得到验证。
那么,不同规模的描述如何以一种有组织的、自然的和紧凑的方式相互关联呢?我们的解决方案,我们称之为尺度空间滤波,首先不断改变尺度参数,扫出一个我们称之为尺度备用图像的表面。在这种表示法中,当极值随着尺度的变化不断移动时,可以跟踪极值,并识别出新的极值出现的点。然后,尺度空间图像被压缩成一棵树,提供了所有尺度观测信号的简洁而完整的定性描述。
2. The Scale-Space Image
依赖于尺度的描述可以通过多种方式进行计算。作为一种原始的尺度参数化方法,高斯卷积具有许多具有“良好行为”(well-behavedness )的特性,即高斯是对称的,并且严格地减少均值,因此赋予信号值的权值会随着距离的增加而平滑地减少。高斯卷积在尺度参数 σ \sigma σ的极限处表现得很好,在较小的 σ \sigma σ处趋近非光滑信号,在较大的 σ \sigma σ处趋近信号的平均值。高斯函数也很容易被微分和积分。
高斯函数并不是唯一满足这些条件的卷积核。然而,我们选择的一个更具体的动机是高斯卷积的零交点(及其导数的交点)的一个性质:当一个值减小时,可能会出现额外的零,但现有的零一般不会消失;此外,在满足“良好行为”准则的卷积核中(大致如上所述),高斯函数是唯一保证满足条件[1]的。这个属性的用途将在下面的部分中解释。
信号f(x)的高斯卷积既依赖于信号的自变量x,也依赖于高斯标准差 σ \sigma σ。卷积是由
F ( x , σ ) = f ( x ) ∗ g ( x , σ ) = ∫ − ∞ ∞ f ( μ ) 1 σ 2 π e − ( x − μ ) 2 2 σ 2 d μ F(x, \sigma) = f(x)*g(x,\sigma) = \int_{-\infty }^{\infty}f(\mu ) \frac{1}{\sigma\sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}d\mu F(x,σ)=f(x)∗g(x,σ)=∫−∞∞f(μ)σ2π1e−2σ2(x−μ)2dμ
其中 ∗ * ∗表示对 x x x的卷积。这个函数在 ( x , σ ) (x,\sigma) (x,σ)平面上定义了一个曲面,其中常数 σ \sigma σ的每个轮廓是 f ( x ) f(x) f(x)的高斯平滑版本,平滑的量随着 σ \sigma σ的增加而增加。我们称 ( x , σ ) (x, \sigma) (x,σ)-平面尺度空间,上面定义的函数 F F F称为图像 f f f的尺度空间。图1所示的是一个随 σ \sigma σ的增加而增加的高斯平滑序列。这些是来自于尺度空间图像的常数剖面图。
在 σ \sigma σ的任意值处,平滑信号的n阶导数的极值由(n + 1)阶导数的零点给出,使用下面的式子计算
∂ n F ∂ x n = f ∗ ∂ n g ∂ x n \frac{\partial^n F}{\partial x^n} = f* \frac{\partial^n g}{\partial x^n} ∂xn∂nF=f∗∂xn∂ng
其中高斯函数的导数很容易得到。虽然这里提出的方法适用于任何导数的零点,我们将限制我们的注意力在那些在第二。这些是斜率的极值,即拐点。对于尺度空间图像, σ \sigma σ的所有值处的拐点都满足:
F x x = 0 , F x x x ≠ 0 F_{xx} = 0, F_{xxx} \ne 0 Fxx=0,Fxxx=0
用下标符号表示偏微分。
3. 不同尺度下的追踪
F x x = 0 F_{xx}=0 Fxx=0的等值线标记了平滑信号中拐点的出现和运动,为拐点在所有尺度上的定性描述提供了原料。接下来,我们将对这些等值线应用两个简化假设:
(1)确定性假设,极值点可以在不同的尺度被观察到,但是它躺在公共的零等值线在的尺度空间中,这来自于一个潜在的事件
(2)位置假设,产生零等值线的点的真实位置是当 σ = 0 \sigma=0 σ=0时等值线上 x x x的位置。
6. Summary
尺度空间滤波是一种定性地描述信号的方法,根据信号的极值或其导数,以一种有效地处理大尺度事件的尺度精确定位问题,并有效地管理多重尺度描述的模糊性,不引入任意阈值或自由参数。一维信号首先被扩展成一个二维的尺度空间图像,通过卷积高斯在一个连续尺寸。然后利用极值点在尺度空间的连通性和新出现的单个极值点,将这个连续曲面分解成离散结构。所得到的树表示是对所有观测尺度上的信号的一种简洁而完整的定性描述。使用最大稳定性准则进一步约束了树,以支持在规模大变化时持续存在的事件。我们目前正在研究尺度空间滤波在几种信号匹配和解释问题中的应用,同时研究其解释感知分组现象的能力。该方法也被扩展到适用于二维图像:一个二维信号的尺度空间图像占用了一个包含零交叉曲面的体积。