手把手教你学会深度学习框架—PyTorch
摘要: PyTorch是一个基于Python语言的深度学习框架,专门针对 GPU 加速的深度神经网络(DNN)的程序开发。基本上,它所有的程序都是用python写的,这就使得它的源码看上去比较简洁,在机器学习领域中有广泛的应用。
PyTorch是一个灵活的深度学习框架,它允许通过动态神经网络(即if条件语句和while循环语句那样利用动态控制流的网络)自动分化。它支持GPU加速、分布式训练、多种优化以及更多的、更简洁的特性。
神经网络是计算图形的一个子类。计算图形接收输入数据,并且数据被路由到那些可能由对数据进行处理的节点进行转换。在深度学习中,神经网络中的神经元通常用参数和可微函数进行数据变换,从而可以通过梯度下降来优化参数以最大程度的减少损失。更广泛来说,函数可以是随机的,并且图形的结构可以是动态的。因此,虽然神经网络可以很好地适合数据流开发,但是PyTorch的API却围绕着命令行式的编程,这是一种更常见的考虑程序的方式。这使得读取复杂程序的代码和理由变得更容易,而不必浪费大量的性能;PyTorch实际上运行的速度相当快,并带有很多优化,你可以放心地忘记你是个最终用户。
该文件的其余部分是基于官方的MNIST示例,并且应该仅仅是在学习了官方初级教程之后再看。为了提高可读性,代码放在了带有注释的区块中,因此不会被分割成不同的函数或者是文件,因为通常要用于清晰的、模块化的代码。
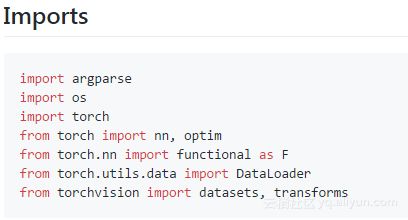
这些是非常标准的程序或者是包导入代码,特别是用于解决计算机视觉问题的视觉模块:
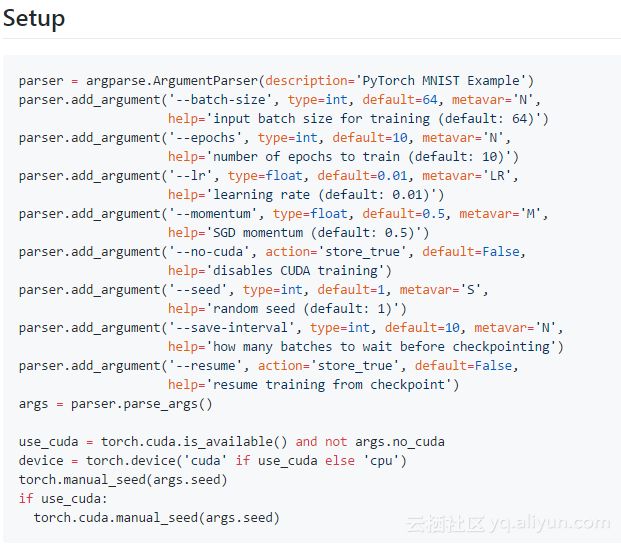
argparse是一种处理在Python中命令行参数的标准方法。
它是一种编写与设备无关的代码的好方法(在可用时受益于GPU加速,但当不可用时则返回到CPU)是选择并保存适当的torch.device,它可以用来决定应该存储张量的位置。更多资料请参阅官方文档。PyTorch方法是将设备放置在用户的控制之下,这对于简单的例子来说可能看起来是件讨厌的事情,但是它使得更容易计算出张量的位置是对调试有用还是使得手动使用设备变得高效。
对于可重复的实验,有必要为任何使用随机数生成的进行随机种子设置。注意,cuDNN使用非确定性算法,并且可以使用
torch.backends.cudnn.enabled = False来进行禁用。
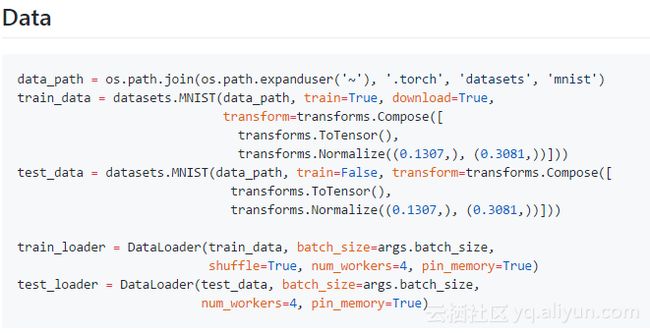
由于torchvision模型在~/.torch/models/下面进行保存的,我在~/.torch/datasets保存torchvision数据集。通常来说,如果结束重用几个数据集,那么将数据集与代码分离开来存放是非常值得的。torchvision.transforms包含很多给单个图片的方便转换的功能,如修剪和正常化。
DataLoader含有许多可选方案,但是在batch_size和shuffle参数之外,num_workers和pin_memory对于效率也是值得了解一下的。num_workers > 0使用了子进程来进行异步加载数据,而不是在这个过程中使用主进程块。pin_memory使用pinned RAM来加速RAM到GPU的传输。
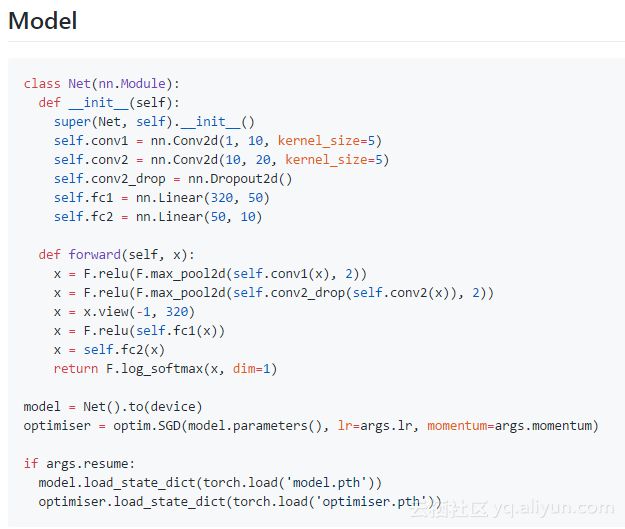
网络初始化通常包括一些成员变量和可训练参数的层,以及可能分开的可训练参数和不可训练的缓冲器。前向传递之后,使用那些来自纯函数F的函数(不包含参数)的结合。有些人倾向具有完全功能的网络(例如,保持参数分离和使用F.conv2d,而不是nn.Conv2d)或者是那些完全分层的网络(例如,nn.ReLU,而不是F.relu)。
to(device)是将设备参数(和缓冲器)发送到GPU的简便方法,如果设备被设置为GPU,则不做任何操作(当设备被设置为CPU)时。在将网络参数传递给优化器之前,将它们传递给合适的设备是非常重要的,否则优化器将不会正确跟踪参数。
神经网络(nn.Module)和优化器(optim.Optimizer)都具有保存和加载其内部状态的能力,并且.load_state_dict(state_dict)是推荐这么做的方法,你将需要重新加载这两个状态以恢复之前保存的状态字典的训练。保存整个对象可能会容易出错。
这里没有指出的一些要点是,正向传递可以使用控制流,例如,成员变量,或者甚至数据本身可以决定if语句的执行。在中间打印出张量也是非常有效的,这会使调试变得更加容易。最后,前向传递可以使用多个参数。用一个简短的代码片段来说明这一点:
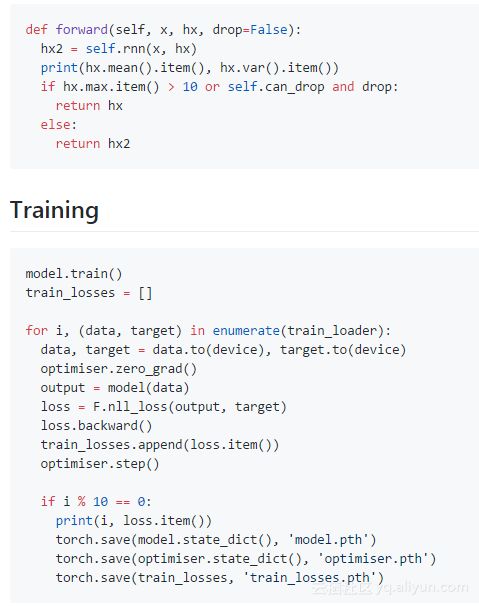
默认情况下,网络模块设置为训练模式—这影响了一些模块的运行效果,最明显的是流失和批量标准化。无论如何,最好通过.train()来进行手动设置参数,它将训练标志继承到所有的子模块。
在用loss.backward()收集一组新的梯度并用optimiser.step()进行反向传播之前,有必要手动地集中那些用优化器.zero_grad()优化过了参数的梯度。默认情况下,PyTorch逐渐增加梯度,这是非常方便的,尤其是当你没有足够的资源来计算所有你一次性需要的梯度的时候。
PyTorch使用基于磁带的自动梯度系统—它按一定的顺序收集对张量进行的操作,然后对它们进行重放以进行逆向模式求导。这就是为什么它是超级灵活的原因,并且允许任意的计算图形。如果张量中没有一个需要梯度(当构造张量时,你必须设置requires_grad=True),则不存储任何图形!然而,网络往往趋向那些具有需要梯度的参数,所以从一个网络的输出所做的任何计算都将存储在图形中。因此,如果要想存储由此产生的数据,那么你需要手动禁用梯度,或者更常见地,将其存储为Python数字(通过使用PyTorch标量上的.item())或numpy数组。请在autograd上参阅官方文档以了解更多信息。
切割计算图形的一种方法是使用.detach(),当通过截断反向传播时间来训练RNNs时,可以使用这个方法来隐藏状态。当一个成分是另一个网络的输出时,它也很方便的区分一个损耗,但是这个网络不应该在损失方面被优化 — 例如在GAN训练中从生成器的输出中训练一个鉴别器,或者使用值函数作为基线(例如A2C)的算法训练一个演员评论算法的策略,另一种防止梯度计算的技术在GAN训练中是有效的(训练来自鉴别器的生成器),以及通常在微调中是通过网络参数并设置param.requires_grad = False进行循环。
除了在控制台或者在日志文件中的日志记录结果外,检查点模型参数(和优化器状态)是非常重要的,用于以防万一。你还可以使用torch.save()来保存普通的Python对象,但其它标准选择包括在内置的配置中。
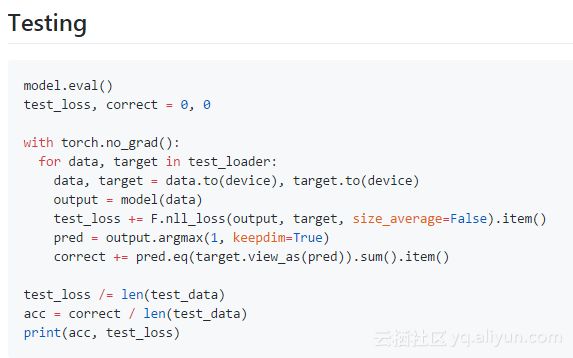
其他:
CUDA调试错误,通常是逻辑问题,会在CPU上产生更明白易懂的错误消息。如果你正在计划使用GPU,最好的方式是能在CPU和GPU之间轻松地切换。一个更普遍的开发技巧是能够设置你的代码,以便在启动一个合适的工作任务之前快速运行所有的逻辑来检查代码—示例是准备一个小的、合成的数据集,运行一个训练、测试周期等等。如果是一个CUDA错误,或者你真的不能切换到CPU模式,那么设置CUDA_LAUNCH_BLOCKING=1将使CUDA内核同步启动,从而会提供更清楚明确的错误消息。
对于torch.multiprocessing的记录,甚至只是一次性运行多个PyTorch脚本。因为PyTorch使用多线程的BLAS库来加速CPU上的线性代数运算,因此它通常会使用多个内核。如果想同时使用多个处理进程或者多个脚本来运行多个程序,那么你可以手动地通过将环境变量OMP_NUM_THREADS设置为1或另一个小的数字参数来实现—这减少了CPU大幅震动的机会。官方文档中有特别用于多处理技术的注释。
作为过来人,跟大家聊一聊我的自学心得,希望可以帮助大家少走弯路,少踩坑。
更多人工智能配套视频教程+书籍可以+v

对方向选择、学习规划、学习路线、职业发展方面有问题的可以加群:809160367

