在PyG上构建自己的数据集
PyG构建自己数据集
PyG简介
PyG(PyTorch Geometric)是一个建立在 PyTorch 基础上的库,用于轻松编写和训练图神经网络(GNN),用于与结构化数据相关的广泛应用。
它包括在图和其他不规则结构上进行深度学习的各种方法,也被称为几何深度学习,来自各种已发表的论文。此外,它还包括易于使用的迷你批量加载器(mini-batch loaders),用于在许多小型和单一的巨型图形上操作;多 GPU 支持、大量常见的基准数据集(基于简单的接口来创建你自己的数据集);以及有用的变换,既可以在任意图形上学习,也可以在 3D 网格或点云上学习。
数据集介绍
本部分用到的也是Cora数据集,但是不是官方版本的数据集,而是非常平易近人的风格,拿来就可以使用,格式如下:
cora.cites

cora.cites文件格式非常简单,就是两列,代表两个具备边关系的节点。
cora.content


cora.content文件内容也很简单,第一列是节点id,最后一列是每个节点的标签,中间的数值是每个节点的特征值。
代码实现
PyG构建数据集,氛围两类,一种是针对小数据集的in_memory_dataset,这种形式可以直接将所用的数据集都加载到内存当中;另一种是针对大数据集的Dataset,这种形式主要是可以对大数据集进行索引,进行batch合并,减少每次内存的数据量。实际业务中,我们大多是用大数据集,因此,就以这个作为例子。
from torch_geometric.data import Dataset, Data
# 定义自己的数据集类
class mydataset(Dataset):
def __init__(self, root, transform=None, pre_transform=None):
super(mydataset, self).__init__(root, transform, pre_transform)
# 原始文件位置
@property
def raw_file_names(self):
return ['cora.content', 'cora.cites']
# 文件保存位置
@property
def processed_file_names(self):
return 'data.pt'
def download(self):
pass
# 数据处理逻辑
def process(self):
idx_features_labels = np.genfromtxt(self.raw_paths[0])
x = idx_features_labels[:, 1:-1]
x = torch.tensor(x, dtype=torch.float32)
y, label_dict = self.encode_labels(np.genfromtxt(self.raw_paths[0], dtype='str', usecols=(-1,)))
y = torch.tensor(y)
idx = np.array(idx_features_labels[:, 0], dtype=np.int32)
id_node = {j: i for i, j in enumerate(idx)}
edges_unordered = np.genfromtxt(self.raw_paths[1], dtype=np.int32)
edge_str = [id_node[each[0]] for each in edges_unordered]
edge_end = [id_node[each[1]] for each in edges_unordered]
edge_index = torch.tensor([edge_str, edge_end], dtype=torch.long)
data = Data(x=x, edge_index=edge_index, y=y)
torch.save(data, os.path.join(self.processed_dir, f'data.pt'))
def encode_labels(self, labels):
classes = sorted(list(set(labels)))
labels_id = [classes.index(i) for i in labels]
label_dict = {i: c for i, c in enumerate(classes)}
return labels_id, label_dict
# 定义总数据长度
def len(self):
idx_features_labels = np.genfromtxt(self.raw_paths[0], dtype=np.int32)
uid = idx_features_labels[:, 0:1]
return len(uid)
# 定义获取数据方法
def get(self, idx):
data = torch.load(os.path.join(self.processed_dir, f'data.pt'))
return data
dataset = mydataset('../data/')
data = dataset[0].to(device)
首先,我们定义了自己的一个类,mydataset类,其继承了一个父类-Dataset,这个Dataset类是PyG框架自己定义好的,其中包括数据集下载、数据预处理、数据文件保存、数据检索等等功能,大家可以详细了解一下,我们只对用到的进行解释。
# 原始文件位置
@property
def raw_file_names(self):
return ['cora.content', 'cora.cites']
raw_file_names:指向自己的文件目录下的文件名,这个可以将你用到的文件按照列表的形式进行展现,如果用cora.content,那就是0,用cora.cites,那就是1;
@property
def processed_file_names(self):
return 'data.pt'
processed_file_names:指向处理后的数据文件保存文件名称,可以在下次加载数据的时候,直接读取该文件;
def download(self):
pass
download:该函数是需要去下载数据集的,因为我们是自建数据集,因此,不用;
def process(self):
#读取cora.content文件
idx_features_labels = np.genfromtxt(self.raw_paths[0])
#获取节点特征
x = idx_features_labels[:, 1:-1]
#转为tensor,并指定数据类型
x = torch.tensor(x, dtype=torch.float32)
#获取每个节点的标签
y, label_dict = self.encode_labels(np.genfromtxt(self.raw_paths[0], dtype='str', usecols=(-1,)))
#tensor化
y = torch.tensor(y)
#获取每个节点
idx = np.array(idx_features_labels[:, 0], dtype=np.int32)
#将每个节点映射为id(从0开始)
id_node = {j: i for i, j in enumerate(idx)}
#读取cora.cites
edges_unordered = np.genfromtxt(self.raw_paths[1], dtype=np.int32)
#获取每个节点对应的id
#第一列节点-->id
edge_str = [id_node[each[0]] for each in edges_unordered]
#第二列节点-->id
edge_end = [id_node[each[1]] for each in edges_unordered]
#将边转为tensor
edge_index = torch.tensor([edge_str, edge_end], dtype=torch.long)
#将所有数据加载至Data对象中
data = Data(x=x, edge_index=edge_index, y=y)
#保存处理好的图数据,下次可以直接加载
torch.save(data, os.path.join(self.processed_dir, f'data.pt'))
def encode_labels(self, labels):
classes = sorted(list(set(labels)))
labels_id = [classes.index(i) for i in labels]
label_dict = {i: c for i, c in enumerate(classes)}
return labels_id, label_dict
process:该函数是处理数据的逻辑函数,大家可以将处理数据的逻辑放在该函数中,主要是节点特征、节点标签、以及边的构成;
self.raw_paths:这个是raw_file_names返回的列表和文件路径拼接之后的结果,就是将文件名扩展为路径+文件名;
# 定义总数据长度
def len(self):
idx_features_labels = np.genfromtxt(self.raw_paths[0], dtype=np.int32)
uid = idx_features_labels[:, 0:1]
return len(uid)
len:获取总数据的长度,为了进行数据分割做准备,可以自己定义;
def get(self, idx):
data = torch.load(os.path.join(self.processed_dir, f'data.pt'))
return data
get:制定获取图数据的方式,可以自己定义。
数据输出
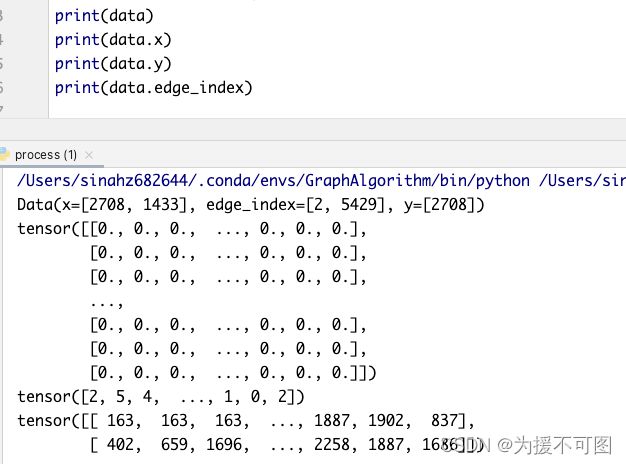
我们可以看到,Data是一个包含所有属性的对象。
x:是27081433的矩阵,即2708个节点,每个节点有1433维;
edge_index:是一个25429的矩阵,表示共有5429条边;
y:表示节点的标签,共2708个节点。
数据集划分
我们构建好了自己的数据集格式,但是,进行训练的时候,必须有训练集、验证集和测试集,这块我曾经自己进行实现过,但是,实现起来比较复杂,这个时候发现,原来PyG框架,也把这块给实现了,还是很方便的。
data = T.RandomNodeSplit()(data)

我们可以看一下RandomNodeSplit,顾名思义,就是随机划分节点,是不是很简单,该函数可以自己划分数据集,自己也可以指定每个数据集的比例,替换其中的参数即可。
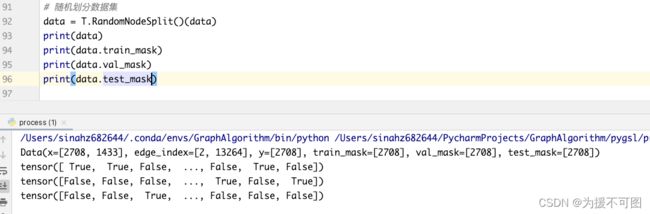
当我们加载完之后,可以看出Data对象中多出来三个,分别是train_mask、val_mask、test_mask,输出看的话,每个都是2708个,但是不同位置上有不同的bool值,就是为了表示该节点是否是训练集、验证集或者测试集。
结语
整体看下来,是不是对于PyG处理数据集有所了解呢,以上已经经过小编的实际运行啦,大家可以拿来改改,用在自己的开发数据集上。
当然,如果有问题或者需要补充的地方,大家可以随时联系我,QQ:1143948594。