Mysql基础进阶(4)-视图、存储过程、函数
目录
-
- 1. 视图的基本介绍
-
-
- 1.1 视图的概念
- 1.2 修改视图
-
- 2. 变量
-
-
- 2.1 系统变量
- 2.2 自定义变量
-
- 3. 存储过程和函数
-
-
- 3.1存储过程
- 3.2 创建带in模式参数的存储过程
- 3.3 创建带out模式参数的存储过程
- 3.4 存储过程的删除
-
- 4. 函数
-
-
- 4.1 创建函数的基本语法
- 4.2 函数的删除
-
- 5. 流程控制结构
-
-
- 5.1 if函数在MySQL中的应用
- 5.2 switch结构在MySQL中的应用
- 5.3 if结构
-
- 6.循环结构
-
-
- 6.1 while结构
- 6.2 loop结构
- 6.3 repeat结构
- 6.4 循环中用到if语句
-
1. 视图的基本介绍
1.1 视图的概念
视图准确来说,其实就是一张表,但是这张表是虚拟的,动态形成的,也就是说并不是实际存储在内存里面的;(从MySQL5.1开始)
简单来说使用的语法和创建表的相似,最大的不同是创建视图需要用到select语句;
#基础语法
create view 视图名
as + select 语句;
1.2 修改视图
**视图的修改和创建类似,唯一的不同就是在使用时,多添加一个replace进行替换;
#第一种语法
create or replace view 视图名
as select 查询
#第二种方法
alter view 视图名
as
select查询语句
在视图中,是允许进行增删改查的,操作和表的一样,但是实际上最好不要在视图中进行增删改,一般只是进行查;当然不允许增删改的视图还是多一点,大部分其实都是不可以的;
通过delete删除的数据是可以支持回滚的,但是truncate删除不支持,一般删除了就是删除了;
2. 变量
2.1 系统变量
由系统提供的变量,不是用户定义,属于服务器层次;可以通过如下语句查询系统变量;
# 查询所有的系统全局变量
show global variables;
#查询所有的系统会话变量
show session variables;
#查询部分全局变量
show global variables like '%XX';
#查询指定的系统变量名,
select @@global|session.系统变量名(global和session只需要一个)
select @@autocommit;#这里查询的是会话的提交,session可以省略;
#对查询到的值进行修改
set global|session 系统变量名=值;
注意:一般情况下,如果是全局的系统变量,就要标注好global;否则默认是session;而且全局变量的范围是所有的会话,也就是在服务没重启前,所有的连接都有效,前提是修改了全局变量;会话变量只是对当前会话有效;
2.2 自定义变量
对局部变量进行声明:
declare 变量名 类型 【default 值】
#局部变量就是指在函数体,存储过程体里;
对变量的值进行设置:
set @变量名=值; #这个不是局部变量,应该是用户变量;
3. 存储过程和函数
3.1存储过程
一组预先编译好的SQL语句集合,可以理解为对多个语句进行批处理;
#基本语法
create procedure 存储过程名(参数列表)
begin
存储过程体(一组合法的SQL语句)、
end
在上面的语法中,参数列表包含三个部分:参数模式,参数名,参数类型;
参数模式也有三中类型:in(参数可以做为输入,需要调用的一方传入值),out(参数作为输出。即为返回值),inout(该参数即需输入又可以输出);
在个存储过程中,如果存储过程体只有一个语句,begin和end可以省略;存储过程的结尾可以使用delimiter进行设置(相当于开始时设置一个标记,然后就可以在结尾的时候,对这个标记进行结尾,后面演示);
语法:delimiter 结束标记
#调用存储过程的基本语法;
call 存储过程名(实参列表);
虽然说存储过程一般运行的语句很多,但是,我演示的时候还是就插入几行就可以了;在navicat中,虽然存储的位置依旧是在函数里,但是存储过程和函数的头是不一样的,一个以P开头,一个是F开头;
![]()
truncate table my_book;
delimiter %;#设置开始符号
create procedure mybook_insert()
begin
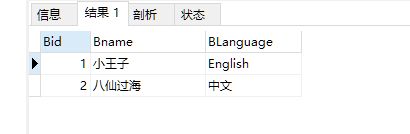
insert into my_book values(1,"小王子",'English');
insert into my_book values(2,"八仙过海",'中文');
end %;通过开始符号结束
#调用mybook_insert过程体;
call mybook_insert() %;
运行之后:
3.2 创建带in模式参数的存储过程
直接摆事实,讲例子:通过传入的参数,对特定的行进行修改;
delimiter % #后面千万不要加;,否则会被当成一个整体"%;"到时候结束就只能通过"%;"
create procedure mybook_update(in newname int)
begin
update my_book
set Bname="时间简史"
where `Bid`=newname;
end %
#传入ID为1;名字修改成时间简史;
call mybook_update(1) %
运行后结果:

以上就是传入in模式参数的基本写法;如果需要传入多个参数,那么就用逗号隔开即可;
3.3 创建带out模式参数的存储过程
#使用的表结构
CREATE TABLE `my_book` (
`Bid` int(11) NOT NULL,
`Bname` varchar(24) DEFAULT NULL,
`BLanguage` varchar(24) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
插入的数据是:
insert into my_book values(1,"时间简史","English")
然后就是和out模式参数相关:
#也可以自定义结尾符,我没自定义了,像上面的in模式一样就可以了;
create procedure mybook_select(out del varchar(24))
begin
select Bname into del
from my_book
where BLanguage='English';
end ;
call mybook_select(@dek);
select @dek;
讲一下我踩过的坑,一个没注意就忘了,MySQL是不区分大小写的,所以设置变量时,最好不要以为有一个单词是大写了,整个变量就不一样了,到时候,结果会告诉你错的多么离谱(小错误,想不清楚,比大错误还要麻烦,因为报的错误,你可能都不知道是什么东西);
inout和前面的in已经out几乎一样的使用方法,这里就提一下,不再全部记录了;看完in,out的使用应该就会使用inout了;
3.4 存储过程的删除
#基本语法:
drop procedure 存储过程名;
删除存储过程和表,还有数据库类似;
4. 函数
由于前面刚刚了解并学习了存储过程,现在可以简单的将函数和存储过程进行一下比较;
- 存储过程中,可以没有返回,也可以有多个返回;函数则是只有一个返回,通过return返回(必须要有);
- 存储过程是procedure,函数的关键词是function;
- 在参数中,只有存储过程才有模式(in,out,inout),而函数只需要写(参数名 数据类型);
- 相同点:当函数体和存储过程体都只有一行时,begin和end可以省略;
- 都可以使用delimiter来自定义结束标记;(自定义的不能在可视化窗口使用,
只能去命令行)
4.1 创建函数的基本语法
基本语法:
create function 函数名(参数列表) returns 返回类型
begin
函数体
end
如下举个小例子:
delimiter $
create function Mybook(id int) returns varchar(24)
begin
declare Bookname varchar(24);
select Bname into Bookname
from my_book
where Bid=id;
return Bookname;
end $
select Mybook(1) $ #在命令行执行,
上面的函数中要注意的点,主要就是那个varchar类型后面都是要跟一个大小,如果不跟就会一直错,然后就是记住写return语句,因为function必须要有返回值,最后就是第一行的返回类型,是returns加返回类型,这几个点记住之后,基本上就可以写函数了;
想要查看函数的具体结构,或者说具体内容;可以有
show create function 函数名,表和存储过程也可以这样查看;后来我去试了一下视图,也是可以这样查看的,完全没有问题;
4.2 函数的删除
基本语法:
drop function 函数名;
5. 流程控制结构
就是指可能代码的运行,一般都是有迹可循的,普遍情况下,都是顺序结构,当然也有分支结构;
5.1 if函数在MySQL中的应用
#基本语法
if(表达式1,表达式2,表达式3)
#如果表达式1结果为true,那么执行表达式2,否则执行表达式3;
#if函数和Java的三元运算符类似;
5.2 switch结构在MySQL中的应用
有两种使用的方式:第一种用于等值判断,第二种用于区间判断;
第一种情况:
#基本语法
case 变量|表达式|字段
when 值 then 要执行的语句;
...
else 要执行的语句
end case;
第二种情况:
case
when 要判断的条件 then 要执行的语句;
...
else 要执行的语句;
end case;
要注意的点是:如果里面需要执行的都是语句,那么就要放到begin...end里面;可以在存储过程中使用,也可以在函数里使用;
5.3 if结构
#基本语法:
if 条件1 then 语句1;
elseif 条件2 then 语句2;
...
else 语句n;
也可以用于存储过程,和函数;
6.循环结构
6.1 while结构
#基本语法
【标签:】 while 循环条件 do
循环体
end while 【标签】;
6.2 loop结构
#基本语法:
【标签:】 loop
循环体;
end loop 【标签】;
6.3 repeat结构
#基本语法:
【标签:】repeat
循环体;
util 结束循环条件
end repeat【标签】;
6.4 循环中用到if语句
记录一下,if语句有哪些跳转的方法:
- leave 循环标签名(跳出循环)
- iterate 循环的标签名(跳过当前循环,进入下个循环),类似于Java的continue;