【CVPR2022】MatteFormer: Transformer-Based Image Matting via Prior-Tokens
MatteFormer: Transformer-Based Image Matting via Prior-Tokens
中文题目: 借助先验Token的基于Transformer的图像抠图
paper:https://arxiv.org/pdf/2203.15662v1.pdf
code:https://github.com/webtoon/matteformer
摘要
本文提出了一个基于Transformer的图像抠图模型,叫做MatteFormer。它能够在transformer块中充分利用trimap信息。该模型引入了每个trimap区域(前景,背景,未知区域)的全局表征的先验prior。这些先验token能够充当全局先验和参与每个块的自注意力机制。编码器的每一层由PAST(Prior-Attentive Swin Transformer)组成,它以Swin Transformer为基础,不同之处在于(1)它包含PA-WSA(Prior-Attentive Window Self-Attention)层,不仅充当位置tokens,也充当先验tokens。(2)它包含先验存储池,能累积保存前一个块的Tokens并将它们转移到下一个块。在两个抠图数据集上评估了本文的方法,实验结果表明,提出的方法相比于其它SOTA方法有很大的提升。
动机
虽然滑动窗口技术少量的扩大了感受野,但是在较浅的层仍然很难获得足够大的感受野。因此,本文提出了一个先验token,用于表示trimap区域的全局上下文特征。PA-WSA(Prior-Attentive Window Self-Attention)层中的自注意力不仅由空间token,也先验token计算而来。另外,还引入了先验存储池,存储每个块生成的先验token。我们还对先验Token的有效性、自注意图的可视化、ASPP的使用以及计算代价进行了广泛的研究。
创新点
(1)提出了首个基于Transformer的图像抠图算法,MatteFormer
(2)使用先验token指示每个trimap区域的全局信息
(3)设计了PAST(Prior-Attentive Swin Transformer)块,其中包含了PA-WSA(Prior-Attentive Window Self-Attention)层和先验存储池。
(4)在两个数据集上实现了最好的效果。
方法论
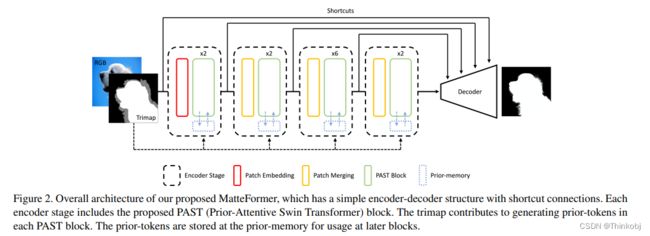
该方法是典型的encoder-decoder结构,中间使用跳跃连接。其中每一个encoder中包含一个PAST(Prior-Attentive Swin Transformer)块。
Prior-token

通过公式(2)生成对应的prior-token,其中 z i z_i zi表示spatial-token的特征。 r i q r_i^q riq表示是否在对应的query区域,其值为0/1。
Prior-Attentive Swin Transformer Blocks

该模块是基于Swin Transformer 块改进的,不止在局部窗口中有spatial tokens,而且在PA-WSA(Prior-Attentive Window Self-Attention)层中有prior-tokens。另外还有prior-memory
其中,prior-tokens是跟spatial-tokens concat起来然后一起送入Self-Attention的,其充当keys和values。
![]()
在局部窗口的spatial-tokens之间,相对位置位于x轴和y轴上的[−M + 1, M−1]范围内。
Prior-tokens 从先前的block生成,并且传递信息到下一个block。
Training Scheme
损失函数如下:
![]()
解码过程使用的是PRM(Progressive Refinement Module)从粗到细的方式:

α l ′ α_l' αl′表示粗的结果, α l α_l αl表示细的结果。 g l g_l gl表示自引导的mask,它是由 α l − 1 α_{l-1} αl−1得到的
结果
在两个公开的数据集都得到了好的结果

总结
使用先验token指示每个trimap区域的全局信息,而且设计了PAST(Prior-Attentive Swin Transformer)块,其中包含了PA-WSA(Prior-Attentive Window Self-Attention)层和先验存储池。总的而言还是有一点创新的,但是跟另一篇ECCV2022论文的思路优点相近,都是在Transformer里面融入trimap的信息,具体可以看这篇博客TransMatting: Enhancing Transparent Objects Matting with Transformers。