CVPR 2021 | Involution:超越卷积和自注意力的神经网络新算子
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文作者: 李铎 | 本文系作者投稿
https://zhuanlan.zhihu.com/p/358183591
本文是对我们CVPR 2021被接收的文章 Involution: Inverting the Inherence of Convolution for Visual Recognition的介绍,同时也分享一些我们对网络结构设计(CNN和Transformer)的理解。
这篇工作主要是由我和SENet的作者胡杰一起完成的,也非常感谢HKUST的两位导师 @陈启峰和张潼老师的讨论和建议。
Involution: Inverting the Inherence of Convolution for Visual Recognition
概要
我们的贡献点简单来讲:
(1)提出了一种新的神经网络算子(operator或op)称为involution,它比convolution更轻量更高效,形式上比self-attention更加简洁,可以用在各种视觉任务的模型上取得精度和效率的双重提升。
(2)通过involution的结构设计,我们能够以统一的视角来理解经典的卷积操作和近来流行的自注意力操作。
论文链接:https://arxiv.org/abs/2103.06255
代码:https://github.com/d-li14/involution
欢迎大家star~ 后续有相关材料(slides,talk,video)的更新会放在主页:
https://duoli.org/
[Motivation] 与convolution的反对称性
这部分内容主要来自原文Section 2,Section 3
普通convolution的kernel享有空间不变性(spatial-agnostic)和通道特异性(channel-specific)两大基本特性;而involution则恰恰相反,具有通道不变性(channel-agnostic)和空间特异性(spatial-specific)。
convolution
convolution kernel的大小写作 ,其中 和 分别是输出和输入的通道数目,而 是kernel size, 一般不写,代表在 个pixel上共享相同的kernel,即空间不变性,而每个通道C独享对应的kernel则称为通道特异性。convolution的操作可以表达为:
其中 是input tensor, 是output tensor, 是convolution kernel。
下面我们分开来看卷积的两大特性:
空间不变性
一方面,空间不变性带来的优点包括:1.参数共享,否则参数量激增至 ,2.平移等变性,也可以理解为在空间上对类似的pattern产生类似的响应,其不足之处也很明显:提取出来的特征比较单一,不能根据输入的不同灵活地调整卷积核的参数。
另一方面,因为卷积操作的参数量和计算量中都存在 一项,其中通道数量C往往是数百甚至数千,所以为了限制参数量和计算量的规模,K的取值往往较小。我们从VGGNet开始习惯沿用 大小的kernel,这限制了卷积操作一次性地捕捉长距离关系的能力,而需要依靠堆叠多个 大小的kernel,这对于感受野的建模在一定程度上不如直接使用大的卷积核更加有效。
通道特异性
之前已经有一些研究低秩近似的工作认为卷积核在通道维度是存在着冗余的,那么卷积核在通道维度的大小就可能可以有所缩减,而不会明显影响表达能力。直观地理解,我们把每个输出通道对应的卷积核铺成一个 大小的矩阵,那么矩阵的秩不会超过 ,代表其中存在很多的kernel是近似线性相关的。
involution
基于以上分析我们提出了involution,它在设计上与convolution的特性相反,即在通道维度共享kernel,而在空间维度采用空间特异的kernel进行更灵活的建模。involution kernel的大小为 ,其中 ,表示所有通道共享G个kernel。involution的操作表达为:
其中 是involution kernel。
在involution中,我们没有像convolution一样采用固定的weight matrix作为可学习的参数,而是考虑基于输入feature map生成对应的involution kernel,从而确保kernel size和input feature size在空间维度上能够自动对齐。否则的话,例如在ImageNet上使用固定 大小的图像作为输入训练得到的权重,就无法迁移到输入图像尺寸更大的下游任务中(比如检测、分割等)。involution kernel生成的通用形式如下:
其中 是坐标(i,j)邻域的一个index集合,所以 表示feature map上包含 的某个patch。
关于上述的kernel生成函数 ,可以有各种不同的设计方式,也值得大家去进一步探索。我们从简单有效的设计理念出发,提供了一种类似于SENet的bottleneck结构来进行实验: 就取为 这个单点集,即 取为feature map上坐标为(i, j)的单个pixel,从而得到了involution kernel生成的一种实例化
其中 和 是线性变换矩阵,r是通道缩减比率, 是中间的BN和ReLU。
注意设计不同的kernel生成函数可以得到involution不同的实例化:
比如可以去探索更加精巧的设计来继续发掘involution的潜力,另外通过采用特定的实例化方法也可以将其特例化成为self-attention的形式(见下节)。
在上述一种简单的involution kernel的实例化下,我们得到完整的involution的示意图:
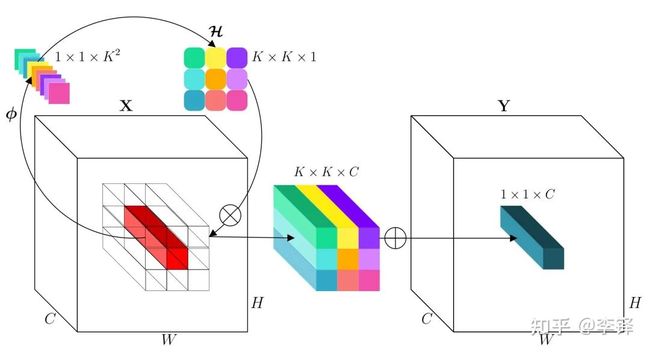
针对输入feature map的一个坐标点上的特征向量,先通过 (FC-BN-ReLU-FC)和reshape (channel-to-space)变换展开成kernel的形状,从而得到这个坐标点上对应的involution kernel,再和输入feature map上这个坐标点邻域的特征向量进行Multiply-Add得到最终输出的feature map。具体操作流程和tensor形状变化如下:
其中 是坐标(i,j)附近 的邻域。单纯基于PyTorch API简单的伪代码实现如下:

involution操作的参数量 ,计算量分为kernel generation和Multiply-Add (MAdd)两部分 ,明显低于普通convolution的参数量 和计算量 。
反过头来考虑和卷积已有的优点的对比:
在通道上共享kernel(仅有G个kernel)允许我们去使用大的空间span(增加K),从而通过spatial维度的设计提升性能的同时保证了通过channel维度的设计维持效率(见ablation in Tab. 6a,6b),即使在不同空间位置不共享权重也不会引起参数量和计算量的显著增长。
虽然我们没有在空间上的每个pixel直接共享kernel参数,但我们在更高的层面上共享了元参数(meta-weight,即指kernel生成函数的参数),所以仍然能够在不同的空间位置上进行knowledge的共享和迁移。作为对比,即使抛开参数量大涨的问题,如果将convolution在空间上共享kernel的限制完全放开,让每个pixel自由地学习对应的kernel参数,则无法达到这样的效果。
总结起来,这种从convolution到involution的设计实际上是在微观粒度(op level)对算力进行了重新的调配,而网络设计的本质就是对算力的分配,目的是将有限的算力调整到最能发挥性能的位置。比如NAS则是在宏观粒度上(network level)通过自动搜索的手段对算力进行了最优配置。
[Discussion] 与self-attention的相关性
这部分内容主要来自原文Section 4.2
self-attention
我们知道self-attention可以表达为(为了表达简略,省略了position encoding部分)
,
其中 分别为输入 线性变换后得到的query,key和value,H是multi-head self-attention中head的数目。下标表示(i, j)和(p,q)对应的pixel之间进行query-key匹配, 表示query(i,j)对应key的范围,可能是 的local patch(local self-attention),也可能是 的full image(global self-attention)。
我们进一步把self-attention展开写成
对比involution的表达式,我们不难发现相似之处:
self-attention中不同的head对应到involution中不同的group(在channel维度split)
self-attention中每个pixel的attention map 对应到involution中每个pixel的kernel
如果involution的kernel生成函数选择实例化为
那么self-attention也是involution的某种实例化,因此我们发现involution是更加general的表达形式。
另外 对应于attention matrix multiplication前对 做的线性变换,self-attention操作后一般也会接另一个线性变换和残差连接,这个结构正好就对应于我们用involution替换resnet bottleneck结构中的 convolution,前后也有两个 convolution做线性变换。
这里再说一下position encoding的事情:
因为self-attention是permutation-invariant的,所以需要position encoding来区分位置信息,而在本文所实例化的involution单元中,生成的involution kernel中的每个元素本身就是按位置排序的,所以不需要额外的position信息。
另外一些基于pure self-attention构建backbone的工作(比如stand-alone self-attention,lambda networks)已经注意到,仅仅使用position encoding而不是用query-key relation就能达到相当可观的性能,即attention map使用 而不是 ( 是position encoding matrix)。而从我们involution的角度来看,这只不过是又换了一种kernel generation的形式来实例化involution。
因此,我们重新思考self-attention在backbone网络结构中有效的本质可能就是捕捉long-range and self-adaptive interactions,通俗点说是使用一个large and dynamic kernel,而这个kernel用query-key relation来构建则并不是必要的。另一方面,因为我们的involution kernel是单个pixel生成的,这个kernel不太适合扩展到全图来应用,但在一个相对较大的邻域内应用还是可行的(如 , ),这同时也说明了CNN设计中的locallity依然是宝藏,因为即使用global self-attention,网络的浅层也很难真的利用到复杂的全局信息。
所以我们所采用的involution去除了self-attention中很多复杂的东西,比如我们仅使用单个pixel的特征向量生成involution kernel(而不是依靠pixel-to-pixel correspondence生成attention map),在生成kernel时隐式地编码了pixel的位置信息(丢弃了显式的position encoding),从而构建了一个非常干净高效的op。
Vision Transformer
既然讨论到了self-attention,就不得不提到最近很火的ViT类工作。针对backbone结构来说,我们认为pure self-attention或者involution model 优于 CNN 优于 ViT (transformer做decoder的可能有其他妙处,比如在DETR中,暂且按下不表)
ViT很多人也讨论过了,底层的linear projection其实类似于convolution,高层用global self-attention抽取relation,可以抽象为convolution接self-attention的混合模型。这种混合结构的提出本身是合理的,在低层用convolution提取low-level信息,在高层用self-attention建模高阶的语义关系。
可是ViT的底层的conv部分做的太不充分了,受制于self-attention爆炸的计算量,在输入端直接把图像切分成16x16的patch,输入feature size基本上相当于已经到了深如resnet倒数第二个stage的feature size,网络底层对于更细节的图像信息利用的非常不到位,而中间处理阶段也没有feature size递减的变换。
因此ICLR'21上提出的ViT结构设计本来就存在很不科学的地方,最近一些改进ViT的工作基本上也可以总结为在ViT中加入更多的spatial维度细化的self-attention操作(patch局部化或再细分,引入convolution的特性),某种意义上是在把ViT变得更像pure self-attention/involution based model。
因此,无论是convolution,self-attention还是新的involution都是message passing和feature aggregation的组合形式,尽管外表各异,本质上没有必要割裂开来看。
实验结果
总体来讲:
(1)参数量、计算量降低,性能反而提升
(2)能加在各种模型的不同位置替换convolution,比如backbone,neck和head,一般来讲替换的部分越多,模型性价比越高
ImageNet图像分类

我们使用involution替换ResNet bottleneck block中的 convolution得到了一族新的骨干网络RedNet,性能和效率优于ResNet和其他self-attention做op的SOTA模型。
COCO目标检测和实例分割

其中fully involution-based detectors(involution用在backbone,neck和head)在保证性能略有提升或不变的前提下,能够将计算复杂度减至 40%。
Cityscapes语义分割

值得一提的是,COCO检测任务中针对大物体的指标 提升最多(3%-4%),Cityscapes分割任务中也是大物体(比如墙,卡车,公交车等)的单类别IoU提升最明显(高达10%甚至20%以上),这也验证了我们在之前分析中所提到的involution相比于convolution在空间上具有动态建模长距离关系的显著优势。
最后,这篇工作也留了一些坑供大家进一步探索:
关于广义的involution中kernel生成函数空间进一步的探索;
类似于deformable convolution加入offest生成函数,使得这个op空间建模能力的灵活性进一步提升;
结合NAS的技术搜索convolution-involution混合结构(原文Section 4.3);
我们在上文论述了self-attention只是一种表达形式,但希望(self-)attention机制能够启发我们设计更好的视觉模型,类似地detection领域最近不少好的工作,也从DETR的架构中获益匪浅。
希望2021年backbone网络结构设计能有更本质,更多元的发展!
如果大家觉得文章内容有帮助,欢迎大家转发,关注我们的工作,star开源的代码!也欢迎大家一起讨论!
上述论文PDF和代码下载
后台回复:Involution ,即可下载上述论文PDF和代码
后台回复:CVPR2021,即可下载CVPR 2021论文和开源代码合集
重磅!CVer-目标检测交流群成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,也可申请加入CVer大群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、Transformer、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,才能通过且邀请进群

▲长按加微信群
▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看!