Pytorch入门学习笔记,机器学习模型训练流程,从入门到放弃
Pytorch学习笔记
【小土堆】 视频链接:https://www.bilibili.com/video/BV1hE411t7RN?p=1
1. torchvision数据集dataset的使用
import torchvision
train_set = torchvision.datasets.CIFAR10(root="../dataset", train=True,
transform=data_transforms, download=True) #下载训练集
test_set = torchvision.datasets.CIFAR10(root="../dataset", train=False,
transform=data_transforms, download=True) #下载测试集
print(test_set[0])
print(test_set.classes)
img, target = test_set[0]
print(img)
print(target)
img.show()
2. DataLoader的使用
test_dataloader = DataLoader(dataset=test_set, batch_size=64, shuffle=True,
num_workers=0, drop_last=False)
# batch_size 为每次加载的数量
# shuffle为true表示每批次不同
# drop_last为false表示最后一次可加载部分图像
3. 神经网络的基本骨架 nn.Module的使用
input → forward → output #forward函数就是神经网络执行的步骤
class Tudui(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input):
output = input + 1
return output
tudui = Tudui()
x = torch.tensor(1.0)
output = tudui(x)
print(output)
4. nn.convolution的使用

展示conv2d的工作过程
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1], # weight
[0, 1, 0],
[2, 1, 0]])
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
output = F.conv2d(input, kernel, stride=1, padding=0)
#stride表示步长、padding为输入图像增加更多行列、kernel为卷积核心(weight)
print(output)
#输出为:
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
训练中使用conv2d函数
# 下载数据集
dateset = torchvision.datasets.CIFAR10("../data", train=False,
transform=torchvision.transforms.ToTensor(), download=True)
# 加载数据
dataloader = DataLoader(dateset, batch_size=64)
# 定义神经网络
class Tudui(nn.Module):
def __init__(self):
super().__init__()
#自定义方法,kernel_size只需要定义尺寸,具体数值由训练得出
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
for data in dataloader:
imgs, targets = data
output = tudui(imgs)
print(imgs.shape)
print(output.shape)
5. nn.MaxPool2d最大池化的使用
最大池化的作用
保留主要特征的同时减少参数(降低纬度,类似PCA)和计算量,防止过拟合
具体计算过程
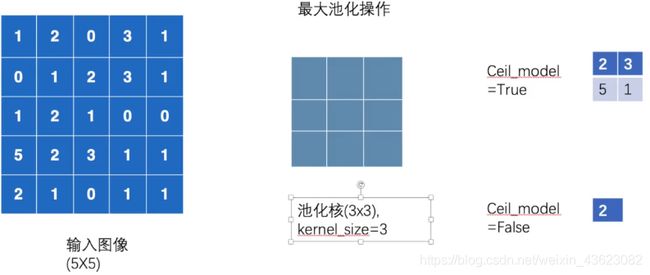
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32)
# input(N,C,H,W) N:batchsize, C:channel
input = torch.reshape(input, (-1, 1, 5, 5))
print(input.shape)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
tudui = Tudui()
output = tudui(input)
print(output)
# 输出
tensor([[[[2., 3.],
[5., 1.]]]])
6. 搭建小实战和sequential的使用

class Tudui(nn.Module):
def __init__(self):
super().__init__()
# Sequential把方法组合起来按顺序执行
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
tudui = Tudui()
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)
writer = SummaryWriter("logs_seq")
writer.add_graph(tudui, input)
writer.close()
7. 损失函数和优化器
损失函数的工作原理
input = torch.tensor([1, 2, 3], dtype=torch.float32)
target = torch.tensor([1, 2, 5], dtype=torch.float32)
input = torch.reshape(input, (1, 1, 1, 3))
target = torch.reshape(target, (1, 1, 1, 3))
loss = L1Loss()
result = loss(input, target)
print(result)
#计算过程
{(1-1)+(2-2)+(5-3)}/3 = 0.667
#输出结果
tensor(0.6667)
损失函数和优化器的使用
dataset = torchvision.datasets.CIFAR10(root="./dataset", train=False,
transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super().__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
tudui = Tudui()
# 定义损失函数
loss = nn.CrossEntropyLoss()
# 定义优化器
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
for opoc in range(20):
all_loss = 0
for data in dataloader:
imgs, target = data
output = tudui(imgs)
result_loss = loss(output, target)
# 优化器使用三部曲
optim.zero_grad() # 1
result_loss.backward() # 2
optim.step() # 3
all_loss = all_loss+result_loss
print(all_loss)
8. 模型修改
vgg16_true = torchvision.models.vgg16(pretrained=True) # 预训练模型
vgg16_false = torchvision.models.vgg16(pretrained=False)
print(vgg16_true)
vgg16_true.classifier.add_module("add_linear", nn.Linear(in_features=1000, out_features=10))
# vgg16_true.classifier[6] = nn.Linear(4096, 10)
print(vgg16_true)
9. 模型保存和加载
保存
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式1 # 模型结构+参数均保存
torch.save(vgg16, "vgg16_menthod1.pth")
# 保存方式2 #只保存参数字典(官方推荐)
torch.save(vgg16.state_dict(), "vgg16_method2.pth")
加载(与保存方式一一对应)
# 加载方式1 加载模型
model1 = torch.load("vgg16_menthod1.pth")
print(model1)
# 加载方式2 加载数据字典
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
# model2 = torch.load("vgg16_method2.pth")
print(vgg16)
陷阱
使用方式1加载模型时需要提供定义模型的类
10. 训练模型完整步骤(非常重要!!)
模型类
class Tudui(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
# 验证模型的正确性
if __name__ == '__main__':
tudui = Tudui()
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)
训练步骤
# 1 准备数据集
train_data = torchvision.datasets.CIFAR10(root="../dataset", train=True,
transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../dataset", train=False,
transform=torchvision.transforms.ToTensor(),download=True)
total_test_len = len(test_data)
# 2 利用DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 3 创建神经网络
tudui = Tudui()
# 4 设置前置需要的东西
# 设置参数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
epoch = 10 # 训练的轮数
write = SummaryWriter("../logs_train") # tensorboard
learning_rate = 0.01 # 训练步长,也可写成1e-2
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 5 开始训练
for i in range(epoch):
print("----------第{}轮训练开始----------".format(i + 1))
# 训练步骤开始
tudui.train()
for data in train_dataloader:
imgs, targets = data
output = tudui(imgs)
loss = loss_fn(output, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练了次数:{}, loss:{}".format(total_train_step, loss.item()))
write.add_scalar("train_loss", loss.item(), global_step=total_train_step)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
output = tudui(imgs)
loss = loss_fn(output, targets)
total_test_loss = total_test_loss + loss
accuracy = (output.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy / total_test_len))
write.add_scalar("test_loss", total_test_loss, global_step=total_train_step)
total_test_step = total_test_step + 1
# 6 保存模型
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
write.close()
测试准确率 (argmax的用法)
output = torch.tensor([[0.1, 0.2],
[0.05, 0.4]])
# 1 表示横着看 如 0.1< 0.2 所以值为1, 0.05<0.4 所以值为1 输出为[1,1]
print(output.argmax(1))
# 0 表示竖着看 如 0.1>0.02 所以值为0, 0.2<0.4 所以值为1,输出为[0,1]
print(output.argmax(0))
# 模型测试准确率用到的1横着看
preds = output.argmax(1)
targets = torch.tensor([0, 1])
print(preds == targets)
# 算出正确的个数,True为1,False为0
print((preds == targets).sum())
使用GPU训练
-
方法一 (.cuda方法)
# 1. 模型
tudui = tudui.cuda()
# 2. 损失函数
loss_fn = loss_fn.cuda()
# 3. 数据(输入、标注)
imgs = imgs.cuda()
targets = targets .cuda()
-
方法二 (.to方法)
device = torch.device("cpu") or torch.device("cuda:0")
# 严谨的写法
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 1. 模型
tudui = tudui.to(device)
# 2. 损失函数
loss_fn = loss_fn.to(device)
# 3. 数据(输入、标注)
imgs = imgs.to(device)
targets = targets.to(device)
11. 完整的模型验证套路
# 引入模型文件
from src.model import Tudui
image_path = "../imgs/airplan.png"
image = Image.open(image_path)
# png有四通道,使用convert变成三通道
image = image.convert('RGB')
# 改变尺寸 + 转换tensor类型
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()
])
image = transform(image)
# 在GPU上训练的对应到cpu需要设置 map_location
model = torch.load("tudui_36.pth", map_location=torch.device('cpu'))
print(model)
# 需要定义batchsize
image = torch.reshape(image, (1, 3, 32, 32))
# 使用no_grad可以节省资源
model.eval()
with torch.no_grad():
output = model(image)
print(output.argmax(1))
12. 小知识
Anaconda常用指令
创建环境: conda create -n "env_name" python=3.6
激活环境: conda activate name
环境地址: C:\Users\Administrator\Anaconda3\envs
查看package包:pip list
查找环境以及根目录:conda info --envs
打开图片的格式
| 打开方式 | Image.open(img_path) | transforms.ToTensor() | cv2.imread(img_path) |
|---|---|---|---|
| 数据类型 | PIL | tensor | numpy |
构建工具的使用

python中–call–函数的作用:python中call和init的区别
TensorBoard
-
TensorBoard有何作用
有效地展示tensorflow在运行过程中的计算图、各种指标随着时间的变化趋势以及训练中使用到的数据信息。
-
具体使用操作:
from torch.utils.tensorboard import SummaryWriter
write = SummaryWriter("p10")
for i in range(10):
img, target=test_set[i]
write.add_image("test_set", img, i) # img必须是tensor数据类型
write.close()
# 然后再在控制台输入:tensorboard --logdir="p10" 点击链接进入网页查看
transforms
-
作用: 对图片进行预处理
-
torchvision.transforms.Composese: 将一些方法组合起来
import torchvision
data_transforms = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Resize((512, 512))
])
-
快捷键
| Ctrl + P | Alt + Enter |
|---|---|
| 显示需要的参数类型 | 为报错提示解决方案 |
-
pycharm设置不区分大小写提示:file—setting—code Completion 将Math case取消
end…