过完618!来看看 Node.js 如何实现秒杀系统
前言
Coding 应当是一生的事业,而不仅仅是 30 岁的青春????
????????????,这篇文章接水怪很用心,也很硬核,相信能看完的都有点东西!!!????
作为一个在互联网公司面一次拿一次 Offer 的面霸,打败了无数竞争对手,每次都只能看到无数落寞的身影失望地离开,略感愧疚。
在一个寂寞难耐的夜晚,我痛定思痛,决定开始写面试相关的文章,希望能帮助各位读者以后面试势如破竹,对面试官进行 360° 的反击,吊打问你的面试官,让一同面试的竞争者瞠目结舌,疯狂收割大厂Offer!(请允许我使用一下夸张的修辞手法????)
文章的名字只是我的噱头,我们应该有一颗谦逊的心,所以希望大家怀着空杯心态好好学,一起进步????。
每篇文章都希望你能收获到东西,这篇是根据抢口罩的实际场景出发,逐层对一个高并发的系统进行分析,其中 Node 服务层会讲的相对详细一些,希望你看完,能够有这些收获:
Node 生态已经越来越好,一些高性能的 Web 业务场景,是完全可以用 Node 来做的
前端应该不止于前端,学习一些服务端的知识,不仅仅单方面的说是为了做一些全栈的系统,更多的是让现有的前端可以去做更多的事情,去尝试更多的可能
能够独立去设计一些东西,可以是一个微型全栈的系统,也可以是前端工程化中某个环节的工具
场景分析
真的打心底对那些在一线的工作人员点赞,接水怪的父亲目前仍在一线湖北提供生活物资的运输,我想说,爸,你真的很棒,怪怪为您感到自豪与骄傲!
想抢个口罩怎么就这么难!接水怪大学之前是湖北的,想给湖北的朋友抢个口罩快递过去,结果显而易见,没有抢到…
各大平台也相继开始了各种口罩秒杀活动,接水怪陆陆续续抢了快一个月了,还是没抢到~
于是,接水怪痛定思痛,下定决心对口罩秒杀系统架构一探究竟,虽然业界大部分的这种场景应该都是基于 Java 实现的,但是怪怪我决定尝试从 Node.js 的方向,配合业界一些成熟的中间件来分析一下整个系统的架构,以及一些常见的问题。
关于 Node.js 如何实现高并发的原理,怪怪往期的文章有写哈。????
写之前跟好兄弟丙丙也请教了不少后端侧的东西,对,就是你们熟悉的那个男人,号称自己在互联网苟且偷生的那个敖丙!
怪怪在这里将前后端一并分享给大家,毕竟 Node 的生态环境日益增强,前端侧能做的东西也越来越多。
比如你想在公司自己做一个基于 Node 的前端发布系统,也会涉及到 db,缓存,消息中间件这些东西。

接下来,让我们请出今天的主角儿,当当当当~~ 它就是低调奢华有内涵的口罩秒杀系统架构图,后面的内容会基于这个架构图来摆会儿龙门阵。
摆龙门阵,怪怪方言,也就是怪怪想跟大家聊会儿天的意思啦~)
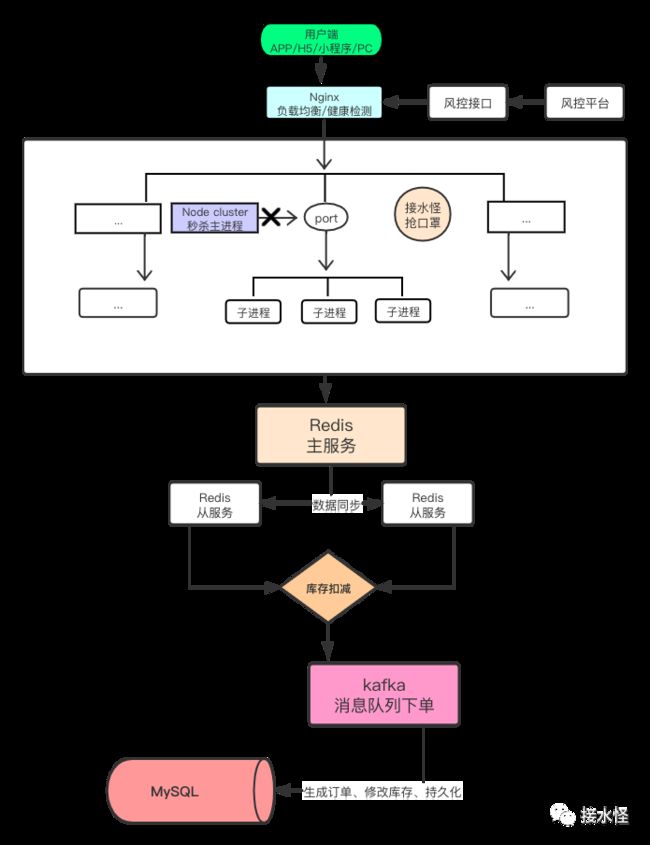
秒杀类型的业务为什么难做
秒杀,秒杀,顾名思义就是一个短时间内的高流量操作,是一个天然高并发的场景,换句话说,读写冲突十分严重。
而通常秒杀类型的业务,价格都比较诱人,这就引发了另外一个薅羊毛的问题,有不少黄牛会在这个时候趁机捞一笔,想必每年春节回家,大家都深有感触吧,还没来得及输完 12306 的高智商验证码,票已经没有了,哦豁~~
"哦豁",怪怪的方言,很无奈,很惊讶的意思

试想几十万,上百万的流量直接打到 DB?
世界突然安静,不得不再一次发出熟悉的感慨,哦豁~

因此,秒杀的核心就在于请求是真实请求的前提下,处理好高并发以及数据库存扣减的问题。
接下来,就让我们逐层来看看是怎么做的~
业务规则层面
针对流量特别大的场景,可以分时分段开展活动,原来统一 10 点抢口罩,现在 6 点,6 点半,7 点,…每隔半个小时进行一次活动,达到流量摊匀的效果。
前端层面
APP / H5 / 小程序 / PC
针对平民老百姓
前端侧会进行一个按钮置灰的操作,当你点击完一次之后,按钮会变灰,防止用户重复提交抢口罩的请求。
针对程序员
想必你一定会说,这还不简单?抓个包,写个定时脚本,一到时间,for 循环自动打请求不就好了?
我只能说,小伙子,你很优秀,有的场景确实是阔以滴,比如之前女孩子们疯抢的九价 HPV 宫颈癌疫苗,想必有不少女孩子都让程序员小哥哥帮忙写脚本,抢疫苗,怪怪我亲眼目睹,我们团队一位前端小哥哥用 Node 定时脚本抢到啦~

别着急,刚刚就是让你皮一下,哦豁~
针对上面这种情况,后端 controller 层会进行处理,简单来说就是对同一个用户抢口罩的请求进行校验,对于同一个用户在短时间内发送的大量请求进行次数限制,以及请求去重处理~
但怪怪我咨询了风控的朋友,现在企业中大部分场景,后端是不做这个特殊处理,而是让风控团队来处理,下面所谓黑客的部分会稍微细说一下。
道高一尺,魔高一丈,接下来请出我们的终极大魔王,高端黑客!!
针对更加高端的黑客们
比如一些高端黑客,控制了 30w 个肉鸡,也就是这些人手上有 30w 的 uid,如果他们同时发动手上 30w 的肉鸡来抢口罩,咋办?
此时,再一次陷入了尴尬~ 哦豁~~
这个问题,怪怪我咨询了安全、以及风控的朋友,简单跟大家分享一下
首先,安全针对秒杀,没做啥特殊的处理。
一般来讲,秒杀类工作主要在风控这边,对于那种利用机器或者脚本疯狂刷新的,QPS 异常高的,换句话说就是短时间内流量异常高滴的用户,会直接给他弹一个滑块(滑动验证,应该大家都遇到过这种情况),这样可以大大提高那些刷请求批量操作的成本,甚至能够遏制他们的行为。
同时风控也会根据一系列的规则(通过这些规则来判定这个 uid 也就是这个用户是否符合要求,不要问我具体规则,怪怪我还想继续写文章,不想进去~~),对于那些不符合平台下单要求的肉鸡,直接进行请求拦截,甚至有的会加入黑名单,直接取消掉这个用户的相关权限。
写到这里,我想说,风控、安全团队,你们还是有点东西!!

Nginx 层
实际上真正的企业架构中,在 Nginx 的上面一层还会有一层 lvs ,这里不展开讲,简单解释就是能够在网络第 4 层对 Nginx 服务的 ip 进行负载均衡
虽然上面我们拦截了恶意请求,减少了部分流量,但秒杀真实的用户也超多的啊,你想想这次有多少人在抢口罩!
所以我们我们还是要搞负载均衡~~
我们先简单解释一下集群跟负载均衡是个什么玩意儿,哦豁~
集群嘛,简单来讲就是我们不是有秒杀的 Node 服务嘛,那一台机器是不是有可能会挂掉,流量太大,单台机器根本扛不住,咋办?
加机器呗,一台会被打挂,那我们多搞几台,不就变强啦?俗话说,1 根牙签一折就断,10 根牙签…… 咦,好像也是一折就断,hhhh,哦豁~
那负载均衡是嘛玩意儿嘛?刚上面不是说了集群就是加机器嘛,那现在机器虽然变多了,来了一个请求,具体派哪个机器去处理,是不是得有一套规则嘛,并且这套规则要让请求分发的比较合理,不然就失去了集群的意义了撒~
Nginx 层下面是基于 Node 的 service 层,也就是业务逻辑会在这里进行处理,实际上 Nginx 在这里主要做了两件事:
对于前端打过来的真实的抢口罩请求,在 Nginx 这里进行请求的分发,打到 Node 集群的某一个机器上
健康检测,Node 集群的机器同样有可能挂掉,所以会利用 Nginx 进行检测,发现挂了的机器,会干掉重启,保证集群的高可用。检测有两种机制,被动检测跟主动检测,不展开说,后面会出一篇 Nginx 原理与实战的文章,像跨域啊,项目部署啊,自己搞个代理啥的啊,都可以用 Nginx 来搞,哦豁~
Node Service 层
这一层我会说的细一些,让我们挨个来摆下龙门阵吧~~
首先,为什么选择 Node 来做 service 层
想必大家都知道服务模型是经历了 4 个阶段滴,同步、复制进程、多线程、以及事件驱动。
不清楚的同学需要补补作业啦~
多线程目前业界以 Java 为首,性能啥的就不说了,各种双十一已经证明这位兄台是个狠人。
但是,怪怪我觉得,虽然多线程之间可以共享数据,内存可以充分利用,并且利用线程池可以较少创建和销毁线程,节省开销。但是,还是存在一些问题,比如:
操作系统在切换线程的时候,同样需要切换线程上下文,如果线程数量太多,切换线程会花费大量时间
多线程之间的数据一致性问题,各种加锁的神仙操作,也容易出问题
那能不能让我们人见人爱滴小阔爱,Node 小朋友,来尝试搞一下?

Node 是基于事件驱动模型滴,相信前端同学都知道事件驱动,后端同学可能有点懵,但是作为后端同学,Node 你没搞过,Nginx 你总用过哈,Node 跟 Nginx 都是基于事件驱动模型滴~
并且,Node 是单线程,采用单线程可以避免不必要的内存开销,以及上下文切换。
跟多线程 Java 比起来,好像 Node 也有自己的优势呢~
我知道,已经有不少同学迫不及待要接着问我了,尤其是后端同学心里肯定在想,你 TM 逗我呢,你一个单线程还能来搞高并发,多核 CPU 怎么利用?
毕竟隔行如隔山,后端大佬对我们 Node 有误解,也是情有可原,就跟很多前端觉得 Java 用类型检测是很麻烦的,不如我们 JS 灵活,是一个道理~
如果我们 Node 解决了多核 CPU 的资源利用问题,再加上 Node 异步非阻塞的特性,带来的性能上的提升应该是很不错滴,并且也没有复杂的多线程啊,加锁这一类心累的问题。
关于 Node 单线程如何实现高并发,可以查看往期文章哦????
Node Master-Worker 模式
我们顺着架构图,一步步来分析~
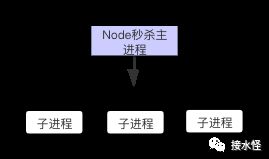
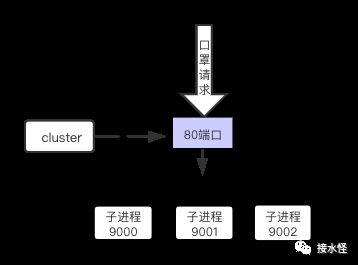
先看这里,说好的单进程,单线程呢,这是个什么鬼?
别着急,这是 Node 进程模型中著名滴 Master-Worker 模式哦~
还不是因为单线程,无法利用多核 CPU 嘛,我们的小阔爱 Node 提供了 child_process 模块,或者说 cluster 模块也行,可以利用 child_process 模块直接创建子进程。
说到这里, HTML5 提出的 Web Worker ,方式大同小异,解决了 JavaScript 主线程与 UI 渲染共用一个线程所引发的两者相互阻塞的问题。
cluster 模块:实际上就是 child_process 模块跟其它模块的组合
另外申明一点:fork 线程开销是比较大的,要谨慎使用,并且我们 fork 进程是为了利用 CPU 资源,跟高并发没啥大关系
这样看来,多核 CPU 的资源利用问题,好像得到了解决,虽然看起来方式稍显粗暴~

我们再次回归到上面的主、子进程的架构图,接着谈谈主进程与子进程通信的问题,现在一个口罩秒杀请求过来了,Node 主进程,子进程这里是怎么进行处理的呢?
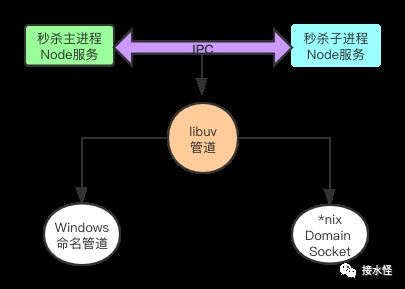
主-子进程通信
想必大家都知道 IPC,也就是进程间通信,首先要申明的是实现 IPC 的方式不止一种,比如共享内存啊、信号量啊等等~~
而 Node 是基于管道技术实现滴,管道是啥?
在 Node 中管道只是属于抽象层面的一个叫法而已,具体的实现都扔给一个叫 libuv 的家伙去搞啦~之前的文章有讲到 Node 的 3 层架构,libuv 是在最下层滴哦,并且大家都知道 Node 可以跨平台嘛,libuv 会针对不同的平台,采用不同的方式实现进程间的通信。
ok,我们上面大致说完了理论部分,是不是要实战一把了?
客户端请求代理转发
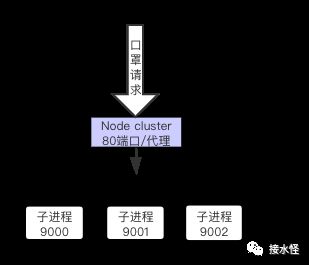
一把大叉叉什么鬼?说明通过代理请求转发这种方式是不太友好滴~
那我们具体分析一下,为什么不友好,怎么改进?
首先我们需要明确一点,操作系统有一个叫文件描述符的东西,这个涉及到操作系统内核的一些小知识点,并且操作系统的文件描述符是有限的,维护起来也是需要成本滴,因此不能铺张浪费~
那我们分析一下上面的流程,这些口罩请求打到主进程上面,主进程对这些请求进行代理,转发到不同端口的子进程上,看起来一切都那么美好~
并且在主进程这里,我们还可以继续进行一层负载均衡,让每个子进程的任务更加合理。

but,but,接下来是重点!!
前面我们说啦,操作系统的文件描述符不能铺张浪费,我们来看看这个代理的方式,有没有浪费~
首先,需要明确一点。进程每收到一个连接,就会用到一个文件操作符,所以呢?来,怪怪给你整个当字开头的排比句!
当客户端连接到主进程的时候,用掉一个操作符~
当主进程连接到子进程,又用掉一个~
所以嘛,从数量上来看,代理方案浪费掉了整整一倍,这好像不太科学,囊个搞内?
怪怪那儿的方言,“囊个搞”,就是怎么办的意思咯~~
魔高一尺,道高一丈~
句柄传递-去除代理
Node 在 v0.5.9 引入了进程间发送句柄的机制,简单解释一下,句柄实际上就是一种可以用来标识资源的引用。
通过句柄传递,我们就可以去掉代理这种方案。使主进程收到客户端的请求之后,将这个请求直接发送给工作进程,而不是重新与子进程之间建立新的连接来转发数据。
但实际上这一块还涉及到很多知识点,比如句柄的发送与还原啊,端口的共同监听啊等系列问题。
这一块的具体实现,可以参考 《深入浅出 Node.js 》9.2.3 句柄传递
最终,通过句柄传递就可以得到我们想要的效果,即不经过代理,子进程直接响应了客户端的请求。
怪怪我也去研究了一下 Egg.js 在多进程模型和进程间通信这块是怎么做滴,大体架构思路跟上面差不多,不同的点在于, Egg.js 搞了一个叫 Agent 的东西。
对于一些后台运行的重复逻辑,Egg.js 将它们放到了一个单独的进程上去执行,这个进程就叫 Agent Worker,简称 Agent,专门用来处理一些公共事务,具体细节可以参考 Egg.js 官网。
子进程服务高可用问题
毕竟是秒杀服务,fork 的子进程是可能挂滴,所以我们需要一种机制来保证子进程的高可用。
我知道,你肯定会说,挂了,重启一个继续提供服务不就好了?
对,你说的没错,我们就先来搞定重启这一趴~
假如现在某个子进程发生异常啦,哦豁~
那么,此时这个子进程会立即停止接受新的请求连接,直到所有连接断开,当这个子进程退出的时候主进程会监听到一个 exit() 事件,然后主进程重启一个子进程来进行补偿。
也就是这样一个流程。
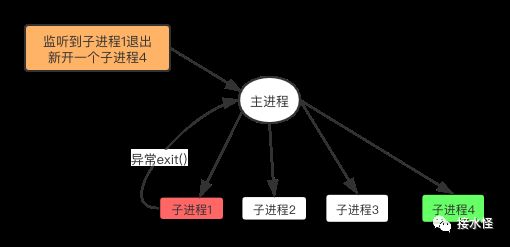
小伙子,你很不错,但是极端情况我们是不是也要考虑一下子?
假如有一天,出现极端情况,你所有的女朋友一夜之间都要跟你分手,是不是开始慌了?(坏笑~~)
如果所有的子进程同时异常了,按照我们上面的处理方式,所有的子进程都停止接收新的请求,整个服务岂不是就会出现瞬时瘫痪的现象了?大部分的新请求就会白白丢掉,想想如果是双十一,损失得有多大,哦豁~
既然如此,我们就来改进一下。
有的小伙伴可能会说,我知道怎么搞了!!!
既然不能一直等待着,那就直接暴力 kill 干掉这个进程,然后立马重启一个!!
小伙子,你有点激动,不过可以理解,毕竟能想到这里,你还是有点东西~~ 不过可以更加全面一点
暴力 kill 掉,会导致已连接的用户直接中断,那用户也就自然离开啦~ 哦豁~
所以,总结起来我们要解决的就是,如何在不丢失现有用户请求的基础上,重启新的子进程,从而保证业务跟系统的双重高可用!!!

忽然灵光一现,我们可以这样搞撒~
上面分析到主进程要等到子进程退出的时候,才会去重启新的子进程,这就有点意思啦!!同志,不要等到分手了再去反思自己哪里做的不对!!!,只要女朋友一生气,即使响应,立马认错,没毛病~~~
因此,我们可以在子进程刚出异常的时候,就给主进程发一个自杀信号,主进程收到信号后,立即创建新的子进程,这样上面的问题完美解决!!
从此跟女朋友过上了幸福美好滴生活~

Node 集群
搞定了上述秒杀服务 Node 主进程,子进程高可用的问题之后,我们就可以搭建 Node 集群了,进一步提高整个系统的高可用,Node 集群的负载均衡,文章一开始的 Nginx 层已经讲过啦~
至于集群做多大,用多少台机器,这些需要根据具体的业务场景来决策。并且一般大型的活动上线之前,企业内部会进行几轮压测,简单来讲,就是模拟用户高并发的流量请求,然后看一下小伙子你搞的这个系统抗不扛得住,靠不靠谱~
但真正的压测,远比我说的要复杂,比如压测中某个环节出了问题,扛不住啦,是直接重启机器,还是扩容,又或者是降低处理等等,这都是需要综合考虑滴~
当然,最终的目的也是在保证服务高可用的前提下能给企业节约成本,毕竟加机器扩容是需要成本滴~
同样的需求,别人要 5 台机器,你只要 4 台就能搞定,小伙子,那你就真的有点东西啦,升职加薪指日可待!!~

数据一致性
搞定了上面 Node 服务的各个环节之后,还有一个很重要的问题要解决,我丢!!!咋还有问题~~
首先,明确一个知识点,Node 多个进程之间是不允许共享数据滴~
这就是最后一个非常重要的问题,数据共享。
实际业务中,就拿我们今天的口罩系统来说,库存量就是一个典型数据共享的场景,会有多个进程需要知道现在还有多少库存,不解决好这个问题,就很有可能发生口罩超卖的问题。
超卖,简单来讲就是,怪怪家一共有 200 只口罩等待出售,然后怪怪我在某平台上发起了一个秒杀抢口罩的活动,由于平台的数据没处理好,怪怪我在后台惊喜的收到了 500 个订单,超出了 300 个订单,这就是超卖现象啦~
那这个问题,我们应该如何避免呢,怪怪我有点心累,买个口罩怎么这么复杂!
既然 Node 本身不支持数据共享,ok,那我们就用三方的嘛,比如今天的第二个主角~ 当当当当~~ 它就是一位名叫 Redis 的神秘女子,身穿红色外套,看着还有点内敛~
至于 Redis 这里如何保持数据一致,放到下面 Redis 的部分一起说。

Redis 层
我们使用 Redis 解决上述遗留的 Node 进程间数据不能共享的问题。
解决问题之前,先简单介绍一下 Redis ,毕竟,都不认识,怎么开始恋爱?
Redis 还是有很多知识点滴,具体可查看 Redis 官网
相信大家在大学的时候都接触过 SQL Server ,相信你也曾经因为 SQL Server 那诡异的环境曾头痛~
但大部分学校,应该都是没有 Redis 这门课滴,如果有,怪怪我只能说,朋友,你的学校有点东西!!
步入正题,Redis 是一个在内存中进行数据结构存储的系统,可以用作数据库、缓存和消息中间件,是 key-value 的形式来进行数据的读写。简单理解就是,我们可以利用 Redis 加缓存减轻 db 的压力,提升用户读写的速度。
大家要明确的是,秒杀的本质就是对库存的抢夺,如果每个从上层 Node 服务打过来的请求,都直接去 db 进行处理,
抛开最大的性能问题先不说,你不觉得这样好繁琐,对开发人员以及后期的维护都很不友好嘛?
那咋办
上面已经说啦,直接搞到 MySQL 扛不住,你可以找她闺蜜 Redis 嘛,写一个定时脚本,在秒杀还未开始之前,就把当前口罩的库存数量写入 Redis,让 Node 服务的请求从 Redis 这里拿数据进行处理,然后异步的往 kafka 消息队列里面写入抢到口罩用户的订单信息(这一块具体的放到后面 kafka 消息队列部分分析)。
那这里就关联上了我们前面提到的问题,数据一致性问题,如何保证 Node 服务从你 Redis 拿到的库存量是没有问题滴?
如果直接按正常的逻辑去写,抢到口罩,Redis 中库存 count -1,这种方式看起来是没有问题滴,但是我们来思考这样一个场景。
比如仓库里面还有最后 1 个口燥,现在光头强发了一个请求过来,读了一下 Redis 的数据,count 为 1,然后点击下单,count - 1 。但如果此时 count 正在执行 -1 的操作的时候(此时 count 依然是 1 ),熊大哥哥一看这形式不对,也开始抢口罩,一个查库存量的请求再一次打了过来,发现 Redis 中库存量仍然为 1 ,然后点击下单。
按上述的流程,就会发生文章一开头提到的超卖现象,1 只口罩,你给我下了两个单?!!!
这又咋办

我们可以加事务嘛!!
事务可以一次执行多个命令,并且有两个很重要的特性~
事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断
事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
这里直接引用 Redis 的官方示例来解决超卖问题,官方示例讲的是执行 +1 的操作,我们这里只需要修改成 -1 就 ok。具体可参考官方文档。

这样一来,Node 数据共享,库存减叩的问题就搞定了,Redis 小姐姐,你有点东西!!~
那如果单台 Redis 扛不住怎么办,我们可以对 Redis 进行集群嘛,主从同步这一系列的操作,然后再搞点哨兵,持久化也搞上,那你这个秒杀直接无敌!!!
后续有时间,会写一个基于 Node.js 的 Redis 实战与原理剖析????,之前怪怪写过一个可视化页面搭建系统,其中各个模块在后台进行渲染的时候,为了提高渲染速度,就用到了 Redis 进行高速缓存。
缓存这一趴告一段落,下面接着说说消息队列~
kafka 消息队列层
如果将订单数据一次性全部写入 db,性能不好,所以会先往消息队列里面存一下,当然消息队列不仅仅是起到了这个作用,像什么应用的解耦,也可以基于 kafka 来做一层封装处理。
先简单说一下消息队列,不光秒杀,其它场景的使用大同小异。
kafka 消息队列就是基于生产者-消设计模式滴,按具体场景与规则,针对上层请求让生产者往队列的末尾添加数据,让多个消费者从队列里面依次读取数据然后自行处理。
结合到我们的秒杀场景就是,对订单进行分组存储管理,然后让多个消费者来进行消费,也就是把订单信息写入 db。
这里附上一张经典的消息队列的图,有兴趣的小伙伴可以深入去了解 kafka,还是有点东西。
 kafka
kafka
MySQL 数据库层
数据库这块不多说,数据存储的地方,最终的订单信息会写到 MySQL 中进行持久化存储。
简单模拟这个系统的话,表结构就搞到最简化就行。
CREATE TABLE IF NOT EXISTS `seckill`(
`id` INT UNSIGNED AUTO_INCREMENT,
`date` TIMESTAMP,
`stock` INT UNSIGNED,
PRIMARY KEY ( `id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
深入学习 MySQL,还是有些东西滴,查询优化啊,索引怎么用啊,底层数据结构啊,怎么去设计表啊等等一些列问题都可以去探究~
相信前段时间搞的沸沸扬扬滴删库跑路事件,大家也都听说了~~
顺便提一嘴,很多小伙伴说,我想搞一下前端工程化,我想搞几个减少开发流程的系统,我想…
就举个很简单的例子,企业都有线下、预发、线上这一套环境,你想开发一款 host 切换工具来切各个不同的环境,两种方式:
直接基于 Electron 写一个本地 host 文件(etc/hosts)读写的工具,看似也没什么毛病
但既然是整个公司用,那思维就不要太局限啦,如果仅仅开发一个本地 host 文件读写的工具,那没什么意思,大家直接用开源的不就好了,还节省成本,不用开发。
做成可配置滴,公共的 host 配置文件存到 db,并且支持本地自定义配置,这就很棒啊,全公司统一。假如哪天预发的机器 ip 变了,那么只用去 host 工具管理后台更新一下,全公司所有的小伙伴就可以一键更新啊,是不是很爽??
怪怪之前是维护我们公司的这个 host 小工具滴,后面计划自己写一套开源出来。
什么,这么个破玩意儿你还要开源?

举上面的例子,就是想说,Node 生态越来越好,我们前端能做的事情也越来越多,我们有义务去接触更多的东西,寻找更多前端的突破口~
狼叔那一篇在 cnode 社区置顶的文章,就写的非常赞!!~~~
踩过的坑-经验分享
能够看到这里,说明你有点东西,整个系统的各个层都讲了一下,我估计现在让你自己来搞一个秒杀系统,也问题不大了~
怪怪我基于文章开头的架构图,自己搞了一个低配版的 Node 秒杀系统,在这里把踩过的一些小坑跟大家分享一下,毕竟踩过的坑,不希望大家踩第二次!
首先,如果大家自己在本地搞这个系统,可能乍一看,又有 Node,又有 Nginx,又有 Redis ,又有 kafka,而且管理 kafka 还要用 zookeeper,感觉这也太麻烦了,可能看到这个环境搭建都望而却步了~。
淡定,淡定!!
我们可以用 docker 来搞嘛,这样就很轻量并且很方便管理,没用过的小伙伴强烈建议去学习一下~
使用 docker 来搞,上面说的几个环境,一个配置文件就搞定,简单示意一下:
services:
zk:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
kfk:
image: wurstmeister/kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 172.17.36.250
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- ./docker.sock:/var/run/docker.sock
redis:
image: redis
ports:
- "6379:6379"
mysql:
image: mysql
ports:
- "3306:3306"
environment:
MYSQL_ROOT_PASSWORD: 'password'
遇到过坑的小总结
用 docker 搭建环境,避免自己去装那些不必要的环境,比如 MySQL。
使用 Docker Compose 定义和运行多容器的 Docker 应用程序,便于容器的集中配置管理。
删除 Docker 容器,容器里面的数据还是会在你物理机上面,除非你手动去清理。
kafka-node 这个 npm 包,最新的版本用法相比老版本有一些更新,比如老版本创建一个 kafkaClient 的写法是 new kafka.Client(); 但新版本现在已经是 new kafka.KafkaClient(); 这种写法了
kafka 的 docker 镜像,官方提供的 docker-compose 示例未指定端口映射关系,需要自行处理一下映射关系
Egg.js 首次在连接 MySQL 的 docker 容器的时候,会出现 Client does not support authentication protocol requested by server; 的异常,修改一下密码就 ok。 ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'your_new_password'; FLUSH PRIVILEGES;
被后端朋友灵魂 3 问的小分享
如果是一家很小的公司,由于资金问题机器不够用来集群怎么办
万一机器不够,只能放弃部分请求,原则上还是要已保护系统为核心,不然所有的请求都失败,就更不理想
kafka 队列这边如果发生异常处理失败怎么反馈给用户
那就给用户及时反馈说下单失败,让用户重试,都已经抢到口罩了,重新下个单应该问题不大的,再者,这是少数情况~
抢到口罩之后未及时支付或取消这笔订单,如何对剩余库存做及时的处理呢
首先,抢到口罩之后,支付界面会有一个支付的时间提醒,例如,超过 20 分钟未支出,这笔订单将被取消。关联到数据库里就会有一个未支出的状态。如果超过时间,库存将会重新恢复。
前端侧也会给到用户对应的提示,比如 20 分钟之后再试试看,说不定又有口燥了哟~
总结
回过头再去看看文章开头的系统架构图,相信你会有不一样的收获~
怪怪上面写的也不全,真正的企业实战,整个链路会复杂很多,环环相扣。比如 Node 服务的监控报警啊,各种异常处理啊等等~~
后续会对这篇秒杀中的知识点进行拆分深入探究,比如进程,线程这块从最基本概念到最底层内核的一些知识都会来跟大家分享。
❤️爱心三连击1.看到这里了就点个在看支持下吧,你的「在看」是我创作的动力。
2.关注公众号程序员成长指北,「带你一起学Node」!
3.特殊阶段,带好口罩,做好个人防护。
4.添加微信【ikoala520】,拉你进技术交流群一起学习。
“在看转发”是最大的支持