Inception V1:Going deeper with convolutions
参考来源:
http://blog.csdn.net/stdcoutzyx/article/details/40759903
https://www.cnblogs.com/jie-dcai/p/5727122.html
http://blog.csdn.net/stdcoutzyx/article/details/51052847
http://blog.csdn.net/mounty_fsc/article/details/51746111
一、主要贡献:
针对ILSVRC14比赛提出了一个名叫Inception的深度卷积网络架构,其具体化的成果为GoogLeNet,是22层深的网络。主要是通过充分利用网络内的计算资源来优化网络性能,具体是不增加计算资源需求的前提下增加网络的宽度与深度。
小尺寸滤波器组合+1*1滤波器降维。
二、相关工作:
本文提出的网络结构为Inception,得名于参考文献[12](network in network)。
Recent trend of CNN is to increase the number of layers and layer size, while using dropout to address the problem of overfitting。
参考文献[15]使用一系列不同大小固定的Gabor过滤器来处理多尺度问题,同Inception Model类似。
本文借鉴参考论文[12],使用了很多1×1的卷积核。卷积核在本文中的作用主要在于降维以打破计算瓶颈。使得不仅可以加深网络,同时还可以加宽,而不造成严重的性能下降。
三、背景:
3.1 最直接提高深度神经网络性能的方法
增加网络的宽度与深度,包括通过增加层数以增大深度,通过增加每一层的节点数以增加宽度。
然而这种解决方法有两大缺陷:
1)更大的网络规模需要更多的参数,当训练集标签样例有限时,更易过拟合。
2)计算资源需求的暴增。如果增加的计算力没有被有效使用(比如大部分的权值趋于0),会浪费计算资源。
3.2 解决:把全连接改成稀疏连接的结构
理论依据(Arora 参考文献[2]):数据集的概率分布可用一个稀疏的大型深度神经网络表达,最优的拓扑结构通过分析上层激活函数的统计相关性,并将高度相关性的输出神经元聚类,而将网络一层一层地搭建起来。这与生物学中Hebbian原则“有些神经元响应基本一致,即同时兴奋或抑制”一致。
转自百度百科:Hebb 学习规则是一个无监督学习规则,这种学习的结果是使网络能够提取训练集的统计特性,从而把输入信息按照它们的相似性程度划分为若干类。这一点与人类观察和认识世界的过程非常吻合,人类观察和认识世界在相当程度上就是在根据事物的统计特征进行分类。Hebb 学习规则只根据神经元连接间的激活水平改变权值,因此这种方法又称为相关学习或并联学习。
存在问题:计算机的基础结构在遇到大量非均一(non-uniform)稀疏数据计算时会很不高效,使用稀疏矩阵会使得效率大大降低。
目标:设计一种既能利用稀疏性,又可以进行密集矩阵计算的网络结构-Inception
四、Inception模型:
The main idean of the Inception architecture is based on finding out how an optimal local sparse structure in a convolutional vision network can be approximated and covered b readily available dense components.
Inception 模块是一层一层往上栈式堆叠的,所以它们输出的关联性统计会产生变化:更高层抽象的特征会由更高层次所捕获,而它们的空间聚集度会随之降低,因此随着层次的升高,3×3 和5×5的卷积的比例也会随之升高。(较低的层次对应着图像的某个区域,使用1×1的卷积核仍然对应这个区域,使用3×3的卷积核,可以得到更高层抽象的特征。)因而设计如图。
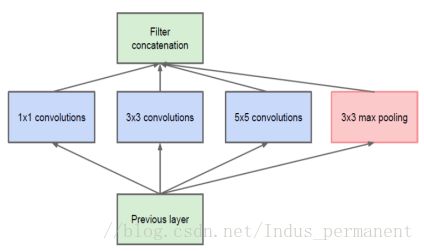
经过卷积后输出滤波器的个数与前面滤波器的个数相等。池化层输出与卷积层输出的合并会导致每步输出暴增。即使是这种结构覆盖了最优的稀疏结构,它可能依然还是很低效,从而导致少数几步的计算量就会爆炸式增长。使用NIN网络中提到的1×1的卷积核进行降维,在卷积层处理前,先对特征图层进行降维(注意是通道的降维,不是空间的降维),例如原本是M通道,降维到P通道后,在通过汇聚变成了M通道,这时参数的个数并没有随着深度的加深而指数级的增长。设计如图2。
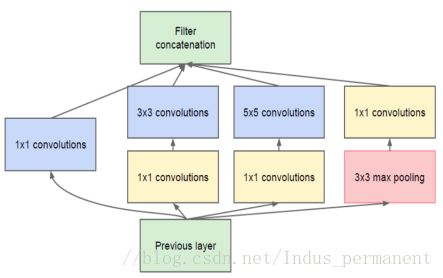
以GoogLeNet的3a模块为例:
输入的feature map是28×28×192,3a模块中1×1卷积通道为64,3×3卷积通道为128,5×5卷积通道为32,如果是左图结构,那么卷积核参数为1×1×192×64+3×3×192×128+5×5×192×32,而右图对3×3和5×5卷积层前分别加入了通道数为96和16的1×1卷积层,这样卷积核参数就变成了1×1×192×64+(1×1×192×96+3×3×96×128)+(1×1×192×16+5×5×16×32),参数大约减少到原来的三分之一。同时在并行pooling层后面加入1×1卷积层后也可以降低输出的feature map数量,左图pooling后feature map是不变的,再加卷积层得到的feature map,会使输出的feature map扩大到416,如果每个模块都这样,网络的输出会越来越大。而右图在pooling后面加了通道为32的1×1卷积,使得输出的feature map数降到了256。GoogLeNet利用1×1的卷积降维后,得到了更为紧凑的网络结构,虽然总共有22层,但是参数数量却只是8层的AlexNet的十二分之一(当然也有很大一部分原因是去掉了全连接层)。
对稀疏性的理解:
降维就是减少神经元的个数,比如原先28*28*512 在1*1*256之后就是28*28*256(stride为1的情况),这样整个网络结构在这一层就降维了,原作者发现在没有1*1之前的参数空间存在很多稀疏的数据,这里降维之后,参数空间会更dense,这样解决了稀疏性增大计算困难的问题。
这样做的合理性在于,Hebbin法则说“有些神经元同时兴奋或抑制”,而在区域中同一节点对应的区域(特征)可能一样,认为它们是相关的,所以通过1*1的卷积核将它们聚合(信息压缩)后再卷积,符合Arora的理论。
这一结构一个有利的方面是它允许每一步的神经元大量增加,而不会导致计算复杂度的暴增。降维的普遍存在能够阻挡大量来自上一层的数据涌入下一层的过滤器,在大区块上对其进行卷积之前就对其进行降维。
五、GoogleNet结构:
GoogLeNet网络有22层,最后一层使用了NIN网络中的全局平均池化层,但还是会加上FC层,再输入到softmax函数中。
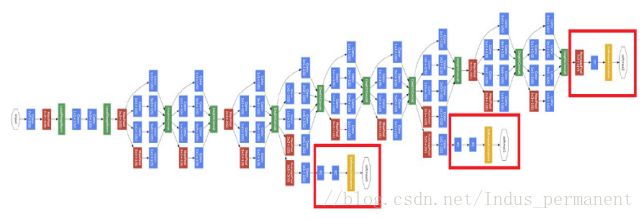

在深度加深的情况下,在BP算法执行时可能会使得某些梯度为0,这会使得网络的收敛变慢。论文中使用的方法是增加一些附加的分类器(Auxiliary Classifiers),在分类器的低层增加向后传播的梯度信号,同时增加更多的正则化。这样一些权值更新的梯度就会来自于多个部分的叠加,加速了网络的收敛。但预测时会把AC层去掉。
附加网络的结构,包括附加分类器的结构如下:
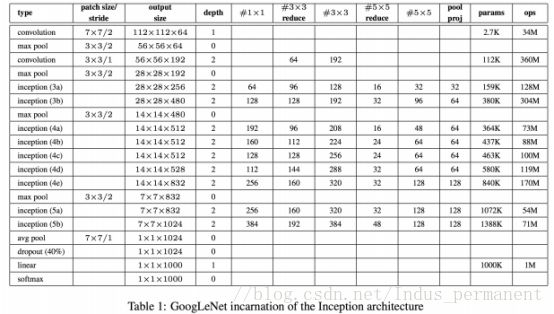
1)一个平均池化层,过滤器为5×5,步长为3,在 inception 4(a)得到一个4x4x512的输出,在4(d)得到一个4x4x528的输出。
2)一个1x1卷积,有128个过滤器,用于降维和规范化线性激活(dimension reduction and rectified linear activation)。
3)一个拥有1024个单元和规范化线性激活的全连接层。
4)一个会抛弃70%输出的DROPOUT层。
5)一个使用 softmax 偏差的线性层,这一层被用作分类器(与主分类器一样,它进行 1000类分类,但在预测阶段,它会被抛弃)
六、训练技术:
(1)Using DistBelief [4]distributed machine learning system with modest amount model and data parallelism.网络使用文献[4]提出的分布置信网络,将机器学习系统分布为合适数量的模型和数据并行.
(2)Training with asynchronous stochastic gradient descent with 0.9 momentum, fixed learning rate schedule(decreasing the learning rate by 4% every 8 epochs) and Polyak averaging[13]is used。练使用动量(momentum)为 0.9 的异步随机梯度下降,并将学习速率固定为每八次迭代减少 0.04。Polyak 均值[13]被用于建立在推理过程中使用的最终模型.
(3)Sampling of various sized patches of the image whose size is distributed evenly between 8% and 100% of the image area and whose aspect ratio is chosen randomly between 3/4 and 4/3.是将取样区块的大小平均分布在图片区域的8%到 100%之间,宽高比随机分布与3/4 和4/3之间。
(4)Photometric distortions光度变换对于对抗过拟合在某种程度上是很有用的
Using random interpolation methods for resizing relatively late and in conjunction with other hyperparameter changes.使用插入方法,以便在相对靠后的阶段重新确定取样大小,以及其他超系数的结合.
七、实验结果:
Trained 7 versions of same GoogLeNet model, performed ensembel prediction with them. These models are trained with the same initialization, but differ in sampling methodologies and the random order in which they see input images.独立训练了七个版本的相同的 GoogLeNet模型然后将其联立起来进行预测。这些模型训练基于相同的初始化(由于一个oversight,甚至初始权值都相同)及学习速率策略。
Testing: resize the image to 4 scales where the shorter dim is 256,288,320,352. Take the left, right, center square of these resized images, then take the 4 corners and the center 224×224 crop and the square resize 224×224, and their mirror version. Namely, 4×3×6×2=144 crops per image.将图片重设为四种不同的尺度(高和宽),分别是 256,288,320 和 352,包括左中右三块(如果肖像图,取顶中底三块)对于每一块,取其四角和中心,裁切出5个224x224 的区块,同时取其镜像。结果每张图就得到了4×3×6×2=144个区块。
Softmax probabilities are averaged over multiple crops and over all individual classifiers to obtain the final prediction. Simple averaged is the best.softmax 概率分布被平均到不同的裁切以及所有的单分类器上以获取最终的预测结果。比如各个裁切区块上的最大池化,以及对分类器取平均。但它们会导致比简单平均更差的表现.
结果如下:

八、结论:
approximating the expected optimal sparse structure by readily available dense building blocks is a viable method for improving neural networks for computer vision.The main advantage of this method is a significant quality gain at a modest increase of computational requirements compared to shallower and less wide networks.Although it is expected that similar quality of result can be achieved by much more expensive networks of similar depth and width, our approach yields solid evidence that moving to sparser architectures is feasible and useful idea in general. This suggest promising future work towards creating sparser and more refined structures in automated ways on the basis of [2].