孪生网络系列学习
论文
1.SiamFC.
2. SiamRPN.
3.SiamRPN++.
4.DaSiamRPN.
SiamFC
网络结构
所谓孪生结构,即为成对的结构,具体来说就是该结构有两个输入,一个是作为基准的模板,另一个则是要选择的候选样本。而在单目标跟踪任务中,作为基准的模板则是我们要跟踪的对象,通常选取的是视频序列第一帧中的目标对象,而候选样本则是之后每一帧中的图像搜索区域(search image),而孪生网络要做的就是找到之后每一帧中与第一帧中的范本最相似的候选区域,即为这一帧中的目标,这样就可以实现对一个目标的跟踪。孪生网络基本结构如下:
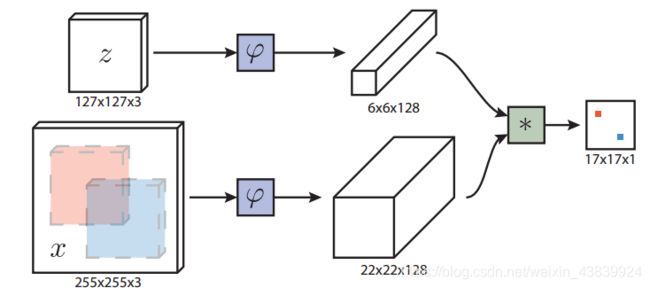

将第一帧图像目标作为模板图像z ,将后续个帧图像作为搜索图像x,通过一个学习好的相似性对比函数f(z,x)在x上找到和z最为相像的备选区域作为预测的目标位置。相似度对比函数f将会用一个标记好的数据集进行训练。作者用深度网络作为相似度对比函数f,将网络作为一种变换φ,首先将这种变换分别应用到模板和搜索图像上,产生模板和搜索区域的特征φ(z),φ(x),然后用另外一个相似度测量函数g将他们结合起f(z,x)=g(φ(z),φ(x))。
为了给出更精确的定义,给定Lτ是一种转换操作(Lτx)[u]=x[u−τ],函数h作为全卷积网络变换函数,k是全卷积网络变换的比例因子,则h(Lkτx)=Lτh(x),表示的含义是:先对x进行有比例因子的转换操作再进行全卷积操作等同于先对x进行全卷积操作再进行转换操作。给定每个位置的偏置参数b1,相似度对比函数还可以表示为f(z,x)=φ(z)∗φ(x)+b1,表示的含义是:模板区域z和搜索区域x经过相同的卷积操作φ()后,用∗操作并加上一定的偏置b1得到响应图。
在跟踪过程中,搜索图像是以上一帧目标为中心的,响应图由特征图进行互相关操作(等价于响应图的内积)生成,响应图最大的位置乘以网络的比例因子才是目标的最终位置。另外,作者使用不同尺度的图片作为一个mini-batch进行检测。
注意:SiamFC设计的网络结构将原始图像缩小了8倍,即k=8,并且,该网络没有padding。
训练过程
损失函数:

其中v是对一个样本候选区的打分值,y是此样本候选区的真实标签y∈{+1,−1}。响应图的损失被定义为响应图中每个位置损失的平均值。
最后,给定x和z是样本对,θ是参数,f是对样本对的打分,用SGD最小化如下损失函数来获得最佳的跟踪模型。
训练数据:作者用大规模搜索图像训练模型,训练数据是由样本对组成的,视频中的第一帧图像中的目标和该视频中的其他相差不超过T帧的图像组成了若干样本对(目标图像和后续帧都组成一个样本对)。每个样本对经过孪生网络生成响应图v[u]后,u∈D(u表示响应图中的每个位置),响应图每个位置对应的标签为y[u],y[u]的定义遵循如下规定,表示当响应图中某位置u和响应图中目标位置c的距离乘以比例因子k后小于R则为正样本。
数据处理:模板图像大小是127×127,搜索区域图像是255×255,给定目标尺寸(w,h),目标周围扩增p,其中p=(w+h)/4,对于模板图像A=1272,利用尺度变换s使得新的区域面积等于模板图像面积(s的变换方式是在原有尺寸不变的前提下填充原图RGB各通道均值像素),在预训练之前,将训练数据组织好以便提高训练速度。
训练细节:模型初始化参数用高斯分布初始化,共迭代50次,每次迭代包含50000个样本对,mini-batch为8,学习率每次迭代从10(−2)到10(−5)。
跟踪过程
只在大约四倍于先前大小的区域内搜索对象,并且在得分图中添加一个cos窗口来惩罚较大的位移。通过处理多个缩放版本的搜索图像,可以实现对缩放空间的跟踪。任何规模的变化都将受到惩罚,并对当前规模的更新进行阻尼。
结合时域信息约束;搜索目标在四倍目标区域;余弦窗口加在打分映射惩罚大的偏移。多尺度跟踪,增强尺度估计的准确性。
在跟踪过程中,初始帧目标的特征图只计算一次,然后它用来和后续帧的特征图进行比较,得到的响应图(得分图)。作者利用双三次插值将17×17的矩阵转换为272×272的矩阵,从而定位目标区域。另外,针对搜索图像,还用了5种尺度1.025({−2,−1,0,1,2}),这些尺度采用了以0.35为步长的线性函数作为抑制。
实验结果

SiamRPN
网络结构
在 CVPR18 的论文中(SiamRPN),商汤智能视频团队发现孪生网络无法对跟踪目标的形状进行调节。之前的跟踪算法更多的将跟踪问题抽象成比对问题,但是跟踪问题其实和检测问题也非常类似,对目标的定位与对目标框的回归预测一样重要。 研究人员分析了以往跟踪算法的缺陷并对其进行改进:
大多数的跟踪算法把跟踪考虑成定位问题,但它和检测问题也比较类似,对目标的定位和对目标边界框的回归预测一样重要。为此,SiamRPN 将跟踪问题抽象成单样本检测问题,即需要设计一个算法,使其能够通过第一帧的信息来初始化的一个局部检测器。为此,SiamRPN 结合了跟踪中的孪生网络和检测中的区域推荐网络:孪生网络实现对跟踪目标的适应,让算法可以利用被跟踪目标的信息,完成检测器的初始化;区域推荐网络可以让算法可以对目标位置进行更精准的预测。经过两者的结合,SiamRPN 可以进行端到端的训练。
以往的滤波类的方法,没办法通过数据驱动的形式提升跟踪的性能。而 SiamRPN 可以端到端训练,所以更大规模的数据集 Youtube-BB 也被引入到了训练中,通过数据驱动的形式提升最终的性能。
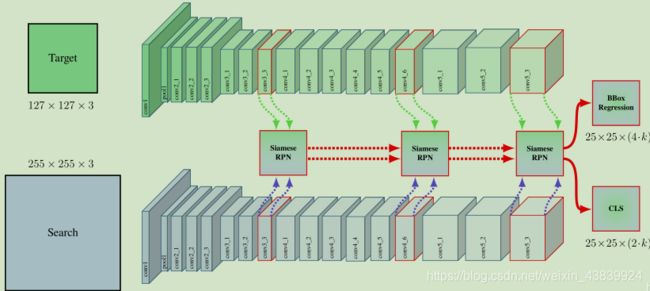
SiamRPN网络由Siamese Network和Region Proposal Network两部分组成。前者用来提取特征,后者用来产生候选区域。其中,RPN子网络由两个分支组成,一个是用来区分目标和背景的分类分支,另外一个是微调候选区域的回归分支。整个网络实现了端到端的训练。

RPN网络:
RPN网络由两部分组成,一部分是分类分支,用于区分目标和背景,另一部分是回归分支,它将候选区域进行微调。对于分类分支,它将给出每个样本被预测为目标和背景的打分。网络将用Siam网络提取到的模板和检测帧的特征用一个新的卷积核进行卷积,在缩小了特征图的同时,产生了如图大小为4×4×(2k×256)的模板帧特征[φ(z)]cls和大小为20×20×256的检测帧特征[φ(x)]cls,他们分别表示的含义是:模板帧特征大小是4×4,而且它在k种不同的anchors有k中变化,对每种变化的模板都产生一个特征;检测帧特征大小是20×20×256。然后,以模板帧的特征作为卷积核(2k个4×4×256)去卷积检测帧的特征从而产生响应图Aclsw×h。 回归分支和分类分支类似,不过它给出的是每个样本的位置回归值,这个位置回归值包含dx, dy, dw, dh四个值。
跟踪过程

检测帧在对每一帧目标进行检测时就是对proposals进行分类,即相当于一个分类器。该分类器进行分类时需要一个响应得分图,该响应图是由检测帧特征图用模板帧特征图作为卷积核进行卷积得到的。如上图灰色的方块,标识有weight for regression和weight for classification即为模板帧特征图,它用第一帧图像信息进行训练(即one-shot检测,只用第一帧图像信息训练出一层网络的参数),然后将训练好的参数作为卷积核用到检测支中,对检测帧特征进行卷积得到响应图,作者将模板支的输出作为本地检测的卷积核,在整个跟踪过程中,卷积核参数都是用第一帧信息提前计算好的,当前帧跟踪可以看做如上图所示的one-shot检测,提取出检测支中得分前M的样本的分类输出信息和回归输出信息。根据输出信息,可以得到前M个proposals的位置信息。
实验结果

SiamRPN++
网络结构
SiamFC, 通过相关操作,可以考虑成滑窗的形式计算每个位置的相似度。但带来了两个限制:
1.网络需要满足严格的平移不变性。如SiamFC中介绍的,padding会破坏这种性质。
2.网络有对称性,即如果将搜索区域图像和模板区域图像对调,输出的结果应该不变。(因为是相似度,所以应该有对称性)
因此认为,现代化网络破坏严格平移不变性以后,带来的弊端就是会学习到位置偏见:按照SiamFC的训练方法,正样本都在正中心,网络会学到这种统计特性,学到样本中正样本分布的情况。按照这个思想进行了实际的实验验证,在训练过程中,不再把正样本放在中心,而是以均匀分布的采样方式让目标在中心点附近进行偏移。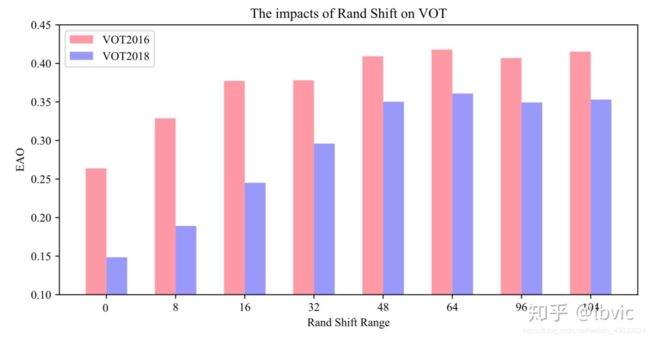
由上图可以看出,随着偏移的范围增大,深度网络的效果逐渐变好。所以说,通过均匀分布的采样方式让目标在中心点附近进行偏移,可以缓解网络因为破坏了严格平移不变性带来的影响,即消除了位置偏见,让现代化网络可以应用于跟踪中。
互相关的区别
Cross Correlation:用于SiamFC,模版特征在搜索区域上以滑窗的方式获取不同位置的响应。
Up-Channel Cross Correlation:用于SiamRPN,于Cross Correlation不同的是在做correlation前多了两个卷积层,一个提升维度(通道数),另一个保持不变。之后通过卷积的方式,得到最终的输出。通过控制升维的卷积来实现最终输出特征图的通道数。
Depthwise Cross Correlation:和UpChannel一样,在做correlation操作以前,模版和搜索分支会分别过一个卷积,但不需要提升维度,这里只是为了提供一个非Siamese的特征(SiamRPN中与SiamFC不同,比如回归分支,是非对称的,因为输出不是一个响应值;需要模版分支和搜索分支关注不同的内容)。在这之后,通过类似depthwise卷积的方法,逐通道计算correlation结果,这样的好处是可以得到一个通道数非1的输出,可以在后面添加一个普通的卷积就可以得到分类和回归的结果。
SiamRPN++的改进主要源自于upchannel的方法中,升维卷积参数量极大, 分类分支参数就有接近6M的参数,回归分支12M。其次升维造成了两支参数量的极度不平衡,模版分支是搜索支参数量的2k~4k倍,也造成整体难以优化,训练困难。改为Depthwise版本以后,参数量能够急剧下降;同时整体训练也更为稳定,整体性能也得到了加强。
实验结果

DaSiamRPN
之前Siam的问题
1.常见的siam类跟踪方法只能区分目标和无语义信息的背景,当有语义的物体是背景时,也就是有干扰物(distractor)时,表现不是很好。
2.大部分siam类跟踪器在跟踪阶段不能更新模型,训练好的模型对不同特定目标都是一样的。这样带来了高速度,也相应牺牲了精度。
3.在长时跟踪的应用上,siam类跟踪器不能很好的应对全遮挡、目标出画面等挑战。
解决方法
之所以出现上述的问题,作者的结论是训练过程中的样本不均衡造成的。一个是正样本种类不够多,导致模型的泛化性能不够强:解决方案是加入detection的图片数据,pair可以由静态图片通过数据增益生成;加入detection数据生成的正样本之后,模型的泛化性能得到了比较大的提升。第二个是样本不均衡来自于难例负样本,在之前的Siamese网络训练中, 负样本过于简单,很多事是没有语义信息的:解决办法是用不同类之间的样本(还有同类的不同instance)构建难例负样本,从而增强分类器的判别能力。不同种类的正负样本的构建可以参见下图。以上两个改进大大改善了相应分数的质量,在丢失目标的时候,相应分数随之变得很低,说明跟踪器的判别能力得到了改善。
