opencv实战---使用TesseractOCR进行文字识别
什么是tesseractOCR?
- TesseractOCR 是一款由HP实验室开发由 Google 维护的开源 OCR(Optical Character Recognition , 光学字符识别)引擎。
- 简单点说,就是用来做字符识别的,可以识别超过100种语言。也可以用来训练其他的语言。
- 听起来不错,但识别的准确率让人恼火。于是,有人训练出了自己的识别库。
这篇就讲解一下软件安装、使用自带的识别库识别常规的英文字符、英文单词、数字。
目录
tesseract下载与安装:
1、软件下载(后面会放我自己下载好的网盘链接,可以自行下载):
2、软件安装:
3、环境变量的设置:
识别时所需要的库:
英文字符的识别:
1、先导入咱们安装好的tesseract软件以及所需要识别的图片。
2、识别。
3、在图片上面框选出字符,并且将字符的识别结果显示在图片上。
完整代码:
英文单词的识别:
完整代码:
数字的识别:
完整代码:
软件:pycharm

tesseract下载与安装:
1、软件下载(后面会放我自己下载好的网盘链接,可以自行下载):
这里是tesseract的下载官网,任意版本的都可以,但不要下载带有dev标识的版本。
没有速度快的梯子的话,速度会很慢。但我没有梯子,好像就下了十来分钟左右。
2、软件安装:
这里就必须强调有无梯子的事了。
双击下载好的exe文件,一路next,直到这个界面注意一下:
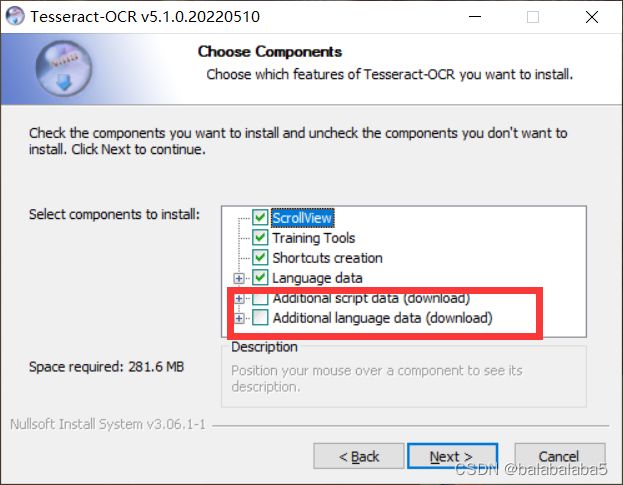
- 如果你对自己的梯子速度很有自信的话,请勾选上红色框出来的两项。然后不停的点击next,直到安装成功。
- 如果没有,那咱就不要勾选 。后面也是一路无障碍的安装成功。接下来,咱进入这个github链接,下载所有的文件。下载好压缩包之后,解压,将里面所有的文件都放进刚刚安装tesseract的文件夹里的tessdata里面。
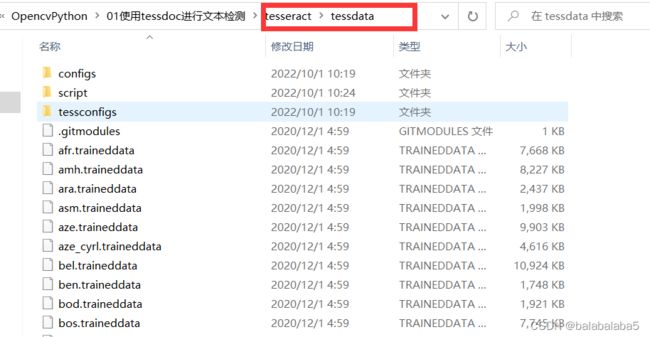
3、环境变量的设置:
按顺序点击:此电脑---属性---高级系统设置---环境变量。
选中path那一行,点击“编辑”。
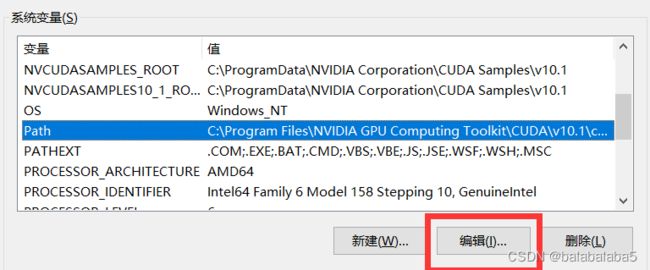
在弹窗内点击“新建”,将安装tesseract软件的文件夹的绝对路径放进去。我这里是D:\OpencvPython\01使用tessdoc进行文本检测\tesseract。
确定之后,在此界面点击“新建”:
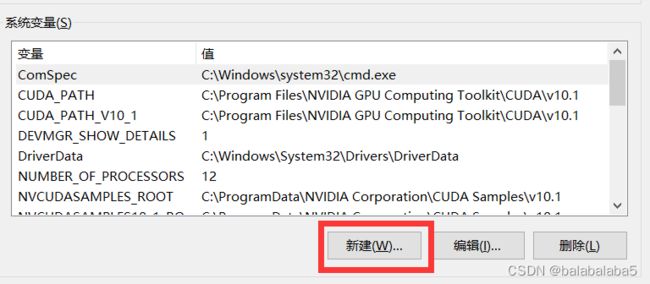
输入变量名和变量值:(变量值是tesseract软件下面的tessdata文件的绝对路径)
变量名:TESSDATA_PREFIX
变量值:D:\OpencvPython\01使用tessdoc进行文本检测\tesseract\tessdata
剩下的就是不停的点击确定。环境变量设置结束。
在cmd里输入:tesseract --version
出现版本号了就是下载成功了。

这是我自己下载好的软件和压缩包的网盘链接,自行下载:
链接:https://pan.baidu.com/s/1-dP6-QauGDjBsvo8v8_Gyw
提取码:cimx
识别时所需要的库:
import cv2
import pytesseract英文字符的识别:
1、先导入咱们安装好的tesseract软件以及所需要识别的图片。
这里注意一下:tesseract只能识别RGB格式的图片,而opencv导进来的图片是BGR格式的。
pytesseract.pytesseract.tesseract_cmd = 'D:\\OpencvPython\\01使用tessdoc进行文本检测\\tesseract\\tesseract.exe'
img = cv2.imread('eng.png')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)图片:

2、识别。
text = pytesseract.image_to_string(img)
print(text)结果:(挺成功的)

3、在图片上面框选出字符,并且将字符的识别结果显示在图片上。
hImg, wImg, _ = img.shape
boxes = pytesseract.image_to_boxes(img)
for b in boxes.splitlines():
b = b.split(' ')
x1, y1, x2, y2 = int(b[1]), int(b[2]), int(b[3]), int(b[4])
cv2.rectangle(img, (x1,hImg-y1), (x2, hImg-y2), (0, 0, 255), 2)
cv2.putText(img, b[0], (x1, hImg-y1+25), cv2.FONT_HERSHEY_SIMPLEX, 1, (50, 50, 255), 2)结果:

来拆解一下这组代码的含义:
hImg, wImg, _ = img.shape
boxes = pytesseract.image_to_boxes(img)
img,shape输出的是原始图片img的高度、宽度、纬度
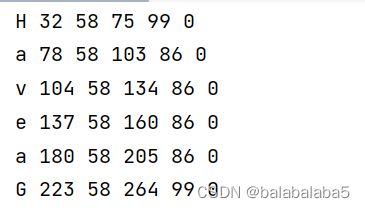
boxes如下图所示,里面包含着每个字符的识别结果和该字符所在的位置信息。
比如:H 32 58 75 99 。含义依次是左下角横坐标,左下角纵坐标,右上角横坐标,右上角纵坐标。这个位置信息需要额外注意一下:pytesseract.image_to_boxes的坐标系原点在左下角,而opencv的坐标系原点在左上角。
要想从这些字符串里面取出来数据,引入一个for循环。
for b in boxes.splitlines(): # 这里将boxes的元素一行一行地取出
for b in boxes.splitlines():
b = b.split(' ') # 这里将b里面的元素,出现空格就分开
b里面的数据:

再次强调:pytesseract.image_to_boxes的坐标系原点在左下角,而opencv的坐标系原点在左上角。
将坐标转换成opencv里面需要的坐标。
先小结一下相关变量的含义:
hImg : 图片的总高度; wImg : 图片的总宽度
x1: 字符的左下角横坐标; y1:字符的左下角纵坐标
x2: 字符的左上角横坐标; y2:字符的左上角纵坐标
大概画一张图:

根据线段长度之类的转换,很成功地得到了坐标。
使用cv2.rectangle函数,画出外框。
- 对于cv2.rectangle函数有个新发现:之前一直以为参数必须是左上角和右下角的坐标确定方框的位置,但现在通过实验验证,是通过确定对角线的方式画出矩形的。无论是主对角线还是副对角线,都可以画出来。
使用cv2.putText放置文本内容。
最后的结果为:

完整代码:
import cv2
import pytesseract
pytesseract.pytesseract.tesseract_cmd = 'D:\\OpencvPython\\01使用tessdoc进行文本检测\\tesseract\\tesseract.exe'
img = cv2.imread('eng.png')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
text = pytesseract.image_to_string(img)
print(text)
hImg, wImg, _ = img.shape
boxes = pytesseract.image_to_boxes(img)
for b in boxes.splitlines():
b = b.split(' ')
x1, y1, x2, y2 = int(b[1]), int(b[2]), int(b[3]), int(b[4])
cv2.rectangle(img, (x1,hImg-y1), (x2, hImg-y2), (0, 0, 255), 2)
cv2.putText(img, b[0], (x1, hImg-y1+25), cv2.FONT_HERSHEY_SIMPLEX, 1, (50, 50, 255), 2)
cv2.imshow('Result', img)
cv2.waitKey(0)英文单词的识别:
如何做到把字符连起来形成单词的样子?
和英文字符的识别差别只在第三步。这里就放上第三步的代码。
hImg, wImg, _ = img.shape
boxes = pytesseract.image_to_data(img)
print(boxes)
for x,b in enumerate(boxes.splitlines()):
if x!=0:
b = b.split()
print(b)
if len(b)==12:
x1, y1, x2, y2 = int(b[6]), int(b[7]), int(b[8]), int(b[9])
cv2.rectangle(img, (x1,y1), (x1+x2, y1+y2), (0, 0, 255), 3)
cv2.putText(img, b[11], (x1,y1), cv2.FONT_HERSHEY_SIMPLEX, 1, (50, 50, 255), 2)这里调用的函数是 image_to_data,前面调用的函数是image_to_boxes。
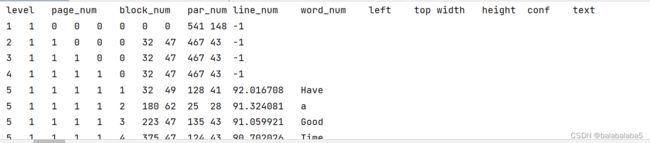
boxes = pytesseract.image_to_data(img)
这个函数输出的boxes就多样化了,但咱只需要第7、8、9、10、12列的数据。
for循环的语句里
boxes.splitlines()还是将boxes按行分开
而enumerate(a)函数会将a里的每一个元素单独拆分出来,并且加上索引,以元组的形式返回。
所以,for x,b in enumerate(boxes.splitlines()),x放的是索引号。后面再加上一个x!=0的条件句,就是为了去掉boxes里第一行的“level、page_num、block_num...”。
再看看boxes里面的十二列数据,会发现有的行只有11个数据,-1代表没有识别出东西来。而能够识别出来的都会有12个数据,咱需要的也就是有12个数据的那些行,因此又有了len(b)==12的条件句。
剩下的三行代码和识别字符一样的含义。
最后识别英文单词的结果:

完整代码:
import cv2
import pytesseract
pytesseract.pytesseract.tesseract_cmd = 'D:\\OpencvPython\\01使用tessdoc进行文本检测\\tesseract\\tesseract.exe'
img = cv2.imread('eng.png')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
text = pytesseract.image_to_string(img)
print(text)
hImg, wImg, _ = img.shape
boxes = pytesseract.image_to_data(img)
print(boxes)
for x,b in enumerate(boxes.splitlines()):
if x!=0:
b = b.split()
print(b)
if len(b)==12:
x1, y1, x2, y2 = int(b[6]), int(b[7]), int(b[8]), int(b[9])
cv2.rectangle(img, (x1,y1), (x1+x2, y1+y2), (0, 0, 255), 3)
cv2.putText(img, b[11], (x1,y1), cv2.FONT_HERSHEY_SIMPLEX, 1, (50, 50, 255), 2)
cv2.imshow('Result', img)
cv2.waitKey(0)数字的识别:
其实在英文字符的识别里面,就可以完成对数字的识别了。
识别的结果:
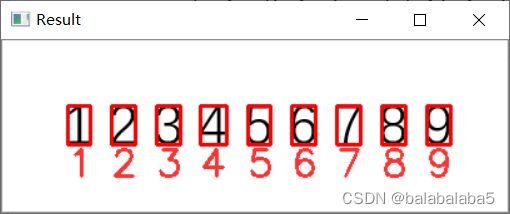
使用英文字符识别的代码,既有英文又有数字的识别结果:

但你要是只想识别出数字:
那就在boxes那里加个限制条件:让oem为3,psm为6。
cong = r'--oem 3 --psm 6 outputbase digits'
boxes = pytesseract.image_to_boxes(img, config=cong)
-oem 参数控制OCR的引擎模式,控制由超正方体使用的算法类型。
oem的数值代表的模式:

-psm 参数控制tesseract使用的自动页面分割模式。
psm的数值代表的模式:

识别结果:

很明显,加上了限制条件,它确实只能够识别准确数字,其他类型的东西效果很不理想,甚至不能识别(理论上是不能识别的)。
完整代码:
import cv2
import pytesseract
pytesseract.pytesseract.tesseract_cmd = 'D:\\OpencvPython\\01使用tessdoc进行文本检测\\tesseract\\tesseract.exe'
img = cv2.imread('eng.png')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
text = pytesseract.image_to_string(img)
print(text)
hImg, wImg, _ = img.shape
cong = r'--oem 3 --psm 6 outputbase digits'
boxes = pytesseract.image_to_boxes(img, config=cong)
for b in boxes.splitlines():
b = b.split(' ')
x1, y1, x2, y2 = int(b[1]), int(b[2]), int(b[3]), int(b[4])
cv2.rectangle(img, (x1,hImg-y1), (x2, hImg-y2), (0, 0, 255), 2)
cv2.putText(img, b[0], (x1, hImg-y1+25), cv2.FONT_HERSHEY_SIMPLEX, 1, (50, 50, 255), 2)
cv2.imshow('Result', img)
cv2.waitKey(0)