【论文阅读】【弱监督-3D目标检测】Weakly Supervised 3D Object Detection from Point Clouds
前言
ACM MM 2020录用的一篇文章。不使用任何真实的3D框来进行训练。通过采用归一化的点云密度来生成目标候选框。不过性能一般,算是第一个吃螃蟹的人
MIT和微软合作的论文,模型简称为VS3D
论文地址:https://arxiv.org/pdf/2007.13970.pdf
Code地址:https://github.com/Zengyi-Qin/Weakly-Supervised-3D-Object-Detection
解决的问题及对应贡献
一个无监督的三维对象建议模块(UPM),它使用所提出的标准化点云密度和几何先验来选择和对齐锚点
-
一种将知识从二维图像转移到三维领域的有效方法,这使得在未标记的点云上训练三维物体探测器成为可能。【感觉这个可以用起来】
-
从点云中进行三维目标检测的弱监督学习的开创性框架,通过全面的实验进行了检验,并在不同的实验中证明了优越的性能衰减值设置。
核心思想:
不需要Groundtruth,利用点云密度来生成3D bbox的弱监督目标检测方法
文章解读
1.摘要:
场景理解中的一项关键任务是三维对象检测,它的目的是检测和定位属于特定类的对象的三维边界框。现有的3D对象检测器在训练过程中严重依赖于带注释的三维边界框,而获得这些注释可能很昂贵,而且只有在有限的场景下才能访问。弱监督学习是一种很有前途的减少注释需求的方法,但现有的弱监督对象检测器主要用于二维检测,而不是三维检测。在这项工作中,我们提出了VS3D,一个用于从点云中进行弱监督的三维物体检测的框架,而不使用任何地面真相三维边界框进行训练。首先,我们引入了一个无监督的三维提案模块,它通过利用标准化的点云密度来生成对象提案。其次,我们提出了一种跨模态知识蒸馏策略,其中卷积神经网络通过查询教师网络p来学习预测三维对象建议的最终结果在图像数据集上进行了重新训练。在具有挑战性的KITTI数据集上进行的全面实验表明,VS3D在不同的评估环境下的优越性能
2.Introduction:
通过选择具有高标准化点云密度的预设三维锚点,生成三维对象建议。然而,对象建议的类别无法判断,因为我们不能基于归一化的点云密度来区分对象的类。在对物体表面捕获的点云的部分观测下,物体的旋转也是模糊的。因此,整个网格设计应该能够将提案划分为不同的对象类别,并回归它们的旋转,这揭示了第二个挑战。
为了解决这第二个挑战,提出了一种跨模态转移学习方法:从已有数据集上得到预训练模型。将UPM生成的三维对象建议投影到成对图像上,由教师网络分类,然后由学生网络模拟教师在训练过程中的行为。利用教师网络为媒介,将知识从RGB域转移到目标点云域,节省了未标记数据集上三维对象检测的注释成本并促进了在新场景中的三维对象探测器的快速部署。我们注意到,教师网络并不总是能够监督其学生,因为两个不同的数据集之间的差距,特别是当教师网络自己的预测置信度不高时。
在此基础上,提出了一种自动加强自信监督和削弱不确定监督的整改方法。因此,学生从可靠的监督信号中学到的更多,而从那些不可靠的监督信号中学得更少。
3.网络结构:
整体结构如图所示。
 图 1
图 1
第一个关键组件是无监督的三维对象建议模块(UPM),它基于归一化的点云密度选择三维锚点,生成潜在的3D框
第二个组件是一个跨模态转移学习模块,通过利用在图像数据集上预先训练的教师模型,它将信息,包括对象分类和旋转回归,从图像数据集转移到基于点云的三维物体检测器中,对建议进行分类和改进,以产生最终的预测 (能不能从Kitti到waymo?)
其中激光雷达扫描仪并不需要提供输入点云,而输入点云也可以从单目图像或一对立体图像中获得。假设每一帧的点云在训练集中都有一个成对的图像,但在只需要点云的测试时并不需要这一点
3.1 无监督的三维对象建议模块
预设三维框,然后选择置信度高的作为目标候选框。因为没有groundtruth来监督训练,所以利用点云几何性质和先验信息来寻找目标。高密度的点云代表其是目标的可能性高。不过越远,点就越稀疏。
因此作者引入了一个距离不变的点密度测量,对点云密度进行归一化。
点云密度归一化:
将三维点云投影到前视图上,以获得按像素排列的XYZ地图。并且可以得到一个2D投影框
 图 2
图 2
在边界框内裁剪XYZ映射的斑块,并通过插值将其调整为Hc×Hc维度大小,这样就获得了3D点。像上图(a)所示,每个点都表示成了pi,j
对应有一个bool矩阵,True代表点在Anchor内,False代表不在(我的理解False代表的就是插值出来的点)
对应的会有个点云密度Dc Nin/H2
如果一个目标被一个锚框包含,那么对应的点云密度会有一个阈值,
如何确定有多少点在3D锚框呢?首先把3D点p从相机坐标系转为锚框坐标系,
![]()
代表从原点到锚中心的转换,
![]()
这样计算就能确定点是否在锚框内
锚的选择和对准:
通过阈值筛选留下来的框,首先会稍微扩大一下。如上图(c)。最开始的框与目标不是很好地对齐。作者观察到,如果锚框和目标很好地对齐,这种情况下,许多点应该与框的矩形表面相近。因此,作者就对框沿x,y,z,进行小范围地平移
3.2 图像到点云的转换
前面的UPM输出的框不是最终结果。观察到,某些选定锚将包含不属于目标类别的对象(像路边的树也可能被框进去了)
基于图像的教师网络:
该教师是一个使用VGG16架构的图像识别和视点回归网络,并在ImageNet、PASCALVOC上进行了预训练(包含图像类别标签和视点标签)。教师网络以不超过一个对象的图像作为输入,将图像分类为背景或一类对象,同时恢复对象视点作为其旋转点开启。视点回归被认为是一个多分类问题,其中我们从一个单位圆分割出16个角度,预测某一角度的概率。
教师作为现成的模型训练三维对象的检测模型,如图1上面蓝色分支。
基于点云的学生网络:
学生代表基于点云的三维对象探测器的第二阶段,由VGG16(主干层)、RoIAlign层和完全连接层组成,如在中所示图1中的绿色分支。输入点云被转换为前视图XYZ图,然后输入类似工作的backbone。利用图像与点云相结合,我们可以从教师网络中提取识别信息到学生身上。更具体地说,我们将UPM生成的每个对象提案都投影到RGB图像和前视图XYZ映射上。然后,我们剪切出图像上的投影,并使用教师网络识别目标建议。同时,我们使用RoIAlign[18]从学生主干中提取每个提案的编码特征,并将这些特征提供给完全连接的层,以预测对象类别和旋转角度在培训过程中,每个目标提案分别有来自老师和学生的两个预测。学生学习用修正的交叉熵来模仿教师的信心损失,如下文所述。当将该能力从现有教师中提取为拥有不同数据集的学生时,不可避免地会出现问题。
首先,老师网络自己生成的结果可能置信度不高
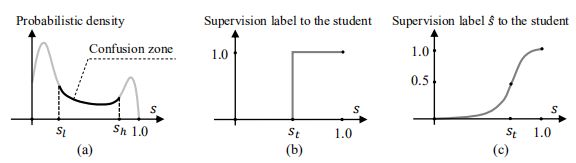 图 3
图 3
老师网络生成的结果置信度不高的情况不适合传递给学生模型。另外如果仅仅传递0或1,无法有效区分不同积极性的标签。作者采用了图3(c)的方式来代表正标签
![]()
4.实验
三个基本的问题:
1)所提出的检测框架的定量性能及其与现有方法的比较如何?
2)关于不同类型的输入信号公司的性能是如何变化诱人的单目图像,立体图像和激光雷达扫描?
3)无监督的三维对象建议模块对整个框架有多重要?
输入类型:
一个输入点云的帧可以从三个来源获得,包括一个单目图像、一对立体图像和激光雷达扫描。
对于单目图像,将其输入给DORN来预测像素级的深度,然后将其深度转换为三维点云;
对于立体图像,将其输入给PSMNet来产生深度,转换为三维点云;
激光雷达获取的点云直接输入网络。
实施细节:
数据增强:1)在X和Y轴随机平移[-1,1]m,Z轴上随机平移[-0.2m,0.2m];
弱监督目标检测
比较了三种最先进的弱监督检测方法[38,39,42]。PCL[38]通过聚类对象建议,迭代地学习改进的实例分类器。OICR[39]将在线实例分类细化添加到一个基本的多实例学习网络中。MELM[42]建立了一个最小熵的潜在模型来测量对象定位的随机性,并指导潜在对象的发现。由于这些方法不能预测三维边界框,因此比较将主要是在二维领域。我们的VS3D的三个版本也被评估,对应于单目、立体声和激光雷达的输入。
表1使用每帧前10个预测显示不同IoU阈值下的召回。结果表明,作者的方法比MELM[42]高出了20%到50%。表2显示了二维和三维目标检测的平均精度。

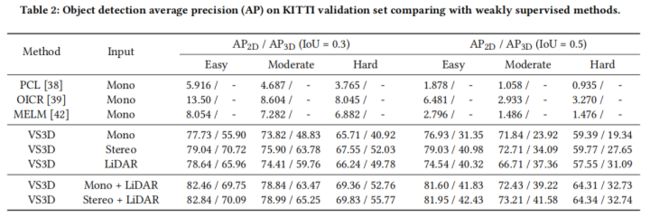
作者的目标建议方法可以改进baseline,如表4所示。
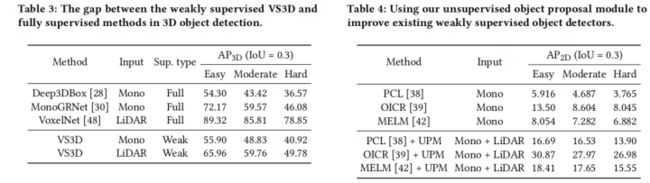
将表3的弱监督VS3D与表3中的完全监督方法进行了比较,通过比较VS3D与不同的输入数据类型,可以观察到一个有趣的现象。一般来说,如果评估度量是三维的,而IoU的要求很高,那么基于激光雷达的版本将是一个优势。但对于二维指标,如二维召回率和AP2D,以及低物联网阈值的3维指标,单目版本和立体声版本可以有更好的性能。这一现象可以解释如下。对于具有高IoU阈值的三维度量,三维定位的要求可能要高得多,而且激光雷达很擅长提供这样的几何精度。由单目和双目生成的点云,达不到激光雷达采集点云的精度。相反,对于具有低单位阈值的二维度量或三维度量,三维定位的要求要低得多。由图像生成的点云的分辨率比激光雷达点云要高,更适合理解语义场景,使基于图像的方法能够具有更好的性能。大多数RGB相机都是无源传感器,受到黑暗的影响,而激光雷达则是具有内置光源的有源传感器,因此受外部照明的影响较小。因此,最佳的方法应该能够适当地结合照相机和激光雷达,这可以在不同的场景下相互补充
消融研究
所提出的无监督三维对象建议模块(UPM)选择和对齐具有高目标置信度的预定义锚,删除了98%以上的冗余锚。作者提出的UPM是基于归一化点云密度(NPCD),它是物体存在的距离不变指标。为了验证我们的方法的有效性,我们用另外两种策略替换了NPCD,并比较了边界框的召回率。第一个是包容性策略(INC),其中保留预定义的锚而不被过滤。第二种是基于点云密度(PCD),其中PCD不需要提议的标准化步骤来测量。很明显,NPCD比INC和PCD展示了更好的性能。NPCD和PCD之间的差距主要是由于标准化步骤。PCD可以反映对对象方案的目标信心,但受到距离的严重影响,大多数遥远的锚点都被过滤了,因为它们的点云密度很低,即使它们包含对象。

总结:
本文提出了点云三维目标检测的开创性工作,工作包含了无监督的三维对象建议模块(UPM)和跨节点转移学习模块。UPM以原始点云作为输入,并输出3D对象建议。在没有地面真相监督的情况下,UPM利用标准化的点云密度来识别潜在包含对象的三维锚点。由UPM预测的对象建议由学生网络进行分类和细化,以产生最终的检测结果。基于点云的学生网络由基于图像的教师网络进行训练,通过将知识从现有的图像数据集转移到点云区域