[语义分割]基于VGG网络搭建FCN-8s并在VOC2012数据集上训练
文章目录
-
- 1.数据集选取
-
- 1.1数据集简介
- 1.2 数据预处理
-
- 1.2.1踩坑记录1
- 1.2.2 读取图片路径
- 1.2.3 自定义图像增强与预处理模块
- 1.3自定义数据集类
-
- 1.3.1数据标签可视化
- 2.搭建FCN-8s网络
-
- 2.1基础FCN网络架构
- 2.2一些细节
- 2.3网络搭建
-
- 2.3.1导入预训练神经网络
- 2.3.2 FCN-8s pytorch 实现
- 3.在VOC2012上训练
-
- 3.1定义超参数
- 3.2导入数据集
- 3.3 实现评价指标 PA,MIOU
- 3.4 实现train方法
-
- 3.4.1 踩坑记录2
- 3.4.2pytorch使用GPU训练
- 4.测试
-
- 4.1测试结果可视化:
1.数据集选取
1.1数据集简介
本次训练选取PASCAL-VOC2012数据集,更详细的信息请访问
官网:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html
Kaggle:https://www.kaggle.com/huanghanchina/pascal-voc-2012
VOC2012用于语义分割的数据集分为20类对象+1类背景,原始的数据集包含了除分割外的分类+检测+共一万多张图片,但本次任务我们只需要语义分割的那一部分数据。
1.2 数据预处理
本次任务的标签位于VOC2012\SegmentationClass路径下,和图像识别任务不同的是,图像识别中一张图像就对应一个Label,而语义分割任务需要对一张图像实现像素级别的分类,因此分割任务是一个像素对应一个Lable,并且一张图像上还不止一个label,这样一来我们对于标签的标注方式就不能简单的像图像识别一样,可以仅通过文件的命名以体现不同图像所属的类别,而需要对图像中的每一个类别进行手动的标注,类别内的每一个像素均属于该类别。
好在VOC2012数据集为我们提供了标注好的标签,我们需要做的只是对标签进行一些细节上的处理。
1.2.1踩坑记录1
我们可以先试着读取一张标签,看看标签的存储方式:
![[语义分割]基于VGG网络搭建FCN-8s并在VOC2012数据集上训练_第1张图片](http://img.e-com-net.com/image/info8/a5d7ef13417c47dd8e7c7abbfa1e5ebf.jpg)
'''for test'''
from PIL import Image
import matplotlib.pyplot as plt
img = Image.open('VOC2012/SegmentationClass/2007_000032.png')
print(np.array(img).shape)
plt.imshow(img)
plt.show()
[Out]: (281, 500)
可以看到输出尺寸是一个二维矩阵,说明标签的存储方式为”单通道“,但是通过imshow我们又可以发现,图片其实具有四个通道(右下角),好像又是RGBA的形式:
![[语义分割]基于VGG网络搭建FCN-8s并在VOC2012数据集上训练_第2张图片](http://img.e-com-net.com/image/info8/5c989a834ad84531a1e70addb6879060.jpg)
这着实让我一时半会摸不着头脑,于是我就按照RGBA->RGB的形式对图像进行处理:
#将图像转换为RGB形式(4通道->3通道)
img = Image.open('VOC2012/SegmentationClass/2007_000032.png').convert('RGB')
并自定义了将RGB图像转为灰度标签的函数(最后根本用不着):
#标注数据中每种颜色对应的类别:
colormap = [
[0,0,0],
[128,0,0],
[0,128,0],
[128,128,0],
[0,0,128],
[128,0,128],
[0,128,128],
[128,128,128],
[64,0,0],
[192,0,0],
[64,128,0],
[192,128,0],
[64,0,128],
[192,0,128],
[64,128,128],
[192,128,128],
[0,64,0],
[128,64,0],
[0,192,0],
[128,192,0],
[0,64,128],
]
#将颜色转换为类别:
def image2label(image, colormap):
image = np.array(image, dtype = 'int64') # image.shape = (320, 480, 3)
cm2lbl = np.zeros(3000)
for label, color in enumerate(colormap):
# 创建哈希表存储原图颜色序列
cm2lbl[(color[0]+color[1]*8+color[2]*2)] = label
#print(color[0]*256+color[1]*256+color[2])
#print(cm2lbl)
#print(np.sum(cm2lbl != np.zeros(3000)))
# rgb三通道合并(简单粗暴的三通道相加)
ix = (image[:,:,0]+image[:,:,1]*8+image[:,:,2]*2) # ix.shape = (320, 480)
#从哈希表中,将颜色序列转换为对应的标签
image2 = cm2lbl[ix]
return image2 # image2.shape = (320, 480)
但是最后又想了想感觉哪里不对,二维的尺寸就应该是标签的形式,于是乎就想着输出标签的一行看看:
img = Image.open('VOC2012/SegmentationClass/2007_000032.png')
print(np.array(img)[100])
发现矩阵里的元素的确是标签形式(背景0,边缘255, 其余1~20)。。。
最后通过查阅资料才发现,VOC2012语义分割的标签存储模式是P-Mode,而不是我们熟知的RGB(可以print看看):
print(img)
[Out] :
而plt在imshow这类格式的图像又会自动处理成RGBA格式。因此imshow的时候就有三个通道。
谜题终于揭晓,关于P Mode格式不是重点,我们只需要把它看成单通道标签处理就行,因此上述的image2label函数根本用不着(先留着说不定哪天又会用到)。
1.2.2 读取图片路径
由于VOC2012数据集并不都用于语义分割,因此一万多张图片里有一些数据是我们需要舍弃的。在数据集里的\ImageSets\Segmentation里的txt文档描述了哪些数据可以用作语义分割:
![[语义分割]基于VGG网络搭建FCN-8s并在VOC2012数据集上训练_第3张图片](http://img.e-com-net.com/image/info8/a596ca1075a3469eae0606180a58b06b.jpg)
在这里我们定义一个函数用于筛选出这些数据作为我们的训练集与验证集:
# 读取图片路径 路径
def read_image_path(root):
# 读取文档
image = np.loadtxt(root, dtype = str)
n = len(image) # 数据集尺寸
data, label = [None]*n, [None]*n
for i, fname in enumerate(image):
data[i] = 'VOC2012/JPEGImages/%s.jpg' %(fname) # 数据集
label[i] = 'VOC2012/SegmentationClass/%s.png'%(fname) # 标签
return data, label
1.2.3 自定义图像增强与预处理模块
再次强调一遍,由于语义分割是像素级别的分类,因此标签和原图必须完美的匹配,这时候如果使用transforms模块自带的数据增强方法,因为是随机方法,因此处理后就会导致图像和标签在像素上不匹配的情况,因此我们自定义图像增强方法:
# 增强 # 由于是全卷积网络,图像的大小固不固定无所谓
def rand_crop(data, label, high, width): # high, width为裁剪后图像的固定宽高(320x480)
im_width, im_high = data.size
#生成随机点位置
left = np.random.randint(0, im_width - width)
top = np.random.randint(0, im_high - high)
right = left+width
bottom = top+high
#图像随机裁剪(图像和标签一一对应)
data = data.crop((left,top, right, bottom))
label = label.crop((left,top, right, bottom))
#图像随机翻转(图像和标签一一对应)
angle = np.random.randint(-15,15)
data = data.rotate(angle) # 逆时针旋转
label = label.rotate(angle) # 逆时针旋转
return data, label
# 预处理
def img_transforms(data, label, high, width):
data, label = rand_crop(data, label, high, width)
data_tfs = transforms.Compose([
transforms.ToTensor(),
#标准化,据说这6个参数是在ImageNet上百万张数据里提炼出来的,效果最好
transforms.Normalize(mean = [0.485, 0.456, 0.406],std = [0.229, 0.224, 0.225]),
])
data = data_tfs(data)
label = torch.from_numpy(np.array(label))
return data, label
1.3自定义数据集类
如何在PyTorch中自定义数据集类在我的上一篇博客已经做了详细的介绍,方法大同小异:传送地址
在这里我直接贴上代码,值得注意的是,为了防止rand_crop函数越界报错,本次我们添加了一个过滤方法用来过滤掉图像尺寸小于指定size的图像:
#自定义数据集:
class MyDataset(Data.Dataset):
def __init__(self, data_root, high, width):
self.data_root = data_root
self.high = high
self.width = width
self.imtransform = img_transforms
data_list, label_list = read_image_path(root = data_root)
self.data_list = self.filter(data_list)
self.label_list = self.filter(label_list)
def __getitem__(self, idx):
img = self.data_list[idx]
label = self.label_list[idx]
img = Image.open(img)
label = Image.open(label)#.convert('RGB')
img, label = self.imtransform(img, label, self.high, self.width)
return img, label
def __len__(self):
return len(self.data_list)
# 过滤掉图像尺寸小于high,width 的图像
def filter(self, images):
return [im for im in images if (Image.open(im).size[1] > self.high and Image.open(im).size[0] > self.width)]
1.3.1数据标签可视化
最后我们可以试着输出一个batch_size的图片看看效果如何。
BATCHSIZE = 8
voc_train = MyDataset("VOC2012/ImageSets/Segmentation/train.txt",high, width)
train_loader = Data.DataLoader(voc_train, batch_size = BATCHSIZE, shuffle = True)
for step, (b_x, b_y) in enumerate(train_loader):
if(step > 0):
break
#可视化一个batch的图像,检查数据预处理是否正确:
b_x_numpy = b_x.data.numpy()
b_x_numpy = b_x_numpy.transpose(0,2,3,1)
b_y_numpy = b_y.data.numpy()
plt.figure(figsize = (16,3))
for ii in range(BATCHSIZE):
plt.subplot(2,BATCHSIZE,ii+1)
plt.imshow(inv_normalize_image(b_x_numpy[ii]))#(320, 480, 3)
plt.axis('off')
plt.subplot(2,BATCHSIZE,ii+9)
plt.imshow(label2image(b_y_numpy[ii]))
plt.axis('off')
plt.subplots_adjust(wspace = 0.1, hspace = 0.1)
plt.show()
![[语义分割]基于VGG网络搭建FCN-8s并在VOC2012数据集上训练_第4张图片](http://img.e-com-net.com/image/info8/d0e8fd48c0024b8d87eb0076a023eeb1.jpg)
可视化首先要将类别转化为RGB信息:
#将标签转化为图像
def label2image(prelabel):
h,w = prelabel.shape
prelabel = prelabel.reshape(h*w, -1)
image = np.zeros((h*w,3),dtype = 'int32')
for ii in range(21):#共21个类别
index = np.where(prelabel == ii) # 找到n维数组中特定数值的下标
image[index,:] = cmode(ii)
return image.reshape(h,w,3)
其中,cmode是我们自定义的将标签与rgb一一映射的方式,使用随机数种子:
#画框取色函数
def cmode(param):
if param==0:
return(0,0,0)
cmap = []
random.seed(int(param))
rand = random.random()
color = list(cm.rainbow(rand))
for i in range(3):
cmap.append(int(color[i]*255))
return tuple(cmap)
图像去标准化(送给网络学习的图像是经过标准化处理的,标准化能让网络更好的学习特征的分布,我们在可视化时去除):
#去标准化
def inv_normalize_image(data):
rgb_mean = np.array([0.485, 0.456, 0.406])
rgb_std = np.array([0.229, 0.224, 0.225])
data = data.astype('float32') * rgb_std + rgb_mean
return data.clip(0,1)
这里如果我们不去标准化,可以看看标准化后的图像长啥样:(上:原图,下:标准化)
![[语义分割]基于VGG网络搭建FCN-8s并在VOC2012数据集上训练_第5张图片](http://img.e-com-net.com/image/info8/4eb318747da547899fdee7c9e9a74549.jpg)
2.搭建FCN-8s网络
FCN是当下最经典,也最简单的一个语义分割网络,全称叫做全卷积神经网络,顾名思义就是所有的网络层均采用卷积层(或反卷积)实现,直接去除了原来在分类任务中常用的全连接层
论文中提到使用全卷积有两个好处:
- 基于卷积操作的平移不变性,网络的参数能够有效减少
- 卷积操作输出的是图像的热图,更适用于密集型像素级分类
2.1基础FCN网络架构
FCN核心网络架构包括三个部分:
- 一开始的特征提取层,这一部分我们可以直接采用基础的预训练的特征提取网络(AlexNet,VGG, GoogLeNet, ResNet等),这一部分可以不需要网络的训练,我们的FCN网络搭建基于特征网络微调的基础之上
- 特征提取层之后紧接着反卷积层,反卷积层相当于一个参数可学习的上采样方法,将特征图恢复到原图尺寸大小
- 中间的跳级结构,在论文中作者发现仅仅使用上述两种结构会使得网络预测结果过于粗糙,缺乏细节,一些精细的边缘无法得到有效的分割,这是因为在特征网络提取特征之后,经过了5层的最大池化,输出的特征图尺寸为原图的1/32,不可避免的会丢失掉一些细节,因此作者采取了一种方法,即将倒数二三层pool后的特征也一并提取出来,通过反卷积上采样之后在融合进下一层的特征图中进行预测,这样一来便保留了原始图像当中的一些特征:
![[语义分割]基于VGG网络搭建FCN-8s并在VOC2012数据集上训练_第6张图片](http://img.e-com-net.com/image/info8/5061042d3a1048999cc303de00a496f6.jpg)
再贴一张更直观的图:
![[语义分割]基于VGG网络搭建FCN-8s并在VOC2012数据集上训练_第7张图片](http://img.e-com-net.com/image/info8/795e64c2ccbf497b9026b61c7a7f3a6a.jpg)
其中作者还对比了使用不同程度的跳层结构对预测精度的影响,如果仅仅使用特征网络最后一层pool的输出(没有跳层)就是FCN-32s,加入了倒数第二,第一层,就是FCN-16s,FCN-8s:
![[语义分割]基于VGG网络搭建FCN-8s并在VOC2012数据集上训练_第8张图片](http://img.e-com-net.com/image/info8/3e70b1f900a24195a6b7abe7fd4a5f77.jpg)
2.2一些细节
在FCN论文提供的FCN-8s源码当中,我们发现作者选用的深度学习框架为caffe,因此其关于网络搭建的详细配置参数都保存在.prototxt文件中,
train和val保存训练网络和测试网络的框架,solver保存一些超参数的定义

我们查看solver.prototxt,可以了解作者对于超参数的详细定义:比如作者对于学习率设置得十分小
train_net: "train.prototxt"
test_net: "val.prototxt"
test_iter: 736
# make test net, but don't invoke it from the solver itself
test_interval: 999999999
display: 20
average_loss: 20
lr_policy: "fixed"
# lr for unnormalized softmax
base_lr: 1e-14
# high momentum
momentum: 0.99
# no gradient accumulation
iter_size: 1
max_iter: 100000
weight_decay: 0.0005
snapshot: 4000
snapshot_prefix: "snapshot/train"
test_initialization: false
查看train.prototxt(caffe十分讲究网络的层次性,因此卷积操作,激活函数,损失函数等通通定义为一个Layer):作者采用的损失函数为SoftmaxWithLoss,我在pytorch中直接定义为交叉熵损失。
# 损失函数:
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "score"
bottom: "label"
top: "loss"
loss_param {
ignore_label: 255 # 这里不需要边缘的标签
normalize: false
}
}
然后看看作者如何处理跳级结构(融合特征时采取简单的线性相加):
... ...
layer {
name: "fuse_pool4"
type: "Eltwise"
bottom: "upscore2"
bottom: "score_pool4c"
top: "fuse_pool4"
eltwise_param {
operation: SUM
}
}
... ...
layer {
name: "fuse_pool3"
type: "Eltwise"
bottom: "upscore_pool4"
bottom: "score_pool3c"
top: "fuse_pool3"
eltwise_param {
operation: SUM
}
}
... ...
在net.py中我们可以直观看到各层卷积核的参数(才发现python也是可以导入caffe模块的)。
了解了以上细节后,我们就可以在pytorch上进行我们的网络搭建了
2.3网络搭建
2.3.1导入预训练神经网络
论文中表示选择VGG16的效果相当于VGG19,本次任务采用VGG19作为特征提取层
使用summary方法可以查看网络的架构以及参数等情况:
# 使用预训练的VGG19网络:
model_vgg19 = vgg19(pretrained = True)
summary(model_vgg19, input_size = (3,320, 480))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 320, 480] 1,792
ReLU-2 [-1, 64, 320, 480] 0
Conv2d-3 [-1, 64, 320, 480] 36,928
ReLU-4 [-1, 64, 320, 480] 0
MaxPool2d-5 [-1, 64, 160, 240] 0
Conv2d-6 [-1, 128, 160, 240] 73,856
ReLU-7 [-1, 128, 160, 240] 0
Conv2d-8 [-1, 128, 160, 240] 147,584
ReLU-9 [-1, 128, 160, 240] 0
MaxPool2d-10 [-1, 128, 80, 120] 0
Conv2d-11 [-1, 256, 80, 120] 295,168
ReLU-12 [-1, 256, 80, 120] 0
Conv2d-13 [-1, 256, 80, 120] 590,080
ReLU-14 [-1, 256, 80, 120] 0
Conv2d-15 [-1, 256, 80, 120] 590,080
ReLU-16 [-1, 256, 80, 120] 0
Conv2d-17 [-1, 256, 80, 120] 590,080
ReLU-18 [-1, 256, 80, 120] 0
MaxPool2d-19 [-1, 256, 40, 60] 0
Conv2d-20 [-1, 512, 40, 60] 1,180,160
ReLU-21 [-1, 512, 40, 60] 0
Conv2d-22 [-1, 512, 40, 60] 2,359,808
ReLU-23 [-1, 512, 40, 60] 0
Conv2d-24 [-1, 512, 40, 60] 2,359,808
ReLU-25 [-1, 512, 40, 60] 0
Conv2d-26 [-1, 512, 40, 60] 2,359,808
ReLU-27 [-1, 512, 40, 60] 0
MaxPool2d-28 [-1, 512, 20, 30] 0
Conv2d-29 [-1, 512, 20, 30] 2,359,808
ReLU-30 [-1, 512, 20, 30] 0
Conv2d-31 [-1, 512, 20, 30] 2,359,808
ReLU-32 [-1, 512, 20, 30] 0
Conv2d-33 [-1, 512, 20, 30] 2,359,808
ReLU-34 [-1, 512, 20, 30] 0
Conv2d-35 [-1, 512, 20, 30] 2,359,808
ReLU-36 [-1, 512, 20, 30] 0
MaxPool2d-37 [-1, 512, 10, 15] 0
... ... ... ... ... ...
================================================================
Total params: 143,667,240
Trainable params: 143,667,240
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 1.76
Forward/backward pass size (MB): 729.88
Params size (MB): 548.05
Estimated Total Size (MB): 1279.68
----------------------------------------------------------------
2.3.2 FCN-8s pytorch 实现
在搭建过程中有一个难点,就是如何提取网络中间层特征并融合到上采样中去,在我们之前搭建的网络中,参数都是一层一层的往下传,没有遇到跳级结构,
通过查阅资料发现torch模型有一个_modules.items()方法,我们可以通过遍历item()来实现层层监视,即如果这一层是我们需要保存的特征,我们就可以使用字典结构将这一层的特征提取并保存起来,在反卷积操作的时候再提取出参与融合即可。
值得注意的是,全卷积网络在最后一层分类层使用的是1x1卷积,我们可以简单的将1x1卷积类比全连接的分类输出,通过调整卷积核输出的深度等于类别数,就可以控制最后输出的图像深度=类别数,即每一个像素都做了分类,最后再接上一层softmax就可以输出每一个像素预测的类别了
接下来直接贴代码
# 自定义FCN-8s:
class FCN8s(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.num_classes = num_classes
self.base_model = model_vgg19.features #去除全连接层
self.ConvTrans1 = nn.Sequential(
nn.ConvTranspose2d(512, 512, kernel_size = 3, stride = 2, padding = 1, dilation = 1, output_padding = 1),
nn.ReLU(inplace = True),
nn.BatchNorm2d(512),
)
self.ConvTrans2 = nn.Sequential(
nn.ConvTranspose2d(512, 256, kernel_size = 3, stride = 2, padding = 1, dilation = 1, output_padding = 1),
nn.ReLU(inplace = True),
nn.BatchNorm2d(256),
)
self.ConvTrans3 = nn.Sequential(
nn.ConvTranspose2d(256, 128, kernel_size = 3, stride = 2, padding = 1, dilation = 1, output_padding = 1),
nn.ReLU(inplace = True),
nn.BatchNorm2d(128),
nn.ConvTranspose2d(128, 64, kernel_size = 3, stride = 2, padding = 1, dilation = 1, output_padding = 1),
nn.ReLU(inplace = True),
nn.BatchNorm2d(64),
nn.ConvTranspose2d(64, 32, kernel_size = 3, stride = 2, padding = 1, dilation = 1, output_padding = 1),
nn.ReLU(inplace = True),
nn.BatchNorm2d(32),
)
self.classifier = nn.Conv2d(32, num_classes, kernel_size = 1) #1x1卷积, 在像素级别进行分类
#将对应的池化层存入字典,方便到时候提取该层的特征进行求和:
self.layers = {'18':'maxpool_3','27':'maxpool_4','36':'maxpool_5',}
def forward(self, x):
output = {} # 用来保存中间层的特征
# 首先利用预训练的VGG19提取特征:
for name, layer in self.base_model._modules.items():
x = layer(x)
#如果当前层的特征需要被保存:
if name in self.layers:
output[self.layers[name]] = x
x5 = output['maxpool_5'] # 原图的H/32, W/32
x4 = output['maxpool_4'] # 原图的H/16, W/16
x3 = output['maxpool_3'] # 原图的H/ 8, W/ 8
#对特征进行相关转置卷积操作,逐渐恢复到原图大小:
score = self.ConvTrans1(x5) # 提取maxpool_5的特征,转置卷积进行上采样,激活函数输出
score = self.ConvTrans2(score + x4) # 上采样后的特征再与maxpool_4的特征相加,并进行归一化操作
score = self.ConvTrans3(score + x3) # score
score = self.classifier(score)
return score
3.在VOC2012上训练
3.1定义超参数
#随机裁剪尺寸的范围
high, width = 320, 480
EPOCH = 4
BATCHSIZE = 8
LR = 5e-4
3.2导入数据集
voc_train = MyDataset("VOC2012/ImageSets/Segmentation/train.txt",high, width)
voc_val = MyDataset("VOC2012/ImageSets/Segmentation/val.txt", high, width)
train_loader = Data.DataLoader(voc_train, batch_size = BATCHSIZE, shuffle = True)
val_loader = Data.DataLoader(voc_val, batch_size = BATCHSIZE, shuffle = True)
print('训练集大小:{}'.format(voc_train.__len__()))
print('验证集大小:{}'.format(voc_val.__len__()))
[Out] :
训练集大小:1110
验证集大小:1066
3.3 实现评价指标 PA,MIOU
其中(以目标检测的思路叙述,把样本换成像素理解)
nii:真正例, ti:i类别下的样本总数,nji:假正例, ncl:总类别数
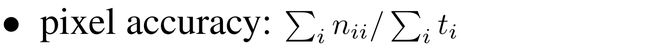

PA 即像素精度,计算公式是(预测正确的像素数/总像素数)
IOU 是目标检测中常用的一个评价指标,通过计算目标框与预测框的重叠程度判断一个候选框的好坏,具体实现是计算两者的交并比(Intersection over Union)
在语义分割中计算方式类同,只不过把目标框与预测框换成了分割区域。如果是MIOU(MIU),就对每个类别计算IOU,再取平均。
现实语义分割任务中MIOU用的比较多
![[语义分割]基于VGG网络搭建FCN-8s并在VOC2012数据集上训练_第9张图片](http://img.e-com-net.com/image/info8/c5dc16644fd84db9aa07e09970a68e34.jpg)
由于torch没有封装好的MIOU实现方法,在这里网上找了一个接口改了下直接调用
def Iou(target_all, pred_all,n_class):
"""
target是真实标签,shape为(h,w),像素值为0,1,2...
pred是预测结果,shape为(h,w),像素值为0,1,2...
n_class:为预测类别数量
"""
pred_all = pred_all.to('cpu')
target_all = target_all.to('cpu')
iou = []
for i in range(target_all.shape[0]):
pred = pred_all[i]
target = target_all[i]
h,w = target.shape
# 转为one-hot,shape变为(h,w,n_class)
target_one_hot = np.eye(n_class)[target]
pred_one_hot = np.eye(n_class)[pred]
target_one_hot[target_one_hot!=0]=1
pred_one_hot[pred_one_hot!=0] = 1
join_result = target_one_hot*pred_one_hot
join_sum = np.sum(np.where(join_result==1)) # 计算相交的像素数量
pred_sum =np.sum(np.where(pred_one_hot==1)) # 计算预测结果非0得像素数
target_sum = np.sum(np.where(target_one_hot==1)) # 计算真实标签的非0得像素数
iou.append(join_sum/(pred_sum + target_sum - join_sum + 1e-6))
return np.mean(iou)
3.4 实现train方法
#导入预训练网络:
fcn8s = FCN8s(21)
fcn8s.load_state_dict(torch.load('fcn8s.pkl'))
#summary(fcn8s, input_size = (3, high, width))
'''model:模型, criterion损失函数, optimizer:优化方法, traindataloader:训练集, valdataloader:验证集'''
def train_model(model, criterion, optimizer, traindataloader, valdataloader, num_epochs):
for epoch in range(num_epochs):
print('Eopch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
train_loss = 0.
train_num = 0
val_loss = 0.
val_num = 0
#训练
model.train()
for step, (b_x, b_y) in enumerate(traindataloader):
optimizer.zero_grad()
b_x = b_x.float() # [BATCHSIZE, 3, 320, 480]
b_y = b_y.long() # [BATCHSIZE, 320, 480]
out = model(b_x)
out = F.log_softmax(out, dim = 1)
pre_lab = torch.argmax(out, 1) # pre_lab.shape = [BATCHSIZE, 320, 480]
loss = criterion(out, b_y)
loss.backward()
optimizer.step()
train_loss += loss.item() * len(b_y)
train_num += len(b_y)
#计算PA
train_correct = torch.sum(pre_lab == b_y.data)/(BATCHSIZE * high * width)
#可视化训练效果
print('epoch:{} | step:{} | train loss"{:.5f} | PA:{:.5f}'.format(epoch, step, loss.item(), train_correct))
torch.save(model.state_dict(), 'fcn8s.pkl')
#验证:
model.eval()
for step, (b_x, b_y) in enumerate(valdataloader):
b_x = b_x.float()
b_y = b_y.long()
out = model(b_x)
out = F.log_softmax(out, dim = 1)
pre_lab = torch.argmax(out, 1)
loss = criterion(out, b_y)
val_loss +=loss.item() *len(b_y)
val_num +=len(b_y)
val_correct = torch.sum(pre_lab == b_y.data)/(BATCHSIZE * high * width)
#可视化训练效果
print('epoch:{} | step:{} | val loss:{:.5f} | PA:{:.5f} | MIOU:{:.5f}'.format(epoch, step, loss.item(), val_correct, Iou(pre_lab,b_y,21)))
return model
#定义损失函数和优化器:
'''NLLLoss:'''
# 常用于多分类任务,NLLLoss 输入 input 之前,需要对 input 进行 log_softmax 处理转换成概率
# 计算公式:loss(predict, label) = -mean(predict[label])
# predict = [[-0.1187, 0.2110, 0.7463],
# [-0.6136, -0.1186, 1.5565]]
# label = [2, 0]
# loss = [-0.7463, 0.6136]
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(fcn8s.parameters(), lr = LR, weight_decay = 1e-4)
#迭代训练:
fcn8s = train_model(fcn8s, criterion, optimizer, train_loader, val_loader, EPOCH)
torch.save(fcn8s.state_dict(), 'fcn8s.pkl')
3.4.1 踩坑记录2
然后我们可以开始,结果还没开始训练就报错了:

这是一个越界错误,冷静分析后发现原来是我们在网络最后一层的分类数 = 21,输出的图像深度是21,但是我们在计算损失的时候会读取到一个255的标签,由于计算交叉熵损失时torch会自动把预测结果转换为one-hot编码(每一个像素预测结果 = 21维向量)并且我们没有设置255的标签,于是导致了越界错误。
那这255是怎么来的呢?, 原来是标签中的边缘像素都被标记成了255, 好家伙。
因此我们就得回到数据预处理那一步去,在读取标签时就应该把所有的255标签转化为0,成为背景的一部分
通过查阅资料和不断试错,终于找到了一个相对简洁的方法,只需要在自定义的img_transforms方法中添加一行:
label = torch.from_numpy(np.array(label))
#去除边缘标签!!!!
label_without_border = torch.where(label < 255,label, torch.tensor([0],dtype=torch.uint8))
return data, label_without_border
torch.where方法能够在张量上进行操作,将张量的元素逐一执行操作:
条件label < 255, 满足执行label = label, 不满足执行label = torch.tensor([0],dtype=torch.uint8)
这样就可以完美去除标签中的边缘了
开始训练终于没有报错,接下来我们转移到Kaggle上使用GPU训练快一些
3.4.2pytorch使用GPU训练
# CPU or GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
[Out] : cuda
使用GPU时我们需要将网络以及数据集全部转移到GPU上:只需要在变量后加一句
... ...
fcn8s = fcn.to(device)
... ...
for step, (b_x, b_y) in enumerate(traindataloader):
optimizer.zero_grad()
b_x = b_x.float().to(device)
b_y = b_y.long().to(device)
... ...
不过值得注意的是,在涉及参与numpy的运算时,我们得把变量转回CPU,不然会报错,直接
xxx.to('cpu')
训练结果:(可以看出最终网络有些过拟合)
... ...
Eopch 1/1
----------
epoch:1 | step:0 | train loss"1.00322 | PA:0.80239
epoch:1 | step:1 | train loss"1.17243 | PA:0.70767
epoch:1 | step:2 | train loss"0.90827 | PA:0.82446
... ...
epoch:1 | step:66 | train loss"1.00709 | PA:0.81964
epoch:1 | step:67 | train loss"0.94611 | PA:0.78792
epoch:1 | step:68 | train loss"1.06481 | PA:0.81823
... ...
epoch:1 | step:0 | val loss:1.18824 | PA:0.72749 | MIOU:0.59025
epoch:1 | step:1 | val loss:1.53247 | PA:0.69235 | MIOU:0.56677
epoch:1 | step:2 | val loss:1.54038 | PA:0.74940 | MIOU:0.60578
... ...
epoch:1 | step:64 | val loss:1.53096 | PA:0.80526 | MIOU:0.68130
epoch:1 | step:65 | val loss:1.56283 | PA:0.69551 | MIOU:0.53615
epoch:1 | step:66 | val loss:0.71005 | PA:0.53265 | MIOU:0.72727
4.测试
BATCHSIZE = 8
fcn8s = FCN8s(21).cpu()
fcn8s.load_state_dict(torch.load('fcn8s.pkl'))
for step ,(b_x, b_y) in enumerate(val_loader):
if step > 0:
break
fcn8s.eval()
b_x = b_x.float()
b_y = b_y.long()
out = fcn8s(b_x) # out:(BATCHSIZE, LabelNum, 320, 480)
out = F.log_softmax(out, dim = 1)
pre_lab = torch.argmax(out, 1)
#可视化一个batch图像:
b_x_numpy = b_x.data.numpy()
b_x_numpy = b_x_numpy.transpose(0,2,3,1)
b_y_numpy = b_y.data.numpy()
pre_lab_numpy = pre_lab.data.numpy()
plt.figure(figsize = (16, 5))
for ii in range(BATCHSIZE):
plt.subplot(3,BATCHSIZE,ii+1)
plt.imshow(inv_normalize_image(b_x_numpy[ii]))
plt.axis('off')
plt.subplot(3,BATCHSIZE,ii+9)
plt.imshow(label2image(b_y_numpy[ii]))
plt.axis('off')
plt.subplot(3,BATCHSIZE,ii+17)
plt.imshow(label2image(pre_lab_numpy[ii]))
plt.axis('off')
print(np.sum(pre_lab_numpy[ii] == b_y_numpy[ii])/(high * width))
plt.subplots_adjust(wspace = 0.01, hspace = 0.01)
plt.show()
4.1测试结果可视化:
![[语义分割]基于VGG网络搭建FCN-8s并在VOC2012数据集上训练_第10张图片](http://img.e-com-net.com/image/info8/7c58324b6dc24e0b8f3d5ded5a186cd0.jpg)
![[语义分割]基于VGG网络搭建FCN-8s并在VOC2012数据集上训练_第11张图片](http://img.e-com-net.com/image/info8/5a373a27c89c48bf8591f3272a041719.jpg)
可以看到网络可以大体分割出物体的轮廓,但在分割精度以及分类的效果上并不是很好,和论文展示的效果还有一定差距。个人觉得这和超参数的调整以及较少数据集有关,还有就是训练的批次不够多。
如您对该文章有任何建议,欢迎在评论区交流