卷积神经网络入门(学习笔记)
文章目录
- 一、神经网络是什么?
- 二、神经网络分类
- 三、卷积神经网络(Convolutional Neural Networks, CNN)
- CNN结构
- 1. 输入层
- 2. 隐含层
-
- (1)卷积层(convolutional layer)
-
-
-
- 感受野(Receptive Field):
- 卷积核(convolutional kernel)
- 卷积层参数
-
- 1.卷积核大小
- 2.卷积步长
- 3.填充padding
- 激励函数(activation function)
-
-
- (2)池化层(pooling layer)
- (3)全连接层(fully-connected layer)
- 3.输出层
- 四、卷积的分类
-
- FLOPS
- FLOPs
- 1. 标准卷积
- 2. 深度可分离卷积(Depthwise Separable Convolution)
-
-
-
- 1.逐通道卷积 Depthwise(DW)
- 2.逐点卷积 Pointwise(PW)
-
-
- 3. 分组卷积(Group Convolution)
- 4. 膨胀卷积(Dilated convolution)
- 五、注意力机制的模块(SE模块)
一、神经网络是什么?
- 神经网络是一种计算模型,由大量的节点(或神经元)直接相互关联而构成;
- 每个节点(除输入节点外)代表一种特定的输出函数(或者认为是运算),称为激励函数;
- 每两个节点的连接都代表该信号在传输中所占的比重(即认为该节点的“记忆值”被传递下去的比重),称为权重;
- 网络的输出由于激励函数和权重的不同而不同,是对于某种函数的逼近或是对映射关系的近似描述;
- 说明:在部分网络中,存在偏置项,即对于权重求和结果的修正。
二、神经网络分类
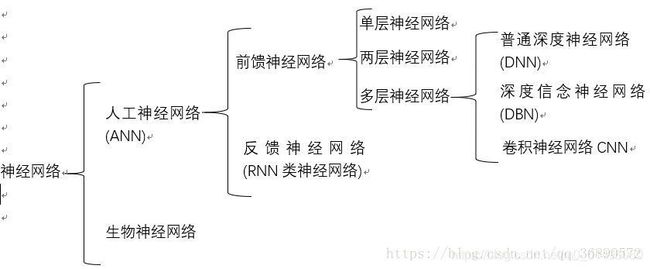
一、二点原文链接:https://blog.csdn.net/qq_36890572/article/details/82716696
卷积神经网络与全连接神经网络的区别:1.总有至少一个的卷积层,用以提取特征。2、卷积层级之间的神经元是局部连接和权值共享,这样的设计大大减少了(w,b)的数量,加快了训练。
三、卷积神经网络(Convolutional Neural Networks, CNN)
是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一。

CNN结构
1. 输入层
卷积神经网络的输入层可以处理多维数据
由于使用梯度下降算法(Gradient Descent)进行学习,卷积神经网络的输入特征需要进行标准化处理。具体地,在将学习数据输入卷积神经网络前,需在通道或时间/频率维对输入数据进行归一化,若输入数据为像素,也可将分布于 的原始像素值归一化至[0,1] 区间 。输入特征的标准化有利于提升卷积神经网络的学习效率和表现 。
!!在输入层,如果是灰度图片,那就只有一个feature map;如果是彩色图片,一般就是3个feature map(红绿蓝)!!
My questions:
1.什么是梯度下降算法?为什么要使用这个算法进行学习?
答:(一) 梯度下降法(gradient
descent)是一个最优化算法,常用于机器学习和人工智能当中用来递归性地逼近最小偏差模型。梯度下降法的计算过程就是沿梯度下降的方向求解极小值(也可以沿梯度上升方向求解极大值)。
关于随机梯度下降(SGD):https://www.zhihu.com/question/264189719
(2)为什么要使用这个算法进行学习?详解见:https://blog.csdn.net/weixin_39874350/article/details/111159990
(3)该算法缺点:靠近极小值时收敛速度减慢;直线搜索时可能会产生一些问题;可能会“之字形”地下降:例如处理香蕉函数时。
(4)两大痛点:local minima、过拟合(还没卷具体原因)2.为什么需要进行标准化处理?相关答案:https://www.zhihu.com/question/357980914
感觉看了还是看不懂QAQ~~
3.为什么要归一化到[0,1] 区间 ,而不是其他的?
4.为什么输入特征的标准化有利于提升卷积神经网络的学习效率和表现 ?
2. 隐含层
(1)卷积层(convolutional layer)
基本概念
输入(input)、卷积核/过滤器(kernel/filter)、权重(weights)、步长(stride)、感受野(receptive field)、特征图(feature map)、填充(padding)、深度(channel)、输出(output)
1. 卷积为何能够提取特征的理解:https://www.jianshu.com/p/e80bad4a4062?from=singlemessage 2.卷积层提取的特征具有平移不变性:https://www.pianshen.com/article/67541986270/
特征图(feature map)
有时将卷积层或者池化层的输入输出数据称为特征图(feature map),输入数据称为输入特征图(input feature map),输出数据称为输出特征图(output feature map)。因为一个卷积核提取一个特征,故在卷积层中卷积核的数量是等于输出特征图的数量。卷积核个数 = output feature map的个数
感受野(Receptive Field):
感受野的含义与计算详细:https://zhuanlan.zhihu.com/p/296621824及https://zhuanlan.zhihu.com/p/113487374
某个神经元能看到的输入图像的区域
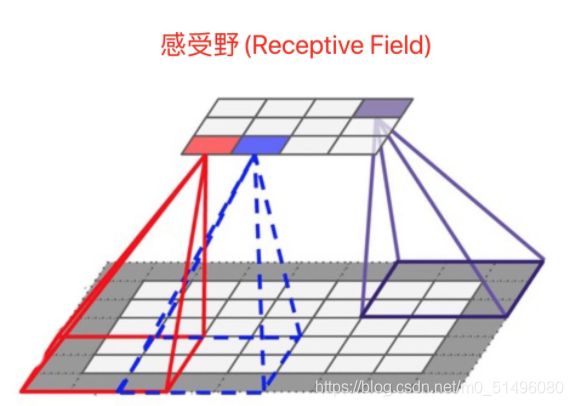
定义:
在卷积神经网络中,感受野(Receptive Field)是指特征图上的某个点能看到的输入图像的区域,即特征图上的点是由输入图像中感受野大小区域的计算得到的。
神经元感受野的值越大表示其能接触到的原始图像范围就越大,也意味着它可能蕴含更为全局,语义层次更高的特征;相反,值越小则表示其所包含的特征越趋向局部和细节。因此感受野的值可以用来大致判断每一层的抽象层次.
卷积核(convolutional kernel)
(1)每个卷积核具有长宽深三个维度;卷积核的深度与当前图像的深度(feather map的张数)相同,例如,在原始图像层 (输入层),如果图像是灰度图像,其feather map数量为1,则卷积核的深度也就是1;如果图像是彩色图像,其feather map数量为3,则卷积核的深度也就是3.
(2)在某个卷积层中,可以有多个卷积核:下一层需要多少个feather map,本层就需要多少个卷积核。
(3)不同的卷积核大小,不同的填充大小以及不同的步长都会影响输出结果的大小。
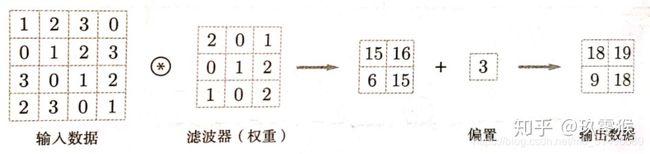
对于其计算:
- 单通道的情况下
设:输入大小 = (n1, n2),卷积核大小 = (f1, f2),填充为P,步长为S,输出图像大小 = (a2, b2),则有
a2 = (n1 + 2P - f1) / S + 1;
b2 = (n2 + 2P - f2) / S + 1; - 在多通道的情况下,只需保证卷积核的通道数与输入数据的通道数保持一致即可,其余均同上。

为什么卷积核都是奇数
答:(1)假设卷积核大小为k*k,根据公式可得到padding=(k-1)/2,k只有在取奇数的时候,padding才能是整数,否则padding不好进行图片填充。
(2)更容易找到锚点,在CNN中,一般会以卷积核的某个基准点进行窗口滑动,通常这个基准点是卷积核的中心点,所以如果k是偶数,就找不到中心点了。
1×1卷积核有什么用?
- 降维与升维,减少参数
- 增加非线性特性
- 跨通道信息交互
为什么常见的卷积核大小是1×1或者3×3?
- 卷积核越大,参数量与计算量也越大
- 多个小的卷积核可以代替大的卷积核,如:两个3 x 3的卷积核可以代替一个5 x 5的卷积核;三个3 x 3的卷积核可以代替一个7 x 7的卷积核
- 相同的参数量下,小的卷积核意味着可以增加更多的卷积层,增强非线性能力
卷积层参数
卷积层参数包括卷积核大小、步长和填充:
1.卷积核大小
可以指定为小于输入图像尺寸的任意值,卷积核越大,可提取的输入特征越复杂;
2.卷积步长
定义了卷积核相邻两次扫过特征图时位置的距离,卷积步长为1时,卷积核会逐个扫过特征图的元素,步长为n时会在下一次扫描跳过n-1个像素,步幅越大,扫描次数越少,得到的特征就越“粗糙”。如何设置:try by yourself
3.填充padding
- 填充 P = (f1 - 1) / 2(卷积核的大小 = (f1, f2) )
- 令f1,即卷积核的边长,为奇数,就能保证输出的特征图大小与原图像大小相等
- 假设P为填充在原始图像外围的Padding大小,则经过卷积操作后的特征图大小 = (n + 2P − f + 1)∗(n + 2P − f + 1) (其中输入大小 = (n, n),卷积核大小 = (f, f) )
- 在卷积中Padding的值通常有两种写法:
- Padding = valid 代表只进行有效的卷积,对边界数据不处理,输出的shape可能会变小。
- Padding = same 代表保留边界处的卷积结果,通常会使输出shape与输入shape相同。
卷积层中的 padding有什么用
答:(1)避免图像在每次识别边缘或其他特征时都缩小
(2)避免丢掉图像边缘位置的许多信息
(如果我某一天突然不懂了,就看:https://blog.csdn.net/weicao1990/article/details/80282341及https://www.jianshu.com/p/f995a9f86aec)
为什么一般用padding=same
答:same:水平方向首先会在左右各加一个零,如果最后不够的话,会在右边再加零补齐,以满足最后一次完整的移动。对于垂直方向也是同理。 Padding = same 代表保留边界处的卷积结果,通常会使输出shape与输入shape相同。
激励函数(activation function)
卷积神经网络通常使用线性整流函数(Rectified Linear Unit, ReLU),其它类似ReLU的变体包括有斜率的ReLU(Leaky ReLU, LReLU)、参数化的ReLU(Parametric ReLU, PReLU)、随机化的ReLU(Randomized ReLU, RReLU)、指数线性单元(Exponential Linear Unit, ELU)等;
My questions:
1.为什么要用激活函数? 如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,这种情况就是最原始的感知机(Perceptron)。
(2)池化层(pooling layer)
池化(pooling)是用来缩小数据尺寸的运算
一般有两种计算方式:
- Max pooling:取“池化视野”矩阵中的最大值
- Average pooling:取“池化视野”矩阵中的平均值
My questions:
1.so取最大值和平均值的效果的区别是什么?
池化层有三个特征:
- 没有要学习的参数,这和池化层不同.池化只是从目标区域中取最大值或者平均值,所以没有必要有学习的参数
- 通道数不发生改变,即不改变feature map的数量
- 它是利用图像局部相关性的原理,对图像进行子抽样,这样在保留有用信息的,对微小的位置变化具有鲁棒性(健壮), 输入数据发生微小偏差时,
池化仍会返回相同的结果
(3)全连接层(fully-connected layer)
每个神经元都与下一个神经元相连,即所有相邻的神经元之间都有链接。
全连接层可以整合卷积层或者池化层中具有类别区分性的局部信息.为了提升 CNN 网络性能,全连接层每个神经元的激励函数一般采用 ReLU 函数。最后一层全连接层的输出值被传递给一个输出,可以采用 softmax 逻辑回归(softmax regression)进行 分 类,该层也可 称为 softmax 层(softmax layer).
3.输出层
积神经网络中输出层的上游通常是全连接层,因此其结构和工作原理与传统前馈神经网络中的输出层相同。对于图像分类问题,输出层使用逻辑函数或归一化指数函数(softmax function)输出分类标签
四、卷积的分类
详细可见:https://blog.csdn.net/m0_43395719/article/details/107789213
FLOPS
注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
FLOPs
注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
1. 标准卷积
- 卷积层
- 参数量 = (卷积核W 1* 卷积核H1 * 输入通道数 input_channel* 输出通道数output_channel )
- 计算量(FLOPs) = (卷积核W 1* 卷积核H1 * (图片W - 卷积核W1 + 1)* (图片H - 卷积核H1 + 1)*
输入通道数 input_channel * 输出通道数output_channel)
2. 深度可分离卷积(Depthwise Separable Convolution)
深度可分离卷积主要分为两个过程,分别为逐通道卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)。
1.逐通道卷积 Depthwise(DW)
Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积,这个过程产生的feature map通道数和输入的通道数完全一样。
- 参数量 = (卷积核W 1* 卷积核H1 * 输入通道数input_channel )
- 计算量(FLOPs) = (卷积核W 1* 卷积核H1 * (图片W - 卷积核W1 + 1)* (图片H - 卷积核H1 + 1)* 输入通道数 input_channel)
- 对于输入层的每个通道独立进行卷积运算,没有有效利用不同通道在相同空间位置上的feature信息。所以需要逐点卷积 Pointwise(PW)来将所得的feature组成新的特征图(Feature Map)
2.逐点卷积 Pointwise(PW)
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。(卷积核的shape即为:1 x 1 x 输入通道数 x 输出通道数)
- 与标准卷积运算极其相似,其卷积核尺寸为11M,M为上一层的通道数
- 在卷积运算时会将上一步的Map在深度上进行加权组合,形成新的特征图(Feature Map)
- 卷积核的shape = (1 * 1 * 输入通道数input_channel * 输出通道数output_channel)
- 参数量 = ( 1 * 1 * 输入通道数input_channel * 输出通道数output_channel )
- 计算量(FLOPs) = (1 * 1 * 特征层W2 * 特征层H2 * 输入通道数input_channel * 输出通道数output_channel)
相关计算见:https://zhuanlan.zhihu.com/p/164715641?utm_source=wechat_session
3. 分组卷积(Group Convolution)
group conv常用在轻量型高效网络中,它用少量的参数量和运算量就能生成大量的feature map,大量的feature map意味着能够编码更多的信息。
- 分组卷积和普通卷积最大的不同就是卷积核在不同通道上卷积后的操作
- 在生成一个特征图(Feature Map)的前提下: 普通卷积是在与input_channel相同的数量的卷积核条件下,在各个通道上进行卷积,之后求和的操作; 而分组卷积则是一个卷积核对应一个channel进行卷积,然后在channel维度上进行合并。
- 分组卷积是在分组之后进行标准卷积,之后再将所得的结果融合形成新的特征图(Feature Map)
- 标准卷积所得到的特征图包含所有通道的feature信息:分组卷积所得到的特征图包含的只有所属的组内的通道的feature信息。
4. 膨胀卷积(Dilated convolution)
Dilated Convolution是在标准卷积的Convolution map的基础上注入空洞,以此来增加感受野(reception field)。因此,Dilated Convolution在Standard Convolution的基础上又多了一个超参数(hyper-parameter)称之为膨胀率(dilation rate),该超参数指的是kerne的间隔数量。
-
优点:
保留内部数据结构
避免了使用向下采样(down-sampling)的特性 -
潜在的问题:
The Gridding Effect(网格效应):(Main)
假设:当我们仅仅多次叠加 扩张率(dilation rate)= 2 的 3 x 3 卷积核 的话,则会出现这个问题:

此时*卷积核(kernel)*并不是连续的,也就是说并不是所有的像素(pixel)都被用来计算的,在这种情况下就会导致图像的某些信息在卷积后缺失,即会损失掉信息的连续性。尤其对于像素级密集预测(pixel-level dense prediction),这种缺点极其致命。 -
解决的方案:
Hybrid Dilated Convolution (HDC)(通向标准化设计)- 即使用多个不同空洞率的空洞卷积核混合
- HDC是针对以上问题所提出的解决方案:图森组的文章对以上问题提出了较好的解决的方法,他们设计了一个称之为 HDC 的设计结构。


变形卷积核、可分离卷积?卷积神经网络中十大拍案叫绝的操作:https://zhuanlan.zhihu.com/p/28749411
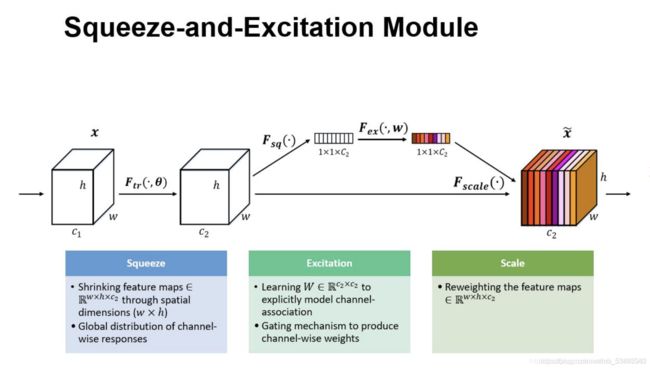
五、注意力机制的模块(SE模块)
- SE,全称为“Squeeze-and-Excitation”,即为压缩和激发
- 压缩:将特征图通过Global Average Pooling(GAP),得到特征图的全局压缩特征量(GAP的意义是对整个网络从结构上做正则化防止过拟合。)
- 激发:通过两层全连接的bottleneck结构(沙漏型结构)得到特征图中每个通道的权值,并且将加权后的特征图作为下一层网络的输入(注:Bottleneck 的核心思想是利用多个小的卷积核替代一个大的卷积核,利用 1 x 1 卷积核来替代大的卷积核的一部分工作。)
- 一个特征图经过一系列卷积池化形成的新的特征图,这个特征图的所有通道对其都是同等比重的;而对于特征图来说,不同的通道对于其重要性理应是不同的,所以我们需要添加一个权值来衡量不同通道的重要性程度,通过权值与通道数的乘积来得到真正的特征图,这个特征图对于每个通道的重要性都不同的