全面支持 PyTorch 2.0:BladeDISC 5 月~11 月新功能发布
作者:BladeDISC研发团队
BladeDISC 上一次更新主要发布了 GPU AStitch 优化,方法来源于我们发表在 ASPLOS 2022上的论文AStitch。这一次,我们发布了 0.3.0 版本。
本次更新中 BladeDISC 社区全面支持了 PyTorch 2.0 编译,推进了和 Torch-MLIR 社区的合作;增加了 CPU 量化编译和倚天新硬件支持;在编译优化方面 BladeDISC 社区增加了一系列特性,包括改进了 GPU 访存密集计算的性能,完成了 Shape Constaints IR 功能设计和支持。
本文描述 BladeDISC v0.3.0 版本对于 v0.2.0 的主要更新内容。
PyTorch 2.0 和动态编译支持
BladeDISC 近半年来高度关注 PyTorch 2.0 相关特性的新动态,积极参与社区的协作,在此期间完成了 TorchBlade 编译架构的调整,更好地 PyTorch 动态编译和训练支持。
TorchDynamo 优化
现在使用 PyTorch nightly 版本和 BladeDISC,只需要额外的两行代码改动即可完成 BladeDISC 的编译加速:
import torch_blade # one more extra line
model = ...
compiled_model = torch.compile(model, backend='disc')
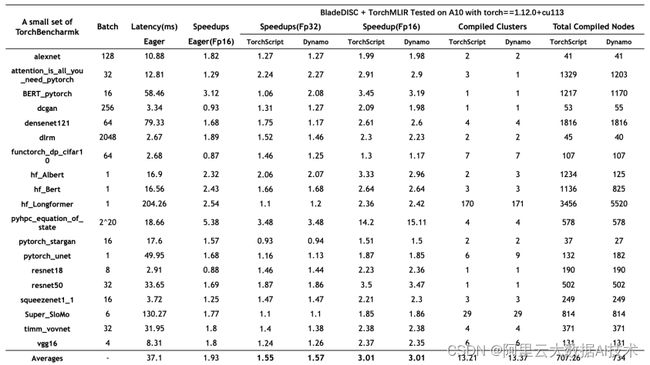
TorchBenchmark
BladeDISC 持续关注深度学习模型的通用优化,我们将 TorchBenchmark 作为优化的指南针评估和持续提升 BladeDISC 在不同模型上的鲁棒性和优化效果。
TorchMLIR(MHLO) 和动态性贡献
BladeDISC 一直是 MLIR/MHLO 动态性的主要贡献和推动者。这个版本中我们与字节 AML 团队合作往 Torch-MLIR 贡献了 Torch-to-MHLO 的模块,特别是对动态性的支持,请参考 [RFC] Adding Torch to MHLO conversion #999,特别感谢字节 AML 的同事的共同推动!
并且我们对 BladeDISC 中的 PyTorch 编译流程做了架构调整,Torch-MLIR 成为了 BladeDISC 的基础模块。下图中蓝色线框表示了 Torch-to-MHLO 工作在 BladeDISC 中相对的位置。
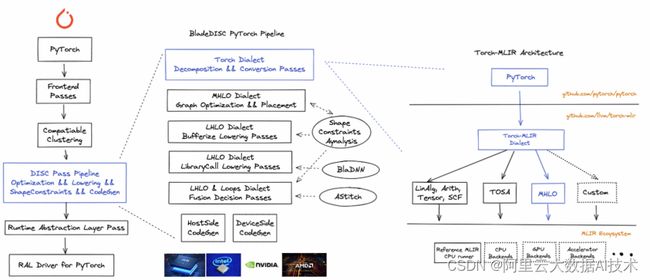
我们号召社区对此模块感兴趣的朋友们一起合作推动 Torch-MLIR(MHLO) 模块的迭代与演进,减少基础工作的碎片化。
PyTorch 训练支持
BladeDISC 正在逐步支持 PyTorch 模型的训练优化,目前已经成功支持 BERT 等模型的编译优化。BladeDISC 支持采用 PyTorch 2.0 的 TorchDynamo 和 Lazy Tensor Core 两种方式开启训练优化(当前此模块的接口没有完全确定,鉴于目前 PyTorch 社区的活跃度,我们会更优先支持 TorchDynamo 的使用方式)。目前此模块仍在持续更新和迭代,更多状态请关注我们的开发动态。
EasyCV/NLP 推理加速编译支持
- BEVFormer: 是一种纯视觉的自动驾驶感知算法,借助 BladeDISC 优化,取得了 1.42 倍的端到端性能提升。
- PAI-Diffusion Model: 在此版本中 BladeDISC 社区也对最近大热的 AIGC Diffusion 相关模型提供了通用优化支持。BladeDISC 为 PAI-Diffusion 提供了接近 3 倍的端到端的性能提升。
更多信息请查看 PAI EasyCV/NLP 相关系列文章和开源地址:
- EasyCV: https://github.com/alibaba/EasyCV
- EasyNLP: https://github.com/alibaba/EasyNLP
BladeDISC 量化 (Experimental)
在这半年中我们完成了编译+量化结合的一系列初步摸索,在包括X86、ARM多个不同硬件平台上完成了早期的方案及性能验证,下表中展示了我们一些初步的成果。
| 模型 | 输入 | 设备 | 优化前PyTorch/FP32 | 优化后Int8量化+编译 |
|---|---|---|---|---|
| bert-mini | 8*64 | g6r / Ampere Altra / 单核 | 135.9 ms | 39.6 ms |
| bert-mini | 8*64 | g8m / YiTian /单核 | 127.8 ms | 31.1 ms |
| bert-mini | 8*64 | hfg7 / Cooper Lake 8369 /单核 | 37.5 ms | 21.5 ms |
近期我们将支持更多硬件平台(例如CUDA),并提供如何量化PyTorch/TensorFlow模型的示例。此外,我们也将继续优化提升量化模型的推理性能。
BladeDISC 编译优化改进
新硬件支持:AArch64(倚天)
在这半年中我们进一步完善了对AArch64类硬件(尤其是倚天)的支持,进行了一系列针对性改进:
- 增加对BF16/int8 GEMM/Conv的支持,充分利用倚天硬件的能力;
- 对Arm Compute Library进行了一系列的定制和改进,解决其在dynamic shape及高并发场景下的各种可用性问题;
- 访存密集型算子CodeGen质量改进,包括Stitch-CPU对reshape类算子的支持从而支持更大粒度的kernel,以及op duplication策略的引入进一步减少访存量;
GPU上访存密集计算codegen性能增强
针对GPU上访存密集计算子图代码生成提供了一系列的深度优化,单个LayerNorm子图在常规推理shape下可带来最高2X的性能提升。主要的优化功能包括:
- Fusion中若干独立控制流的合并。比如一个stitch fusion中包含多个独立的且shape相同的row reduce计算,则将这几个独立row reduce计算的控制流合并为同一个,一方面减少不必要的计算,另一方面增大ILP;
- Row-reduce的schedule选择逻辑优化。针对不同的shape,选择更加合适的row reduce计算的的schedule;
- 优化element-wise fusion的向量化优化。通过指令交叉来支持element-wise fusion的数据读和计算的向量化;
- Loop相关优化。添加loop unroll及instruction interleave优化,增大ILP;添加循环不变量外移优化,减少不必要的计算;
- 消除kernel的无效argument ,减小kernel launch开销。
以上功能可以通过设置变量DISC_MEM_INTENSIVE_OPT_EXPERIMENTAL=true来打开。
Shape Constraint IR
在这半年中我们完成Shape Constraint IR的设计和开发,通过将shape constraint作为第一等公民引入到IR中,可以方便我们充分挖掘计算图中蕴含的结构化约束,并以此来辅助完成一系列动态shape语意下的优化,进一步缩小与static shape compiler在优化空间上的差异。感兴趣的读者可以在这里了解我们的设计文档,也可以阅读我们在知乎上分享的技术文章 (link1, link2)。
对二次定制开发支持的增强
我们基于MLIR社区PDL的工作重构了BladeDISC中接入一个custom library call流程,极大的简化了相关的开发工作量。在新的方式下,用户只需要提供一个PDL的pattern描述文件,以及一个符合BladeDISC runtime接口的kernel,便可以在不重新编译BladeDISC的情况下,实现pattern的替换及对应kernel的调用,明显改进了BladeDISC对二次定制开发的支持。我们在量化这个场景下检验了新的基础设施的可用性及工程效率,感兴趣的同学可以参考这里和这里的例子。后续我们还将借助PDL和transform dialect进行进一步拓展,使得不仅仅是对custom kernel,也能对特定pattern的CodeGen策略进行定制。
Runtime Abstraction Layer 改进
- 大模型权重的支持:我们重构了常量(比如模型的权重参数)编译结果的存储格式,从基于protobuf改成了自定义的格式, 从而去除了对const上限的约束,方便我们支持大模型的优化。
- 并发性能改进:针对高并发场景(比如同时服务数百路并发的推理请求)进行了一系列的优化,进一步缩小了kernel 调度以及共享资源锁同步的开销,在某语音识别200+并发的场景中进一步取得20%+的性能改进。
Ongoing Work
CUTLASS Gemm CodeGen
在GPU上接入了CUTLASS进行计算密集型算子的算子融合与代码生成,自动化地将GEMM及后续的element-wise(如GELU等激活函数子图、Tranpose算子等)进行计算融合与代码生成。目前GEMM + GELU及GEMM + Transpose的通路已经走通,且在BERT模型上取得了加速效果,鲁棒性正在提升中,可使用DISC_ENABLE_COMPUTE_INTENSIVE_FUSE=true设置来尝试使用。
MLIR Transform Dialect Based CodeGen
我们目前正在基于MLIR社区的transform dialect进行计算密集型相关pattern在dynamic shape语意下的代码生成,目前第一个目标是在AArch64平台上GEMM相关pattern达到与ACL相当的性能,以期通过白盒的方式彻底解决ACL在dynamic shape以及服务端多路请求并发的场景下的可用性问题,相关的工作的最新进展可以参见这里。
推荐类稀疏模型
我们针对在业界中广泛应用的Tensorflow推荐类模型的性能热点部分–FeatureColumn中的稀疏算子进行了初步的优化支持。目前已经完成推理场景中常见的稀疏算子的cpu codegen支持,以及初步的算子融合支持,基于此目前已经可以在部分模型上获得了一定的收益。后续我们将支持更多种类,更大粒度的算子融合以及使用CPU AVX等指令集优化稀疏部分算子的计算性能,相关进展参见这里。
以上为本次 release 的主要内容。
项目开源地址:https://github.com/alibaba/BladeDISC