MoCoV3:何恺明团队新作!解决Transformer自监督训练不稳定问题!

文 | happy
源 | 极市平台

论文链接:
https://arxiv.org/abs/2104.02057
本文是FAIR的恺明团队针对自监督学习+Transformer的一篇实证研究。针对Transformer在自监督学习框架中存在的训练不稳定问题,提出了一种简单而有效的技巧:Random Patch Projection,它不仅适用于MoCoV3框架,同样适用于其他自监督学习框架(比如SimCLR、BYOL);与此同时,从不同角度的对比分析得出:Transformer中的位置信息尚未得到充分探索,即Transformer仍有继续改善的空间。
 Abstract
Abstract
本文并没有提出一种新的方法,相反,鉴于最近计算机视觉的进展,我们研究了一个简单、渐进、但必须知道的基线:用于视觉Transformer的自监督学习。尽管标准卷积网络的训练方法已经非常成熟且鲁棒,然而ViT的训练方案仍有待于构建,特别是自监督场景下的训练极具挑战。在这里,我们从基础出发,对训练自监督ViT的几种基本组件的影响进行了分析调研。我们发现:不稳定性是影响精确下降的最主要问题,它会被表面上好的结果覆盖(容易陷入局部最优)。我们通过实验发现:这些结果确实存在部分失败;当训练变得稳定时,这些结果可以进一步提升。基于MoCoV3以及其他自监督框架,我们从不同角度对ViT进行了测试分析;我们对观察到的积极面、挑战性以及开放问题进行了讨论,期望该工作可以为未来的研究提供有用的数据支撑和经验参考。
 Introduction
Introduction
本文主要聚焦于:采用视觉领域的自监督框架进行Transformer的训练。CNN的训练方法已被进行充分的研究与论证,而ViT模型是新的,其训练方法尚未完整构建。本文从基础出发,研究了影响深度网络训练的几个基本模块:batch size,learning rate以及optimizer。我们发现:在不同场景下,不稳定性均是影响自监督ViT训练的主要问题。有意思的是,我们发现:不稳定的ViT训练可能不会导致灾难性结果(比如发散);相反,它可以导致精度的轻度退化(约下降1-3%)。除非有一个更稳定的作为对比,否则这个程度的退化可能难以被注意到。据我们所知,该现象在卷积网络训练中鲜少发生,我们认为该问题及其隐含的退化值得注意。为了证明不稳定性的可能危害,我们研究了一个可以在实践中提高稳定性的简单技巧。基于梯度变换的经验观察,我们固化ViT中的块投影层,即采用固定随机块投影。我们发现该trick可以缓解多种场景下的不稳定问题并提升模型精度。基于对比学习框架,自监督Transformer可以取得非常好的结果。不同于ImageNet监督的ViT(模型变大时精度反而变差),更大的自监ViT可以取得更高的精度。比如ViT-Large的自监督预训练可以取得超越监督预训练版本的性能。此外,本文所提自监督ViT模块可以取得与大的卷积网络相当的性能。一方面验证了ViT的潜力;另一方面意味着自监督ViT仍有进一步提升的空间。因为我们发现:移除ViT中的position embedding仅仅造成了轻微的性能下降,这意味着:自监督ViT无需位置信息即可学习很强的特征表达,同时也也暗示位置信息并未得到充分探索。
 MoCoV3
MoCoV3
我们先来看一下本文所提出的MoCoV3,它是对MoCo V1/2的一种改进,寻求在简单性、精度以及可缩放等方面提供更好的均衡。MoCoV3的伪代码实现如下:

类似MoCo、SimCLR,我们采用随机数据增强从每个图像中裁剪两个图像块,并经由两个编码器编码为,我们采用InfoNCE损失函数:

其中,表示q同源图像的输出,即正样本;表示异源图像输出,即负样本。延续SimCLR处理方式,MoCoV3采用同一批次自然共存的密钥,移除了Memory Queue(当batch足够大时,其收益递减)。基于这种简化,上面的对比损失可以简化为上述伪代码中ctr实现。我们采用了对称损失:。我们的编码器由骨干网络(如ResNet、ViT)、投影头以及额外的预测头构成;而编码则由骨干网络、投影头构成,没有预测头。通过的滑动平均更新。作为参考,我们以ResNet50作为骨干网络,其在ImageNet上的性能如下,由于额外的预测头与大的batch,MoCoV3具有更加性能。

Stability of Self-Supervised ViT Training
原则上来讲,我们可以直接在对比自监督学习框架中采用ViT骨干替换ResNet骨干网络。但实际上,主要挑战在于:训练不稳定。我们发现:不稳定问题不仅仅由精度反映。实际上,即使存在不稳定问题,它也可以“表面上很好”的进行训练并提供一个不错的结果。为揭示这种不稳定性,我们在训练过程中对kNN曲线进行了监控,研究了它如何影响不稳定性并提出了一种简单的trick进行稳定训练,进而提升不同场景下的精度。
Empirical Observations on Basic Factors

按照上述方式,我们设计了不同计算量的ViT模型并采用大batch(它有助于提升自监督学习方法的性能)进行训练。在下面的分析中,我们采用ViT-B/16作为基准。
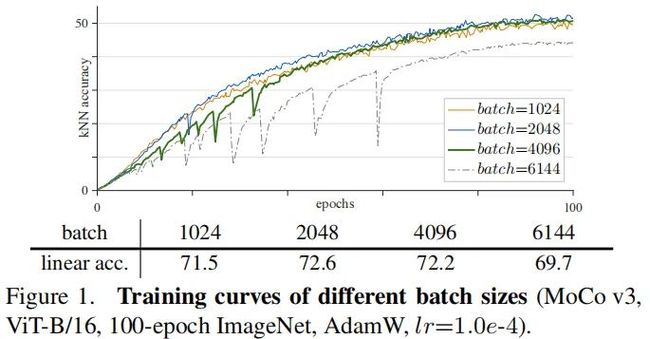
BatchSize。上图给出了不同batch时的训练曲线。可以看到:
-
1k和2k的batch具有比较平滑的曲线,精度分别为71.5%和72.6%;
4k的曲线就开始变得不再稳定,其最终精度为72.2%,要低于2k的72.6%。后面会提到:这里的性能下降是受不稳定训练导致。
6k的曲线的不稳定性进一步加剧,最终仍有一个不错的结果69.7%。我们猜测:训练被部分重启,跳出了当前局部最优并重新寻找新的优化轨迹。因此,训练无法收敛,最终的精度会依赖于重启的局部性能。
此外,我们还发现这种不稳定不会导致一个显著差的结果。实验发现:相同配置下,结果的差异较小,范围内。这就使得不稳定导致了性能退化难以被注意到。

LearningRate。事实上,学习率通常会随batch提升而缩放。在本文实验中,我们采用了线性缩放规则:。上图给出了学习率的影响曲线。当lr比较小时,训练更为稳定,但会欠拟合。比如0.5e-4训练的模型精度要比1.0e-4训练的模型精度低1.8%。当lr比较大时,训练不再稳定。如1.5e-4训练曲线具有更多的下降波谷且精度更低。

Optimizer。我们默认采用AdamW作为训练优化器;另一方面,LARS是自监督方法常用的一种优化器。我们研究了LMAB优化器,它是LARS的AdamW版,结果见上图。给定合理的学习率,LMAB可以获得比AdamW稍高的精度(72.5%)。但是当学习率比最优学习率大时,模型精度会迅速下降。有意思的是:此时的训练曲线仍然很平滑,但会缓慢下降。我们发现:当学习率合适时,LAMB可以取得与AdamW相当的精度。但是学习率的敏感性使其无法在进行学习率搜索的前提下适配不同架构设计。因此,我们仍选择AdamW作为默认优化器。
A Trick for Improving Stability
前面的所有实验均表明:不稳定是主要问题。接下来,我们将提出一种简单的trick提升不同场景下的稳定性。

在训练过程中,我们注意到梯度突变(见上图突变波峰)会导致训练曲线的“下沉”(见上图)。通过比较所有层的梯度,我们发现:梯度突变发生在(patch projection)第一层先发生,然后延迟一定迭代后最后一层再发生。基于该发现,我们猜测:不稳定性发生在浅层。受此启发,我们在训练过程中对块投影进行冻结。换句话说:我们采用固定的Random Patch Projection层进行块嵌入,而非通过学习方式。

上图对比了可学习与随机块投影的MoCoV3结果对比。可以看到:随机块投影可以稳定训练,训练曲线更为平滑、精度更高(精度提升约1.7%),进一步说明了训练不稳定是影响精度的主要问题。

我们发现:除了MoCo外,其他相关方法(比如SimCLR、BYOL)同样存在不稳定问题。随机块投影同样可以改善SimCLR与BYOL的性能(分别提升0.8%和1.3%),见上图对比。不稳定对于SwAV会导致损失发散(NaN),本文所提随机块投影可以稳定训练SwAV并将其精度由65.8%提升到66.4%。总而言之,本文所提trick对于所有自监督方案均有效。Discussion:一个有意思的发现:块投影层的训练并非必要。对于标准ViT块尺寸,其块投影矩阵时过完备的,此时随机投影足以保持原始块的信息。我们注意到:冻结第一层并不会改变架构,但它会缩小解决方案空间。这意味着:根本问题与优化相关。该trick可以缓解优化问题,但不能解决它;当lr过于大时模型仍存在不稳定问题。第一层不太可能时不稳定的主要原因,相反,该问题与所有层相关。但第一层只是更易于分开处理,因为它是骨干网络仅有的非Transformer层。
Implementation Details
在这里,我们ViT+MoCoV3的实现细节进行更详细的描述。
Optimizer:默认选择AdamW,batch为4096,通过100epoch训练搜索lr和wd,然后选择最优训练更长。学习率采用40epoch进行warmup,它同样有助于缓解不稳定性;warmup之后,学习率按照cosine衰减;
MLP Head:投影头是一个3层MLP;预测头是一个2层MLP。MLP的隐含层维度均为4096,输出层维度均为256。在MoCoV3中,参考SimCLR,MLP的所有Linear均后接BN。
Loss:参考BYOL,损失函数进行了缩放。尽管该方法可以通过调节lr和wd合并,但可以使得其对的敏感性降低,默认。
ViT Architecture:参考ViT一文,输入块为或者,经过投影后它将输出一个长度为196/256的序列,Position Embedding与该序列相加;所得序列与可学习类token拼接并经由后续Transformer模块编码;最终所得类token视作输出并送入MLP头。
Linear probing。延续常规方案,我们采用线性方式评估特征表达质量。完成自监督与训练后,移除MLP头并采用监督方式训练一个线性分类器,此时训练90epoch,且仅仅采用RandomResize、Flipping进行数据增广。
 Experiments Results
Experiments Results

上表给出了不同模型的计算量、训练时长等信息(上述结果为谷歌云平台实验结果)。ViT-B训练100epoch花费2.1小时;ViT-H训练100epoch花费9.8小时(512个TPU)。如果采用GPU的话,ViT-B需要24小时(128GPU)。TPU的扩展性要比GPU更优哇。
Self-supervised Learning Framework
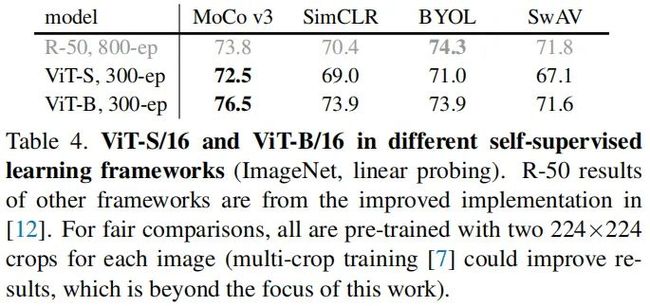
上表给出了四种不同自监督学习框架的实验对比。可以看到:(1) 相比其他自监督方法,在相同骨干网络ViT-S与ViT-B时,MoCoV3具有更加的精度。(2) MoCoV3与SimCLR在ViT-B方面的性能要优于ResNet50。
Ablations of ViT+MoCoV3
接下来,我们将从不同角度对本文所提框架进行消融实验分析。

Position Embedding(PE)。上表比较了的不同PE的性能对比,可以看到:(1) 可学习方式表现比较好,并并不如sin-cos方式;(2) 移除掉PE后,模型仍有一个不错的结果74.9%,也就是说PE仅仅贡献了1.6%。该实验揭示了当前模型的强处与局限性:一方面,模型可以仅仅通过块集合即可学习很强的表达能力,类似于bag-of-word模型;另一方面,模型可能并未充分利用位置信息。

Class Token(CLS)。上表给出了CLS的影响性对比,可以看到:(1) 移除CLS,保留LN,此时性能比较差,仅有69.7%;(2) 移除LN和CLS,结果几乎不变76.6%。这意味着:CLS对于该系统并非关键因子;同时也意味着:规范化层的选择影响较大。

BatchNorm in MLP。上表比较了BN存在鱼头的影响性。可以看到:batch=2048时,移除BN导致了2.1%的性能下降。这意味着:BN并非对比学习的必要因子,但合理的使用BN可以提升精度。

Prediction Head。上表对比了预测头有无的性能对比。预测头并非MoCo的必选项,但预测头会带来额外的精度提升(1%);而在BYOL与SimSiam中却是必选项。
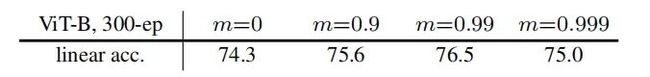
Momentum Encoder。上表对比了Momentum稀疏的影响对比。Momentum编码可以带来2.2%的性能提升。

Training length。上表对比了不同训练时长的性能对比。轻量版ViT-S可以从更长周期的训练中受益更多,比如精度提升0.9%;重量型ViT-B则受益很少。
Comparison with Prior Art

上表给出了MoCoV3框架下不同ViT模型的对比。可以看到:(1) 相比iGPUT,无需额外数据预训练,基于MoCo的ViT取得了更高的精度、更小的模型。(2) 随着模型变大,所提方案的精度会逐渐提升;而在监督学习方式中,基于ImageNet-1k/2k预训练的ViT-L的精度要低于ViT-B。事实上,本文自监督预训练的ViT-L精度(77.6%)要比监督方式(76.53%)的更高,这意味着:自监督学习作为一种广义表达学习工具不易于过拟合。

上图给出了所提方案与ResNet系列+其他自监督学习的性能对比。可以看到:
在小模型方面,本文基线ViT MoCo(即ViT, MoCoV3)的性能要比SimCLRv2+ResNet更佳;在大模型方面则与之相当。
SimCLRV2+SK-ResNet的组合具有更高的性能;
BYOL+Wider-ResNet具有更高的性能,配合R200-2x时可以得到更优异的结果;
正如前面提到的规范化技术的影响,将LN替换为BN后模型的性能提升了1%;
将ViT默认块尺寸替换为后,模型的性能进一步提升2-3%。MoCoV3+ViT-BN-L/取得了81.0%的top1精度,作为对比,SimCLRV2+SK-ResNet152-3x的最佳精度为79.8%,BYOL-ResNet200-2x的最佳精度为79.6%。
Transfer Leanring

最后,我们再看一下所提方案在下游任务迁移学习方面的性能。结果见上表,可以看到:
当模型大小从ViT-B提升到ViT-L,所提方案具有更加的迁移学习精度;当提升到ViT-H时则出现了过拟合问题。作为对比,ImageNet监督ViT在ViT-L时就出现了过拟合。
相比ImageNet监督方案,本文所提自监督ViT取得了更佳的结果。
在这些小数据上,采用大的ViT模型从头开始训练时过拟合问题非常严重。这意味着:如果数据量不足会导致难以训练ViT学习好的特征表达;而自监督预训练可以弥补这种差距,极大的避免小数据集上的过拟合问题。
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
