计算机视觉 神经网络基础理论
1.感受野
输出featuremap上的一个像素点在输入图上的映射区域的大小。
计算公式: lk+1=lk+[(fk+1−1)∗∏i=1ksi] , 为前层的步长之积∏i=1ksi为前k层的步长之积第层对应的感受野大小,第层的卷积核的大小,或为池化尺寸大小lk第k层对应的感受野大小,fk+1第k+1层的卷积核的大小,或为池化尺寸大小
当前层的步长并不影响当前层的感受野

2.特征图的大小
与为输入、出特征图尺寸,为大小,为卷积核大小,为步长nout=nin+2p−ks+1,nout与nin为输入、出特征图尺寸,p为padding大小,k为卷积核大小,s为步长
卷积向下取整,如3.2,向下取整结果为3
2.1 卷积层的参数量

参数量=(filter size * 前一层特征图的通道数 )* 当前层filter数量
2.2 卷积层的计算量

计算量 = 参数量* 输出图的尺度
3.BN(均值,方差,去均值方差,加线性变换)
训练过程中,同一个batch中的样本差别很大,如果直接训练的话,每次送入网络训练的数据分布来回波动,不利于模型收敛,很容易震荡。
BN中则针对不同神经元输入计算均值和方差,同一个batch中的输入拥有相同的均值和方差。
μB←1mΣi=1mxi
σB2←1mΣi=1m(xi−μB)2
xi~←xi−μBσ2B+ϵ
yi←γxi~+β≡BNγ,β(xi)
位置:卷积操作,BN,激活函数
BN层改变数据的分布,避免参数陷入激活函数饱和区。使其数据分布在激活函数的非饱和区。缓解梯度消失
可以增加训练速度,防止过拟合.将每一个batch的均值与方差引入网络中,由于每个batch的均值和方差都不同,相当于在训练过程中增加了随机噪声,起到一定的正则效果.
BN层可看成是增加了线性变换的白化操作(去均值方差)。(白化操作虽能从一定程度上避免了梯度饱和,但也限制了网络中数据的表达能力,浅层学到的参数信息会被白化操作屏蔽掉。所以加线性变换)
- 加快网络的训练和收敛的速度
- 控制梯度爆炸防止梯度消失
- 防止过拟合
3.1 BN训练和测试的区别
对于BN,在训练时,是对每一批的训练数据进行归一化,也即用每一批数据的均值和方差。当一个模型训练完成之后,它的所有参数都确定了,包括均值和方差,gamma和bata。
在测试时,比如进行一个样本的预测,就并没有batch的概念,因此,这个时候用的均值和方差是全量训练数据的均值和方差,也就是使用全局统计量来代替批次统计量,这个可以通过移动平均法求得。具体做法是,训练时每个批次都会得到一组(均值、方差),然后对这些数据求数学期望!每轮batch后都会计算,也称为移动平均。
训练时,我们可以对每一批的训练数据进行归一化,计算每一批数据的均值和方差。
但在测试时,比如进行一个样本的预测,就并没有batch的概念,因此,这个时候用的均值和方差是全量训练数据的均值和方差:使用了BN的网络,在训练完成之后,我们会保存全量数据的均值和方差,每个隐层神经元也有对应训练好的Scaling参数和Shift参数。
3.2BN训练时为什么不用全量训练集的均值和方差呢?
因为用全量训练集的均值和方差容易过拟合,对于BN,其实就是对每一批数据进行归一化到一个相同的分布,而每一批数据的均值和方差会有一定的差别,而不是用固定的值,这个差别实际上能够增加模型的鲁棒性,也会在一定程度上减少过拟合。
也正是因此,BN一般要求将训练集完全打乱,并用一个较大的batch值,否则,一个batch的数据无法较好得代表训练集的分布,会影响模型训练的效果。
3.++Dropout的原理以及反向传播过程,用在哪?
解决过拟合问题。dropout 是指在深度网络的训练中, 以一定的概率随机地 “临时丢弃” 一部分神经元节点. 具体来讲, dropout 作用于每份小批量训练数据, 由于其随机丢弃部分神经元的机制, 相当于每次迭代都在训练不同结构的神经网络.
当前Dropout被大量利用于全连接网络,而且一般认为设置为0.5或者0.3,而在卷积网络隐藏层中由于卷积自身的稀疏化以及稀疏化的ReLu函数的大量使用等原因,Dropout策略在卷积网络隐藏层中使用较少。3
3.+Dropout 在训练和测试时都需要嘛?
Dropout 在训练时采用,是为了减少神经元对部分上层神经元的依赖,类似将多个不同网络结构的模型集成起来,减少过拟合的风险。
而在测试时,应该用整个训练好的模型,因此不需要dropout。
4.两个3*3=一个5*5
二者感受野是一样的;同等感受野下,3*3卷积核的参数量更少;两个3*3的卷积核的非线性能力比5*5卷积核强,因为有两个激活函数,提高网络学习能力。
5.空洞(膨胀)卷积
相比于传统卷积,多了空洞数这个参数
在不增加参数量的前提下,增加感受野的同时保持特征图的尺寸不变
优点是在保持同等计算量的情况下可以扩大感受野,缺点是存在网格效应,丢失局部像素信息。
为空洞卷积核大小,空洞数,等效卷积核大小。在计算感受野时,更换为即可k′=k+(k−1)∗(d−1),k为空洞卷积核大小,d空洞数,k′等效卷积核大小。在计算感受野时,更换为k′即可
6.梯度消失,梯度爆炸

7.深度可分离卷积
深度可分离卷积主要分为两个过程,分别为逐通道卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)

卷积核channel=1;输入特征矩阵channel=卷积核个数=输出特征矩阵channel
Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积,这个过程产生的feature map通道数和输入的通道数完全一样。
Pointwise Convolution的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。(卷积核的shape即为:1 x 1 x 输入通道数 x 输出通道数)
为什么depthwise卷积后面还要pointwise卷积?控制输出通道数?
Depthwise Convolution完成后的Feature map数量与输入层的depth相同,但是这种运算对输入层的每个channel独立进行卷积运算后就结束了,没有有效的利用不同map在相同空间位置上的信息。因此需要增加另外一步操作来将这些map进行组合生成新的Feature map,即接下来的Pointwise Convolution。
8.常规卷积
卷积核channel=输入特征矩阵channel;输出特征矩阵channel=卷积核个数
9.为什么Transformer 需要进行 Multi-head Attention?
可以类比CNN中同时使用多个滤波器的作用,直观上讲,多头的注意力有助于网络捕捉到更丰富的特征/信息。
多头注意力允许模型在不同位置共同关注来自不同表征子空间的信息.
在同一 multi-head attention 层中,输入均为 KQV ,同时进行注意力的计算,彼此之前参数不共享,最终将结果拼接起来,这样可以允许模型在不同的表示子空间里学习到相关的信息
希望每个注意力头,只关注最终输出序列中一个子空间,互相独立。其核心思想在于,抽取到更加丰富的特征信息。
10. 1*1卷积的作用?
1)实现跨通道的交互和信息整合;2)实现卷积核通道数的降维和升维;3)实现与全连接层的等价效果;4)实现多个特征图的线性组合;5)不影响卷积层的感受野,增强决策函数的非线性特征表示能力
11.Pooling的作用: 池化层完全没有可变参数
与为输入、出特征图尺寸,为卷积核大小,为步长nout=nin−ks+1,nout与nin为输入、出特征图尺寸,k为卷积核大小,s为步长
池化向上取整,如3.6,向上取整结果为4
1)提高感受野 2)降低计算成本 3)多尺度融合
池化的作用体现在降采样:保留显著特征、降低特征维度,提升网络不变性。
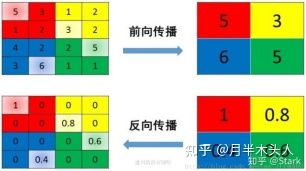
12.Pooling反向传播的过程 (需要保证传递的loss(或者梯度)总和不变)
mean pooling:mean pooling的前向传播就是把一个patch中的值求取平均来做pooling,那么反向传播的过程也就是把某个元素的梯度等分为n份分配给前一层,这样就保证池化前后的梯度(残差)之和保持不变.

max pooling:max pooling的前向传播是把patch中最大的值传递给后一层,而其他像素的值直接被舍弃掉。那么反向传播也就是把梯度直接传给前一层某一个像素,而其他像素不接受梯度,也就是为0。
13.Batch的大小如何选择,过大的batch和过小的batch分别有什么影响?
Batch选择时尽量采用2的幂次,如8、16、32等
在合理范围内,增大Batch_size的好处:
提高了内存利用率以及大矩阵乘法的并行化效率。
减少了跑完一次epoch(全数据集)所需要的迭代次数,加快了对于相同数据量的处理速度。
盲目增大Batch_size的坏处:
提高了内存利用率,但是内存容量可能不足。
跑完一次epoch(全数据集)所需的迭代次数减少,要想达到相同的精度,其所花费的时间大大增加,从而对参数的修正也就显得更加缓慢。
Batch_size增大到一定程度,其确定的下降方向已经基本不再变化。
Batch_size过小的影响:
训练时不稳定,可能不收敛
精度可能更高。
batch size过小,花费时间多,同时梯度震荡严重,不利于收敛;batch size过大,不同batch的梯度方向没有任何变化,容易陷入局部极小值。
14.卷积的权重共享
在卷积神经网络中,权重共享简单来理解就是,输入一张图片,这张图片用一个卷积核进行卷积操作的时候,图片中的每一个位置都被同一个卷积核进行卷积,所以权重是一样的,也就是共享。
15.上采样
双线性插值(bilinear),反卷积(Transposed Convolution),反池化(Unpooling)
反卷积是一种特殊的正向卷积,先按照一定的比例通过补0来扩大输入图像的尺寸,接着旋转卷积核,再进行正向卷积。
反池化:在下采样的时候记录max的位置,上采样的时候最大值的位置还原,其它位置填0
16.CNN有什么特点和优势
CNN的使用范围是具有局部空间相关性的数据,比如图像、自然语言、语音。
局部连接(稀疏连接):可以提取局部特征
权值共享:减少参数数量,降低训练难度,避免过拟合,提升模型“平移不变性”
降维:通过池化或卷积stride实现
多层次结构:将低层次的局部特征组合成较高层次的特征,不同层级的特征可以对应不同任务
自动进行特征提取,无需手动设计特征
缺点: 池化层会丢失大量信息 ; 自动进行特征提取,也就造成了模型可解释性差,更类似一个黑盒 ;需要大批量数据进行训练
17.初始化方法有哪些?
全0初始化
随机初始化:将参数随机化,不过随机参数服从高斯分布或均匀分布.
Xavier初始化:随机初始化没有控制方差,所以对于深层网络而言,随机初始化方法依然可能失效。理想的参数初始化还得控制方差,对www进行一个规范化.“Xavier初始化”维持了输入输出数据分布方差一致性。
He初始化:为了解决“Xavier初始化”的缺点。对于非线性激活函数ReLU,“Xavier初始化”方法失效。He初始化基本思想是,当使用ReLU做为激活函数时,Xavier的效果不好,原因在于,当ReLU的输入小于0时,其输出为0,相当于该神经元被关闭了,影响了输出的分布模式。
在Xavier的基础上,假设每层网络有一半的神经元被关闭,于是其分布的方差也会变小。He初始化可以认为是Xavier初始 / 2的结果。
18.FPN的作用
高层特征向低层特征融合,增加低层特征表达能力,提升性能
不同尺度的目标可以分配到不同层预测,达到分而治之
19.BN层合并原理



20.0全连接层/卷积层的特点:
关注全局信息(每个点都和前后层的所有点链接) ;参数量巨大,计算耗时 ;输入维度需要匹配(因为是矩阵运算,维度不一致无法计算)
局部链接:当前层的神经元只和下一层神经元的局部链接(并不是全连接层的全局链接)
权重共享:神经元的参数(如上图的3*3卷积核),在整个特征图上都是共享的,而不是每个滑动窗口都不同
20.卷积神经网络和全连接网络的根本不同之处在哪里?
相同:无论是全连接层,还是卷积层,都是线性层,只能拟合线性函数,所以都需要通过ReLU等引入非线性,以增加模型的表达能力
不同/优点: 需要学习的参数更少,从而降低了过度拟合的可能性,因为该模型不如完全连接的网络复杂;只需要考虑中的上下文/共享信息。这个未来在许多应用中非常重要,例如图像、视频、文本和语音处理/挖掘,因为相邻输入(例如像素、帧、单词等)通常携带相关信息。 空间信息 没有利用像素之间的位置信息;网络层数限制(表现能力有限)。
21.过拟合:
过拟合(over-fitting)其实就是所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在验证数据集以及测试数据集中表现不佳 模型太复杂
过拟合:Dropout(随机失活)、Weight Decay(权重衰减)、减少模型参数、Early Stop、Regularization(正则化,包括L1,L2正则化等)、Augmentation(数据增强)、合成数据、Batch Normalization(批次标准化)、Bagging 和 Boosting(模型融合)等
22.调参
调参的时候也不能无章法的乱调,试试这个参数行不行,那个参数行不行,效率太低,调一次要跑很久才能出结果,也不一定能搜到好结果。
比较科学的方法是GridSearch,即网格搜索,在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。其原理就像是在数组里找最大值。
Ps:为什么叫网格搜索?以有两个参数的模型为例,参数a有3种可能,参数b有4种可能,把所有可能性列出来,可以表示成一个3*4的表格,其中每个cell就是一个网格,循环过程就像是在每个网格里遍历、搜索,所以叫grid search)
另外,调参还需要结合具体任务。
比如,我们想用通用目标检测网络FasterRCNN实现表格单元格的检测,那么就可以针对表格单元格的特点(通常是细长的长条),调整anchor ratio(即宽高比),提高模型效果。
23.BN、LN、IN、GN的区别
batchNorm是在batch上,对NHW做归一化,对小batchsize效果不好;
layerNorm在通道方向上,对CHW归一化,主要对RNN作用明显;
instanceNorm在图像像素上,对HW做归一化,用在风格化迁移;
GroupNorm将channel分组,然后再做归一化;
SwitchableNorm是将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用什么方法

24.transformer
爱者之贻:计算机视觉面试题-Transformer相关问题总结104 赞同 · 0 评论文章
25.学习率策略
warmup
26.Transformer同LSTM这些有什么区别
transformer和LSTM最大的区别就是LSTM的训练是迭代的,是一个接一下字的来,当前这个字过完LSTM单元,才可以进下一个字,而transformer的训练是并行了,就是所有字是全部同时训练的,这样就大大加快了计算效率,transformer使用了位置嵌入(positional encoding)来理解语言的顺序,使用自注意力机制和全连接层进行计算。
27.Encoder端和Decoder端是如何进行交互的?(在这里可以问一下关于seq2seq的attention知识)
Cross Self-Attention,Decoder提供Q,Encoder提供K,V
转载:神经网络基础理论-相关 - 知乎