R语言:商业数据分析实例(4)【总结篇,回归】
适用于有一定基础的初学者。内容为实战。
本章节的内容围绕客户需求延伸,具体方案因人而异。欢迎大家在评论区提出不同的方案。
使用到的数据:链接:https://pan.baidu.com/s/1yhzQSdquizLayXamM0wygg
提取码:3b7i
数据介绍:
用到的数据共4张表(cvs格式),为2003-2019年美国纽约市房地产交易数据。
- NYC_HISTORICAL包含:交易ID,社区ID,地址,建筑类型,时间,价格,面积等;
- BOROUGH包含:BOROUGH_ID和BOROUG名称;
- BUILDING_CLASS包含:建筑ID和建筑类型等;
- NEIGHBORHOOD 包含:街道ID和BOROUGH_ID等;
本案例需要根据ID整合数据,从中提取目标信息。
场景模拟:
雇主是一家房地产中介企业,现有在纽约市拓展业务的计划,但是不知道选择纽约市的哪个地区。故请来了数据分析师(你),给了上述4张表的数据,请你分析一下。
“数据就这些,帮我用回归什么的分析一下吧,帮我选几个能赚的多的地方”。雇主说道。
你有些紧张,雇主的说法模糊,让你不知如何下手。
开始分析前:
1. 快速的浏览数据。巧妇难为无米之炊,数据的内容和范围决定了你能做到的事情,也决定了你如何与雇主展开询问【不懂的地方(如变量含义)在一开始问清楚,中途再问只会暴露自己的不专业】。例如:
‘数据中有大量交易价格和面积为零的数据,请问这是?’
‘哦,经常会有房产转移这样的,比如父母给子女。你不用管就行’
2. 挖掘雇主的需求。很多时候,雇主自己都不知道一次分析能带来什么,也许就是随便看看。你需要帮助雇主找到他的需求,进而解决。不然很可能花费大力气分析了一堆,在雇主眼里不知所云毫无价值。
‘贵公司是想要在纽约市开设房产中介,故想选择一个区域,该区域最好交易多,是吗?’
‘对对,最好价格也高,因为中介费和交易价格挂钩。要单子多,且价格高’
......
经过严谨的询问,你知道了:这是一家房产中介公司,业务集中于住宅类型中介服务,包括买卖和租赁。【但是该数据没有租赁的数据,经过询问,你确定这次分析集中在买卖上,无需考虑租赁】因此,你的目标是,帮助雇主在纽约市选择一个,交易多,且价格高的地区。
3. 了解雇主的想法。很少有雇主两眼一抹黑就来找数据分析师,大部分都会带着心里有的方案,希望在分析师这得到确认。你需要了解雇主的想法,将其纳入你分析的考虑因素中。
例如:雇主在找你前,心中已经选定了几个合适的地区
你可以:‘纽约市很大,请问您现在有意向的几个地区吗’
回答A:‘我觉得...和...几个地方就不错,你帮我着重看一下’(那你在分析的时候,千万不能漏了)
回答B:‘现在还没有,你就帮我排一排最好的几个吧’(你可以放心的继续了)
开始筛选
导入,合并数据(在第一章节中讲过,不多赘述)
library(lubridate)
library(tidyverse)
library(forecast)
setwd("C:/Users/10098/Desktop/AD571/571,A34")
BOROUGH <- read.csv("BOROUGH.csv", header=TRUE)
BUILDING_CLASS <- read.csv("BUILDING_CLASS.csv", header=TRUE)
NEIGHBORHOOD <- read.csv("NEIGHBORHOOD.csv", header=TRUE)
NYC_HISTORICAL <- read_csv2("NYC_HISTORICAL.csv")
NYC_HISTORICAL <- mutate(NYC_HISTORICAL, Y = year(SALE_DATE), Q = quarter(SALE_DATE), D = date(SALE_DATE))
NEIGHBORHOOD <- left_join(NEIGHBORHOOD,BOROUGH, by = 'BOROUGH_ID') 按照雇主需求取出有效数据。
df <- NYC_HISTORICAL %>%
left_join(BUILDING_CLASS, by = c('BUILDING_CLASS_FINAL_ROLL' = 'BUILDING_CODE_ID')) %>%
left_join(NEIGHBORHOOD, by = 'NEIGHBORHOOD_ID') %>%
select(NEIGHBORHOOD_ID, YEAR_BUILT, SALE_PRICE, GROSS_SQUARE_FEET,TYPE,Y, Q) %>%
subset(SALE_PRICE != 0) %>% #按雇主需求筛除
subset(GROSS_SQUARE_FEET != 0) %>% #按雇主需求筛除
subset(Y>=2010) %>% #按雇主需求筛选大于10年的数据
filter(TYPE == 'RESIDENTIAL') %>% #按雇主选择住宅类型
na.omit() 可以先看一下近五年交易量最大的几个地区,有个数
df_5year <- df %>%
subset(Y>=2015) %>%
count(NEIGHBORHOOD_ID)
df_5year[order(df_5year[,"n"], decreasing = TRUE), ] #排序
再观察一下近五年每单交易的均价
df_5year_price <- df %>%
subset(Y>=2015) %>%
group_by(NEIGHBORHOOD_ID) %>%
summarize(mean(SALE_PRICE))
df_5year_price[order(df_5year_price[,"mean(SALE_PRICE)"], decreasing = TRUE), ]
综合考虑(方法应根据实际情况和雇主徐需求,这里使用最简单的相乘):
这里选出最好的前50名
df_all <- mutate(df_5year, df_5year_price)
df_all$product <- df_all$n * df_all$`mean(SALE_PRICE)`
top_50 <- head(df_all[order(df_all[,"product"], decreasing = TRUE), ], 50)到这一步,我们有了一个基本的范围:
综合价格和量两方面考虑,筛选了50个地区。那几个地区交易量大,那几个地区每单均价高。
接下进一步筛选(每一步的筛选标准应当根据雇主的侧重点进行设计):
这里用成长性,即预测未来8个季度的价格涨幅作为筛选标准。
方法为ets指数平滑法(在第三中已经介绍),使用循环放入50个地区,得到对应涨幅。
grow_box <- c()
for (x in top_50$NEIGHBORHOOD_ID) {
df_forecast <- df %>%
subset(NEIGHBORHOOD_ID == x) %>%
group_by( Y, Q) %>%
summarise(sum(SALE_PRICE))
ts_data <- ts(df_forecast[,3], start=2010, end=c(2019, 4), frequency=4)
model <- ets(y = ts_data, model = 'ZZZ')
fit <- predict(model, 8)
df_8Q <- data.frame(fit$mean)
growth_rate <- (df_8Q[8, ] - df_forecast[40, 3]) / df_forecast[40, 3]
grow_box <- append(grow_box, growth_rate$`sum(SALE_PRICE)`)
}
df_grow <- data.frame(top_50$NEIGHBORHOOD_ID, grow_box)
top_10 <- head(df_grow[order(df_grow[,2], decreasing = TRUE), ] , 10) #排序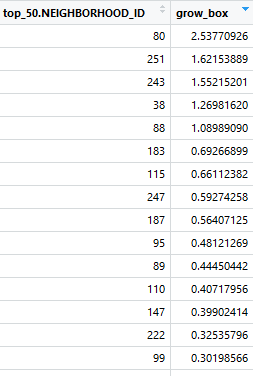
现在我们做了进一步的筛选,得到了top10。【处理的时候有空值,是因为有些地区某些季度没有交易,针对这些地区以年为单位做指数平滑法预测,操作相似,在此不赘述】
(如果客户有意向的区域,记得加入这份列表中)
进一步分析
到这里,我们已经顺利的利用“价格”,“销售量”,“增长”三个指标筛选出了top10。
但显然还不够,因为我只分析了共性的指标,而每个区域都具有不同的特征,我们需要向客户提供这些信息,供其决策。
根据数据,我们可以得到的特征有:季节性 + 房屋年龄
(特征是否有价值应当由客户判断,你应当尽量的可能有用的特征提取和展现)
这里利用回归,根据经济学的基本知识和已有数据,可知
交易价格 ~ 去年的整体价格 + 交易面积 + 房屋年龄 + 季节
【隐含假设:
- 售房者会根据去年的该地区房屋售价定价
- 交易面积越大,交易价格越高
- 房屋越老,价格越低
- 季节影响交易 】
整理数据,得到房屋年龄,地区每平方米均价
df$YEAR_BUILT <- df$Y - df$YEAR_BUILT #得到age
df$Price_per_square <- df$SALE_PRICE / df$GROSS_SQUARE_FEET
Local_Average <- df %>%
group_by(NEIGHBORHOOD_ID, Y) %>%
summarise(mean(Price_per_square)) #得到地区每平方米均价
Local_Average$Y <- Local_Average$Y + 1 #滞后一年
df <- left_join(df, Local_Average, by = c('NEIGHBORHOOD_ID', 'Y'))
names(df) <- c('ID', 'Age', 'Price', 'Feet', 'Type', 'Year', 'Quarter', 'Price_per_square', 'Local_Average')选则top10中的地区逐个研究(这里只演示ID:80),并把季节变为因子(为了回归)
panel_df <- df%>%
filter(ID == 80)
panel_df$Quarter <- factor(panel_df$Quarter)
regression_model <- lm(Price ~ Local_Average + Feet + Age + Quarter , data = panel_df)
summary(regression_model)
回归结果如下:
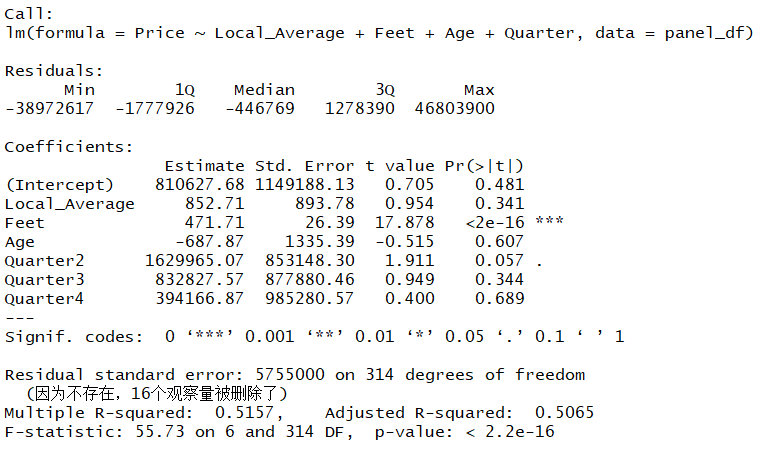
解释:
- local_average不显著在意料之内,因为地区中不同房屋售价差异也大,此处作为控制变量
- feet显著符合直觉
- age不显著也在意料之中,因为不知道是否翻新,可以考虑删去
- 季节不显著没有关系,因为售房租房有季节性是确定的,我们只要系数即可
- 被删除的观察量是因为我们做了滞后,会有损失
现在,我们将10个地区全部回归,将季节波动提取出来
results_box <- c()
for (x in top_10$top_50.NEIGHBORHOOD_ID) {
panel_df <- df%>%
filter(ID == x)
panel_df$Quarter <- factor(panel_df$Quarter)
# Fixed effects using Least squares dummy variable model
regression_model <- lm(Price ~ Local_Average + Feet + Quarter , data = panel_df)
result <- summary(regression_model)
results_box <- append(results_box, result$coefficients[c(4,5,6)])
}
coefficients <- data.frame(t(array(results_box, dim = c(3, 10))))整理平均房龄(上面回归用的是交易个体的房龄,因此这里再整理一次地区平均的)
将top50获得的 '近五年销售量' , '近五年销售价格', '价量综合指数'(就是乘积),整理的平均房龄,以及回归得到的季节波动全部整合到top10,得到最后的数据框。
df_age <- data.frame(df$ID,df$Age)
df_average_age <- df_age %>%
group_by(df.ID) %>%
summarise(mean(df.Age))
df_final <- top_10 %>%
left_join(top_50, by = c('top_50.NEIGHBORHOOD_ID' = 'NEIGHBORHOOD_ID')) %>%
left_join(df_average_age, by = c('top_50.NEIGHBORHOOD_ID' = 'df.ID') ) %>%
mutate(coefficients)
names(df_final) <- c('ID','增长率', '近五年销售量' , '近五年销售价格',
'价量综合指数', '平均房龄', 'Q2波动', 'Q3波动', 'Q4波动')最终的效果:
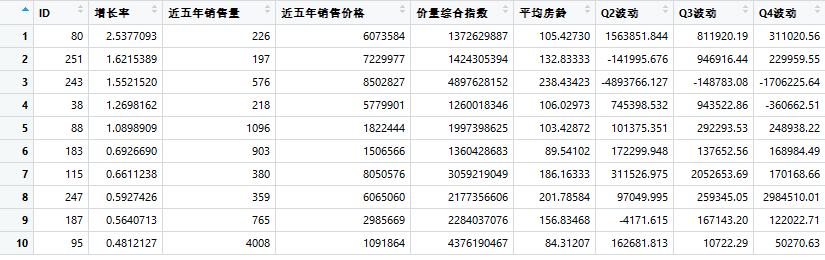
你成功的帮助客户筛选了10个地区。客户不希望地区房龄太老,筛除了ID243,115,247。也不希望季节波动过大,筛除了ID243,95。客户将在剩下的6个地区重点寻找合适的门店,并且非常感谢你的分析。
大功告成!
案例源于波士顿大学,感谢教授Tara Kelly
后记:
价量综合指数和增长率是我们筛选的最重要指标,实际情况可能更加复杂,如“竞争者数量”,“开设门店成本”等。每一步操作都对分析师有着极高的经济学知识要求和技术要求,本文内容相对于实践来说微不足道,甚至一些地方的分析略有偏颇。希望各位同行前辈多多指点,共勉。